
一、Git
- 集中式版本控制系统,版本库是集中存放在中央服务器的(服务器必须联网才能连接)。所有人都是通过中央服务器来交换修改。
- 分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库。两个人的电脑之间可以相互推送修改。不过, 在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
- 所有的版本控制系统,其实只能跟踪文本文件的改动,比如TXT文件,网页,所有的程序代码等等。 而图片、视频这些二进制文件,虽然也能由版本控制系统管理,但没法跟踪文件的变化,只能把二进制文件每次改动串起来,也就是只知道图片从100KB改成了120KB。(Microsoft的Word格式是二进制格式)。
- 文本是有编码的,比如中文有常用的GBK编码,日文有Shift_JIS编码,如果没有历史遗留问题,强烈建议使用标准的UTF-8编码,所有语言使用同一种编码,既没有冲突,又被所有平台所支持。
二、Git的安装
首先,试着输入git,看看系统有没有安装Git。
Mac OS X上安装Git:
2.1 通过homebrew安装
引用官方的一句话:Homebrew是Mac OS 不可或缺的套件管理器。
Homebrew是一款Mac OS平台下的软件包管理工具,拥有安装、卸载、更新、查看、搜索等很多实用的功能。简单的一条指令,就可以实现包管理,而不用你关心各种依赖和文件路径的情况,十分方便快捷。
安装homebrew,然后通过homebrew安装Git。
2.2 通过Command Line Tools安装
安装Xcode IDE附带的命令行工具—Command Line Tools(需要自己安装 xcode-select--install )
Command Line Tools就是一个小型独立包,为mac终端用户提供了许多常用的命令行工具(实用程序、编译器等)。包括svn,git,make,GCC,clang,perl,size,strip,strings,libtool,cpp,what以及其他很多能够在Linux默认安装中找到的有用的命令。
安装目录: /Library/Developer/CommandLineTools/
三、Git的配置
3.1 配置远程仓库
常见的本地、远程仓库几种模式:
从零开发,那么最好的方式是先创建远程库,然后,从远程库克隆。
在GitHub上,可以任意Fork开源仓库(点“Fork”就在自己的账号下克隆了一个bootstrap仓库,然后,从自己的账号下clone)
- 自己拥有Fork后的仓库的读写权限;
- 可以推送pull request给官方仓库来贡献代码( 当然,对方是否接受你的pull request就不一定了 )。
将已存在的文件夹,变成 Git 仓库,并创建关联的远程仓库:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21cd 本地文件夹名称
# 把这个目录变成Git可以管理的仓库 ,会多一个.git的目录,是Git来跟踪管理版本库的,如非必要不要手动修改这个目录里面的文件,不然改乱了,就把Git仓库给破坏了。
git init
# 添加远程库
# <remote-url>: 远程库的地址。
# <remote-name>: 远程库的名字是可以随便取的,不过强烈建议使用Git默认远程库名称【origin】,一看就知道是远程库。之后我们就可以在命令中使用<remote-name>代指项目远程库地址。
git remote add <remote-name> <remote-url(ssh/https)>
# 添加成功后,可以在项目根目录/.git/config文件中看到
# [remote "origin"]
# url = git@gitlab.100credit.cn:dingfangchao/Banyan.git
# 一个本地仓库是可以关联多个远程库的,多次执行上面命令即可,但不能重名
# 查看远程库信息(如果没有推送权限,就不会看到push的地址)
git remote [-v/--verbose]
# 删除已有的远程库
git remote rm <remoteName>
# 把本地的master分支内容推送的远程新的master分支,并建立本地master与远程仓库的master分支的关联,详见git push命令
git push -u <remote-name> master
3.2 配置忽略文件
3.2.1 全局与局部忽略
有些时候,你必须把某些文件放到Git工作目录中,但又不能提交它们,比如保存了数据库密码的配置文件啦。
此时,可以把要忽略的文件名填入忽略文件,Git就会自动忽略这些文件。可以定义忽略是全局的,还是局限于一个仓库。
- 全局忽略文件:
/User/用户名/.gitignore_global; - 仓库忽略文件:Git工作区的根目录下有一个特殊的
.gitignore文件。
3.2.2 忽略文件的编写
忽略文件的格式:
- 注释格式同shell脚本: #注释;
- 忽略精确的文件名:文件名;
- 忽略所有此扩展名的文件:如 *.pbxuser 表示要忽略后缀名为.pbxuser的文件;
- 忽略文件夹下面的一切:如 build/ 表示要忽略 build 文件夹下的所有内容;
*表示通配符:如fastlane/screenshots/**/*.png;!表示取反:如 *.pbxuser 表示忽略所有后缀名为.pbxuser的文件,如果加上!default.pbxuser则表示,除了default.pbxuse忽略其它后缀名为pbxuse的文件。
忽略文件的原则是:
- 忽略操作系统自动生成的文件,比如缩略图等;
- 忽略编译生成的中间文件、可执行文件等,也就是如果一个文件是通过另一个文件自动生成的,那自动生成的文件就没必要放进版本库,比如Java编译产生的.class文件;
- 忽略你自己的带有敏感信息的配置文件,比如存放口令的配置文件,比如IDE的一些个人偏好设置。
不需要从头写.gitignore文件,github/gitignore 已经为我们准备了各种配置文件,只需要组合一下就可以使用了。
如 iOS 项目忽略文件的几项配置:
1 | ## User settings |
3.2.3 忽略文件的检查
有些时候,你想添加一个文件到Git,但发现添加不了,原因是这个文件被.gitignore忽略了:The following paths are ignored by one of your .gitignore files,可以使用git add -f <file>强制添加。
或者你发现,可能是.gitignore写得有问题,需要找出来到底哪个规则写错了,可以用git check-ignore -v <file>命令检查, Git会告诉我们,.gitignore的第几行规则忽略了该文件。
3.2.4 只能作用于 Untracked Files!
.gitignore 文件只能作用于 Untracked Files,也就是那些从来没有被 Git 记录过的文件(自添加以后,从未 add 及 commit 过的文件)。
也就是说ignore规则只对那些在规则建立之后被新创建的新文件生效。
那么如何使.gitignore文件的规则对于那些已经被track的文件生效呢?正确的做法应该是
git rm --cached logs/xx.log- 更新
.gitignore忽略掉目标文件 git add . && git commit -m "We really don't want Git to track this anymore!"
git rm --cached 删除的是追踪状态,而不是物理文件;如果你真的是彻底不想要了,你也可以直接 rm+忽略+提交。
3.3 git config配置
3.3.1 三种优先级的配置
1 | git config [--global | --system] <oo>.<kk> <vv> |
Git 自带一个 git config 的工具来帮助设置控制 Git 外观和行为的配置变量。 这些变量存储在三个不同的位置:
/etc/gitconfig:包含系统上每一个用户及他们仓库的通用配置,使用带有--system选项的git config时,会从此文件读写配置变量;~/.gitconfig或~/.config/git/config:只针对当前用户。 可以传递--global选项让 Git 读写此文件。- 仓库目录下
/.git/config:只针对该仓库,在仓库中使用带有--local(默认) 选项的git config时,会读写该文件;
在优先级方面,从上往下依次上升。
git config 的配置项有很多,详细可以看 git文档。下面只是列出常见的几种。
3.3.2 配置用户信息
当安装完 Git 应该做的第一件事就是设置你的用户名称与邮件地址。
1 | # 上面已经说过,用了--global参数表示这台机器上所有的Git仓库都会使用这个配置,当然也可以对某个仓库指定不同的用户名和Email地址 |
用户名和邮箱地址的作用:
- 每一个 Git 的提交都会使用这些信息,并且它会写入到你的每一次提交中,不可更改;
- github 的 contributions 统计就是按邮箱来统计的。
- 注意:name、email是不用作git权限校验的,只为commit时做记录,随便怎么改都行。
亲证:误操作,用了一个全局配置的git name/email(公司的)用户名和邮箱,成功推送到了我的私人仓库
很多 GUI 工具都会在第一次运行时帮助你配置这些信息。
3.3.3 配置文本编辑器
当 Git 需要你输入信息时会调用它。 如果未配置,Git 会使用操作系统默认的文本编辑器,通常是 Vim。 如果你想使用不同的文本编辑器,例如 Emacs,可以这样做:
1 | git config --global core.editor emacs |
Vim 和 Emacs 是像 Linux 与 Mac 等基于 Unix 的系统上开发者经常使用的流行的文本编辑器。 如果你对这些编辑器都不是很了解或者你使用的是 Windows 系统,那么可能需要搜索如何在 Git 中配置你最常用的编辑器。 如果你不设置编辑器并且不知道 Vim 或 Emacs 是什么,当它们运行起来后你可能会被弄糊涂、不知所措。
3.3.4 配置Git别名
别名可以使你的 Git 体验更简单、容易、熟悉。
Git 并不会在你输入部分命令时自动推断出你想要的命令。 如果不想每次都输入完整的 Git 命令,可以通过 git config 文件来轻松地为每一个命令设置一个别名。
1 | git config --global alias.st status |
可以看出,Git 只是简单地将别名替换为对应的命令。 然而,你可能想要执行外部命令,而不是一个 Git 子命令。 如果是那样的话,可以在命令前面加入 ! 符号。 如果你自己要写一些与 Git 仓库协作的工具的话,那会很有用。 我们现在演示将 git visual 定义为 gitk 的别名:
1 | git config --global alias.visual '!gitk' |
3.3.5 配置权限校验缓存
如果你正在使用 HTTPS URL 来推送,Git 服务器会询问用户名与密码。 默认情况下它会在终端中提示服务器是否允许你进行推送。
如果不想在每一次推送时都输入用户名与密码,你可以设置一个 “credential cache”。 最简单的方式就是将其保存在内存中几分钟,可以简单地运行 git config --global credential.helper cache 来设置它。
了解更多关于不同验证缓存的可用选项,查看 凭证存储。
3.3.6 配置Git的着色
Git 充分支持对终端内容着色,对你凭肉眼简单、快速分析命令输出有很大帮助。
Git 会自动着色大部分输出内容,但如果你不喜欢花花绿绿,也可以关掉。 要想关掉 Git 的终端颜色输出,试一下这个:
1 | git config --global color.ui false |
这个设置的默认值是 auto,它会着色直接输出到终端的内容;而当内容被重定向到一个管道或文件时,则忽略着色功能。
你也可以设置成 always,来忽略掉管道和终端的不同,即在任何情况下着色输出。 你很少会这么设置,在大多数场合下,如果你想在被重定向的输出中插入颜色码,可以传递 --color 标志给 Git 命令来强制它这么做。 默认设置就已经能满足大多数情况下的需求了。
要想具体到哪些命令输出需要被着色以及怎样着色,你需要用到和具体命令有关的颜色配置选项。 它们都能被置为 true、false 或 always:
1 | color.branch |
另外,以上每个配置项都有子选项,它们可以被用来覆盖其父设置,以达到为输出的各个部分着色的目的。 例如,为了让 diff 的输出信息以蓝色前景、黑色背景和粗体显示,你可以运行
1 | git config --global color.diff.meta "blue black bold" |
你能设置的颜色有:normal、black、red、green、yellow、blue、magenta、cyan 或 white。 正如以上例子设置的粗体属性,想要设置字体属性的话,可以选择包括:bold、dim、ul(下划线)、blink、reverse(交换前景色和背景色)。
3.3.7 查看配置信息
如果想要检查你的配置,可以使用 git config --list 命令来列出所有 Git 当时能找到的配置。
1 | $ git config --list |
你可能会看到重复的变量名,因为 Git 会从不同的文件中读取同一个配置(例如:/etc/gitconfig 与 ~/.gitconfig)。 这种情况下,Git 会使用它找到的每一个变量的最后一个配置。
你可以通过输入 git config <key>: 来检查 Git 的某一项配置
1 | $ git config user.name |
四、服务器上的Git
4.1 Git 的四种传输协议
Git 可以使用四种主要的协议来传输资料:本地协议(Local),HTTP 协议,SSH(Secure Shell)协议及 Git 协议。
4.1.1 哑协议与智能协议之分
原文链接 Git 可以通过两种主要的方式在版本库之间传输数据:“哑(dumb)”协议和“智能(smart)”协议。
如果你正在架设一个基于 HTTP 协议的只读版本库,一般而言这种情况下使用的就是哑协议。 这个协议之所以被称为“哑”协议,是因为在传输过程中,服务端不需要有针对 Git 特有的代码;抓取过程是一系列 HTTP 的 GET 请求,这种情况下,客户端可以推断出服务端 Git 仓库的布局。
现在已经很少使用哑协议了。 使用哑协议的版本库很难保证安全性和私有化,所以大多数 Git 服务器宿主(包括云端和本地)都会拒绝使用它。 一般情况下都建议使用智能协议。
哑协议虽然很简单但效率略低,且它不能从客户端向服务端发送数据。 智能协议是更常用的传送数据的方法,但它需要在服务端运行一个进程,而这也是 Git 的智能之处——它可以读取本地数据,理解客户端有什么和需要什么,并为它生成合适的包文件。 总共有两组进程用于传输数据,它们分别负责上传和下载数据。
- 为了上传数据至远端,Git 使用
send-pack和receive-pack进程。 运行在客户端上的send-pack进程连接到远端运行的receive-pack进程。 - 当你在下载数据时,
fetch-pack和upload-pack进程就起作用了。 客户端启动fetch-pack进程,连接至远端的upload-pack进程,以协商后续传输的数据。
4.1.2 本地协议
最基本的就是 本地协议(Local protocol) ,其中的远程版本库就是硬盘内的另一个目录。 这常见于团队每一个成员都对一个共享的文件系统(例如一个挂载的 NFS)拥有访问权,或者比较少见的多人共用同一台电脑的情况。 后者并不理想,因为你的所有代码版本库如果长存于同一台电脑,更可能发生灾难性的损失。
如果你使用共享文件系统,就可以从本地版本库克隆(clone)、推送(push)以及拉取(pull)。 像这样去克隆一个版本库或者增加一个远程到现有的项目中,使用版本库路径作为 URL。 例如,克隆一个本地版本库,可以执行如下的命令:
1 | git clone /opt/git/project.git |
或你可以执行这个命令:
1 | git clone file:///opt/git/project.git |
如果在 URL 开头明确的指定 file://,那么 Git 的行为会略有不同。 如果仅是指定路径,Git 会尝试使用硬链接(hard link)或直接复制所需要的文件。 如果指定 file://,Git 会触发平时用于网路传输资料的进程,那通常是传输效率较低的方法。 指定 file:// 的主要目的是取得一个没有外部参考(extraneous references)或对象(object)的干净版本库副本– 通常是在从其他版本控制系统导入后或一些类似情况(参见 Git 内部原理 for maintenance tasks)需要这么做。 在此我们将使用普通路径,因为这样通常更快。
4.1.3 SSH 协议
架设 Git 服务器时常用 SSH 协议作为传输协议。 因为大多数环境下已经支持通过 SSH 访问 —— 即时没有也比较很容易架设。 SSH 协议也是一个验证授权的网络协议;并且,因为其普遍性,架设和使用都很容易。
通过 SSH 协议克隆版本库,你可以指定一个 ssh:// 的 URL:
1 | git clone ssh://user@server/project.git |
或者使用一个简短的 scp 式的写法:
1 | git clone user@server:project.git |
你也可以不指定用户,Git 会使用当前登录的用户名。
1. 优势
用 SSH 协议的优势有很多。 首先,SSH 架设相对简单 —— SSH 守护进程很常见,多数管理员都有使用经验,并且多数操作系统都包含了它及相关的管理工具。 其次,通过 SSH 访问是安全的 —— 所有传输数据都要经过授权和加密。 最后,与 HTTP/S 协议、Git 协议及本地协议一样,SSH 协议很高效,在传输前也会尽量压缩数据。
2. 缺点
SSH 协议的缺点在于你不能通过他实现匿名访问。 即便只要读取数据,使用者也要有通过 SSH 访问你的主机的权限,这使得 SSH 协议不利于开源的项目。 如果你只在公司网络使用,SSH 协议可能是你唯一要用到的协议。 如果你要同时提供匿名只读访问和 SSH 协议,那么你除了为自己推送架设 SSH 服务以外,还得架设一个可以让其他人访问的服务。
4.1.4 Git 协议
接下来是 Git 协议。 这是包含在 Git 里的一个特殊的守护进程;它监听在一个特定的端口(9418),类似于 SSH 服务,但是访问无需任何授权。 要让版本库支持 Git 协议,需要先创建一个 git-daemon-export-ok 文件 —— 它是 Git 协议守护进程为这个版本库提供服务的必要条件 —— 但是除此之外没有任何安全措施。 要么谁都可以克隆这个版本库,要么谁也不能。 这意味着,通常不能通过 Git 协议推送。 由于没有授权机制,一旦你开放推送操作,意味着网络上知道这个项目 URL 的人都可以向项目推送数据。 不用说,极少会有人这么做。
1. 优点
目前,Git 协议是 Git 使用的网络传输协议里最快的。 如果你的项目有很大的访问量,或者你的项目很庞大并且不需要为写进行用户授权,架设 Git 守护进程来提供服务是不错的选择。 它使用与 SSH 相同的数据传输机制,但是省去了加密和授权的开销。
2. 缺点
Git 协议缺点是缺乏授权机制。 把 Git 协议作为访问项目版本库的唯一手段是不可取的。 一般的做法里,会同时提供 SSH 或者 HTTPS 协议的访问服务,只让少数几个开发者有推送(写)权限,其他人通过 git:// 访问只有读权限。 Git 协议也许也是最难架设的。 它要求有自己的守护进程,这就要配置 xinetd 或者其他的程序,这些工作并不简单。 它还要求防火墙开放 9418 端口,但是企业防火墙一般不会开放这个非标准端口。 而大型的企业防火墙通常会封锁这个端口。
4.1.5 HTTP 协议
Git 通过 HTTP 通信有两种模式。 在 Git 1.6.6 版本之前只有一个方式可用,十分简单并且通常是只读模式的。 Git 1.6.6 版本引入了一种新的、更智能的协议,让 Git 可以像通过 SSH 那样智能的协商和传输数据。 之后几年,这个新的 HTTP 协议因为其简单、智能变的十分流行。 新版本的 HTTP 协议一般被称为“智能” HTTP 协议,旧版本的一般被称为“哑” HTTP 协议。 我们先了解一下新的“智能” HTTP 协议。
1. 智能(Smart) HTTP 协议
Smart HTTP:我们一般通过 SSH 进行授权访问,通过 git:// 进行无授权访问,但是还有一种协议可以同时实现以上两种方式的访问。 设置 Smart HTTP 一般只需要在服务器上启用一个 Git 自带的名为 git-http-backend 的 CGI 脚本。 该 CGI 脚本将会读取由 git fetch 或 git push 命令向 HTTP URL 发送的请求路径和头部信息,来判断该客户端是否支持 HTTP 通信(不低于 1.6.6 版本的客户端支持此特性)。 如果 CGI 发现该客户端支持智能(Smart)模式,它将会以智能模式与它进行通信,否则它将会回落到哑(Dumb)模式下(因此它可以对某些老的客户端实现向下兼容)。
“智能” HTTP 协议的运行方式和 SSH 及 Git 协议类似,只是运行在标准的 HTTP/S 端口上并且可以使用各种 HTTP 验证机制,这意味着使用起来会比 SSH 协议简单的多,比如可以使用 HTTP 协议的用户名/密码的基础授权,免去设置 SSH 公钥。
智能 HTTP 协议或许已经是最流行的使用 Git 的方式了,它即支持像 git:// 协议一样设置匿名服务,也可以像 SSH 协议一样提供传输时的授权和加密。 而且只用一个 URL 就可以都做到,省去了为不同的需求设置不同的 URL。 如果你要推送到一个需要授权的服务器上(一般来讲都需要),服务器会提示你输入用户名和密码。 从服务器获取数据时也一样。
事实上,类似 GitHub 的服务,你在网页上看到的 URL (比如, https://github.com/schacon/simplegit[]),和你在克隆、推送(如果你有权限)时使用的是一样的。
2. 哑(Dumb) HTTP 协议
如果服务器没有提供智能 HTTP 协议的服务,Git 客户端会尝试使用更简单的“哑” HTTP 协议。 哑 HTTP 协议里 web 服务器仅把裸版本库当作普通文件来对待,提供文件服务。 哑 HTTP 协议的优美之处在于设置起来简单。 基本上,只需要把一个裸版本库放在 HTTP 根目录,设置一个叫做 post-update 的挂钩就可以了(见 Git 钩子)。 此时,只要能访问 web 服务器上你的版本库,就可以克隆你的版本库。
通常的,会在可以提供读/写的智能 HTTP 服务和简单的只读的哑 HTTP 服务之间选一个。 极少会将二者混合提供服务。
3. 优点
我们将只关注智能 HTTP 协议的优点。
不同的访问方式只需要一个 URL 以及服务器只在需要授权时提示输入授权信息,这两个简便性让终端用户使用 Git 变得非常简单。 相比 SSH 协议,可以使用用户名/密码授权是一个很大的优势,这样用户就不必须在使用 Git 之前先在本地生成 SSH 密钥对再把公钥上传到服务器。 对非资深的使用者,或者系统上缺少 SSH 相关程序的使用者,HTTP 协议的可用性是主要的优势。 与 SSH 协议类似,HTTP 协议也非常快和高效。
你也可以在 HTTPS 协议上提供只读版本库的服务,如此你在传输数据的时候就可以加密数据;或者,你甚至可以让客户端使用指定的 SSL 证书。
另一个好处是 HTTP/S 协议被广泛使用,一般的企业防火墙都会允许这些端口的数据通过。
4. 缺点
在一些服务器上,架设 HTTP/S 协议的服务端会比 SSH 协议的棘手一些。 除了这一点,用其他协议提供 Git 服务与 “智能” HTTP 协议相比就几乎没有优势了。
如果你在 HTTP 上使用需授权的推送,管理凭证会比使用 SSH 密钥认证麻烦一些。 然而,你可以选择使用凭证存储工具,比如 OSX 的 Keychain 或者 Windows 的凭证管理器。 参考 凭证存储 如何安全地保存 HTTP 密码。
4.2 搭建Git服务器
搭建Git服务器非常简单,通常10分钟即可完成;
参考链接:搭建Git服务器
4.3 error:hung up unexpectedly
使用场景:clone、push的时候报错The remote end hung up unexpectedly时
- git
config http.postBuffer 524288000(stackOverFlow上有人说好像对SSH协议报这个错时也有效) - 也可能是:接口不通(Git默认端口22,可能运维改了),或者网络不好
- 可以试试,具体还是以
“error: ...信息”为准( 如果改了postBuffer,问题解决之后,建议改回去 )
我当时因为传输了大量大文件,修改了http.postBuffer没用;
还有说修改http.lowSpeedLimit=0、http.lowSpeedTime=999999;设置允许的最低速度,最低速度时间(没试,我是SSH协议push的!)
修改了SSH的重连ServerAliveInterval=30、ServerAliveCountMax=5没用;
后来无奈,只能分批次上传。
4.3.1 配置http.postBuffer
Maximum size in bytes of the buffer used by smart HTTP transports when POSTing data to the remote system. For requests larger than this buffer size, HTTP/1.1 and Transfer-Encoding: chunked is used to avoid creating a massive pack file locally. Default is 1 MiB, which is sufficient for most requests.
Note that raising this limit is only effective for disabling chunked transfer encoding and therefore should be used only where the remote server or a proxy only supports HTTP/1.0 or is noncompliant with the HTTP standard. Raising this is not, in general, an effective solution for most push problems, but can increase memory consumption significantly since the entire buffer is allocated even for small pushes.
个人认为:这个参数是用来设置HTTP传输发送buffer池的大小(池子满了,或者数据已写入完毕就发送)
- 客户端、服务端会根据这个参数来申请内存当做buffer池(所以如果太大了,会消耗内存,而且如果块太大,并不是所有的服务器系统都能正常接收处理的)
- 客户端推送的大小如果超过这个可能会失败(至于说是本地发送失败,还是因为服务端根据这个设置的接收buffer池大小,结果接收到的数据太大,缓冲区溢出造成的失败就不清楚了)
- 服务端应答的大小如果超过这个会分块传输
- 仅对禁用分块传输编码有效(因此仅在远程服务器或代理仅支持HTTP/1.0或不符合HTTP标准的情况下才应使用),意思是分块传输编码时,有自己的分块传输(块多大)策略,而且优先级更高
服务端程序在接收客户端表单提交的数据时,需要先将数据存储到一个内存空间,然后做解析等后续工作,这个内存空间一般称之为接收缓冲区。对于post数据因为有Content-Length标记,服务端可以按标记的长度创建一个等于或稍大于提交数据的缓冲区;对于get,因为事先不知道提交的数据有多少,需要估计缓冲区长度,如果缓冲区很大而接收数据很小会造成内存浪费,而如果缓冲区小于接收数据,就可能造成缓冲区溢出。
“聪明的”黑客,会在溢出部分放置特殊的代码来攻陷你的服务器。博客
4.3.2 补充:Transfer-Encoding:chunked
表示输出的内容长度不能确定, 通常,HTTP应答消息中发送的数据是整个发送的,Content-Length消息头字段表示数据的长度, 先把整个要输出的数据写到一个很大的字节数组里(如 ByteArrayOutputStream),然后得到数组大小 -> Content-Length。
如果结合Transfer-Encoding: chunked使用,就不必申请一个很大的字节数组了,可以一块一块的输出,更科学,占用资源更少。 这在http协议中也是个常见的字段,用于http传送过程的分块技术,原因是http服务器响应的报文长度经常是不可预测的,使用Content-length的实体搜捕并不是总是管用。
五、Git的两种鉴权方式
HTTPS URLs和SSH URLs对应的是两套完全独立的权限校验方式,主要的区别就是:
- 前者采用账号密码进行校验;
- 后者采用SSH秘钥对进行校验。
5.1 SSH
只要选择正确的密钥,本地的私钥加密,对应的远程仓库账号中事先添加的公钥能解开就能提交成功。
生成公钥时,需要指定GitHub的邮箱地址,配置在GitHub中的公钥串中也包含邮箱,GitHub是校验的这个邮箱账号。
5.1.1 ssh-agent
ssh-agent是一种控制用来保存公钥身份验证所使用的私钥的程序,其实ssh-agent就是一个密钥管理器,运行ssh-agent以后,使用ssh-add将私钥交给ssh-agent保管,其他程序需要身份验证的时候可以将验证申请交给ssh-agent来完成整个认证过程。参考链接:了解ssh代理:ssh-agent。
个人理解: 类似VPN代理软件吧,会拦截我们的请求并针对性地加以处理。还有一点相同的是: 将私钥加入ssh-agent后,即使删除私钥文件,本地计算机仍可以正常访问 GitHub 代码仓库。
5.1.2 修改SSH默认端口
为了安全起见,有时会修改服务器ssh连接端口,比如改为3222。此时我们需要在 /etc/ssh/ssh_config 或者 ~/.ssh/config 中找到行 port 22 并修改(像这种配置文件最好使用vim编辑器)。
5.2 HTTPS
https 除了速度慢以外,还有个最大的麻烦是每次与远程仓库交互时,都必须输入账号(可以是git用户名,也可以是邮箱地址)、口令进行校验。
可以记住密码:
- Mac中可以存储在keychain中,在开启Keychain机制的情况下,进行权限校验后会自动将账号密码保存至Keychain Access。
- Mac、Windows共用—— git 提供的 credential helper机制:可以将账号密码以 cache 的形式在内存中缓存一段时间(默认 15 分钟),或者以文件的形式存储起来(~/.git-credentials)。
5.3 配置不同账号访问不同仓库
当一台计算机中需要以不同账号访问不同的仓库时:
- SSH:如果不同的仓库配置了不同的公钥,那么在使用本地私钥时,就要加以区分。(当然也可以所有仓库都使用一套公钥、私钥,理论上私钥只有自己知道)。
- HTTPS:如果不记住账号密码,即每次都输入账号密码,那就不需要配置。
- 如果使用Keychain记住了密码,此时会根据仓库的 host 去 Keychain 中寻找账户密码,因为 Keychain 中针对这个host 存储了多个账号、密码,那找出的可能是错误的,此时就会权限校验失败。此时我们需要处理一下我们的仓库URL。
5.3.1 SSH的处理
以SSH方式:通过远程仓库的url(clone之后存储在 repo/.git/config 中)的host
- 找到host配置的对应SSH-Key(SSH-Key一般都存在
~/.ssh文件夹中)- 当只有一个SSH账号时,
/etc/ssh/ssh_config配置文件,默认直接指向~/.ssh/id_rsa。 - 当有多个SSH账号时,
~/.ssh/config配置文件中,分别配置每个host对应的~/.ssh中的SSH-Key。
- 当只有一个SSH账号时,
- 通过密钥进行权限校验
两个文件的影响范围:
/etc/ssh/ssh_config下的配置是针对当前系统所有用户~/.ssh/config(/User/用户名/.ssh/config)只针对当前用户(默认是没有该文件的,只有当有多个用户,需要做映射时,才创建、配置)
如果两个仓库host不相同:
1 | # gitlab |
如果两个仓库host也相同,则需要在Host中进行区分,然后经过 CNAME 映射到 HostName(Host相当于是HostName的别名),然后分别指向不同的SSH-key,即IdentityFile,从而实现了对两个 GitHub 账号的分离。(HostName才是真正指定 GitHub 服务器主机的字段)
在config文件修改如下:
1 | # debugtalk |
此处改了还没完,还需要在各个项目中分别进行修改配置:代码提交、拉取时远程仓库的地址。 即repo/.git/config文件:可以用下面的命令:
1 | # 将原先的远程仓库的URL git@github.com:debugtalk/DroidMeter.git中的host改成我们刚设置的host(别名) |
5.3.2 HTTPS的处理
以HTTPS方式:通过远程仓库的url(clone之后存储在repo/.git/config中)。
比如:本来的HTTPS URL为 https://github.com/loten/RSAHandle.git 手动改为:https://loten@github.com/loten/RSAHandle.git。
注意:loten是GitHub的用户名,不能打错。在第一次拉取/推送的时候(钥匙串keychain中还没存储账号、密码),会要求输入该用户名对应的密码:Password Required For user Roten8 on host github.com. 输入成功后,即可成功拉取/推送。
配置原理很容易理解,即将 GitHub 用户名添加到仓库的 Git 地址中,这样在执行 git 命令的时候,系统就会采用指定的 GitHub 用户名去Keychain 或 ~/.git-credentials 中寻找对应的认证信息,账号使用错乱的问题也就不复存在了。
然后可以发现使用这种方式修改之后,可以看到keychain中的存储信息的账号:由邮箱号变为了Git用户名。即不再仅仅通过host来寻找账号密码,而是找到keychain中,这个host下指定的用户名对应的密码,来使用。
参考链接: Git深入浅出 Git 权限校验 (最熟悉的陌生概念)
六、从仓库目录角度了解Git工作原理
6.1 目录结构
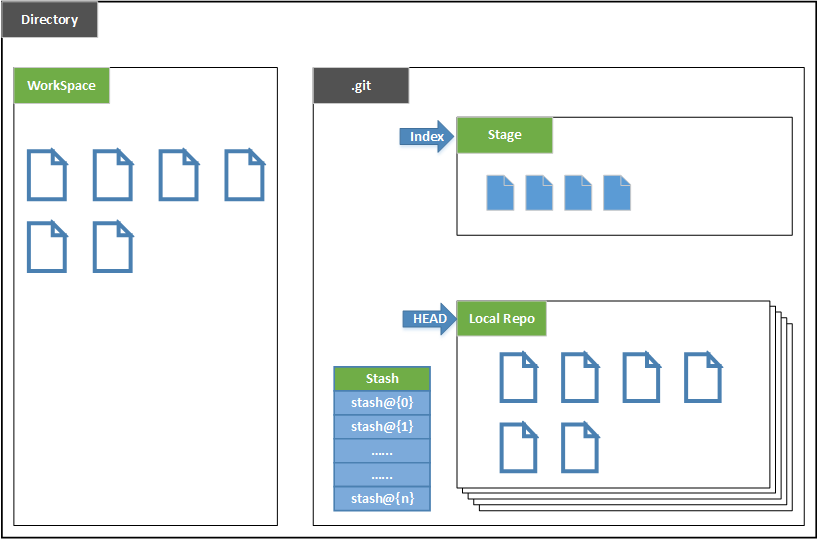
- Directory:使用 Git 管理的一个目录,也就是一个仓库,包含我们的工作空间和 Git 的管理空间。
- WorkSpace:需要通过 Git 进行版本控制的目录和文件,这些目录和文件组成了工作空间/工作区/工作目录,除了 .git 之外的都属于工作区。
- 工作目录下的文件有两种状态:已跟踪tracked或未跟踪untracked(新创建的文件,没有被add到暂存区就是untracked状态)
- Xcode新建项目时,会自动将新建的文件保存到暂存区,这是IDE自己做的,正常情况下不会的,VSCode也不会。
- .git:存放 Git 管理信息的目录,初始化仓库的时候自动创建。
- Index/Stage:暂存区,或者叫待提交更新区,在提交进入 repo 之前,我们可以把所有的更新放在暂存区。
- Local Repo:本地仓库,一个存放在本地的版本库;HEAD 会只是当前的开发分支(branch)。
- Stash:是一个工作状态保存栈,用于保存/恢复 WorkSpace 中的临时状态。
一个 modification 的提交要经历工作区——add到暂存区(staged)——commit到本地仓库——push到远程仓库
文件的状态改变:
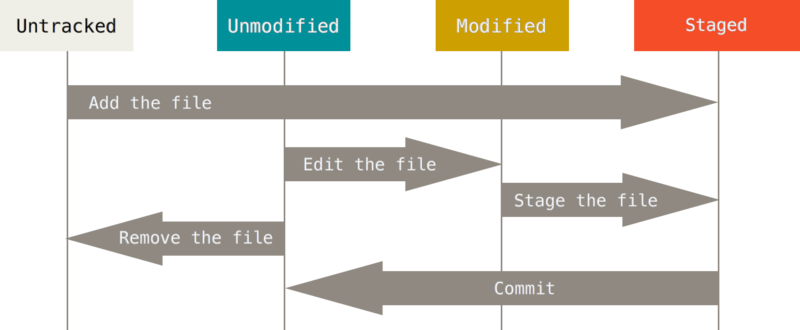
6.2 .git文件夹(版本库)
6.2.1 index
暂存区是Git相比SVN的特色;
当修改了工作区里的一个文件时,这些修改一开始是unstaged状态,为了提交这些修改,你需要使用git add把它加入到index,使它成为staged状态。当你提交一个commit时,index里面的修改被提交;
当在工作区新增一个文件,文件是untracked状态,git add <file>添加到index,变为tracked状态。
6.2.2 objects/
该文件夹下存储了所有数据内容。主要有四大对象:数据对象、树对象、提交对象、标签对象。
1. 数据对象(对应 文件)
Git 是一个内容寻址文件系统,即Git 的核心部分是一个简单的键值对数据库(key-value data store)。 你可以向该数据库插入任意类型的内容,它会返回一个键值,通过该键值可以在任意时刻再次检索(retrieve)该内容。
可以通过底层命令hash-object来演示上述效果——该命令可将任意数据保存于.git目录,并返回相应的键值。
1 | echo 'test content' | git hash-object -w --stdin |
- -w选项指示hash-object命令存储数据对象;若不指定此选项,则该命令仅返回对应的键值。
- –stdin选项则指示该命令从标准输入读取内容;若不指定此选项,则须在命令尾部给出待存储文件的路径。
- 该命令输出一个长度为 40 个字符的校验和。 这是一个 SHA-1 哈希值——一个将待存储的数据外加一个头部信息(header)一起做 SHA-1 校验运算而得的校验和。
- 可以在objects目录下看到一个文件, 校验和的前两个字符用于命名子目录,余下的 38 个字符则用作文件名。
可以通过 cat-file 命令从 Git 那里取回数据,这个命令简直就是一把剖析 Git 对象的瑞士军刀。
1 | # -t 打印其内部存储的对象类型(SHA-1 值为目录名+文件名):输出为:`blob`、`tree`、`commit` |
每当一个文件修改时,就会生成一个数据对象。数据对象的内容是源文件当前的全部内容(而非存储的修改内容,保证了每次切换节点时,快速恢复!)。
不过, 记住文件的每一个版本所对应的 SHA-1 值并不现实。另一个问题是,在这个(简单的版本控制)系统中,文件名并没有被保存——我们仅保存了文件的内容。 上述类型的对象我们称之为数据对象(blob object)
2. 树对象(对应 目录)
树对象(tree object)能解决文件名保存的问题,也允许我们将多个文件组织到一起。 Git 以一种类似于 UNIX 文件系统的方式存储内容,但作了些许简化:
- 所有内容均以树对象和数据对象的形式存储,其中树对象对应了 UNIX 中的目录项,数据对象则大致上对应了 inodes 或文件内容;
inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础。
我觉得,理解inode,不仅有助于提高系统操作水平,还有助于体会Unix设计哲学,即如何把底层的复杂性抽象成一个简单概念,从而大大简化用户接口。
一、inode是什么?
理解inode,要从文件储存说起。- 文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。
- 操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的”块”,是文件存取的最小单位。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。
- 文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”。
- 每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
二、inode的内容
inode包含文件的元信息,具体来说有以下内容:- 文件的字节数
- 文件拥有者的User ID
- 文件的Group ID
- 文件的读、写、执行权限
- 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
- 链接数,即有多少文件名指向这个inode
- 文件数据block的位置
可以用stat命令,查看某个文件的inode信息:
stat example.txt - 一个树对象包含了一条或多条树对象记录(tree entry);
- 每条记录含有一个指向数据对象或者子树对象的 SHA-1 指针,以及相应的模式、类型、文件名信息。
- 文件模式为
100644,表明这是一个普通文件。 100755,表示一个可执行文件;120000,表示一个符号链接。- 这里的文件模式参考了常见的 UNIX 文件模式,但远没那么灵活——上述三种模式即是 Git 文件(即数据对象)的所有合法模式(当然,还有其他一些模式,但用于目录项和子模块)。
- 文件模式为
通常,Git 根据某一时刻暂存区所表示的状态创建并记录一个对应的树对象,如此重复便可依次记录(某个时间段内)一系列的树对象。因此,为创建一个树对象,首先需要通过暂存一些文件来创建一个暂存区。
可以通过write-tree命令将暂存区内容写入一个树对象。
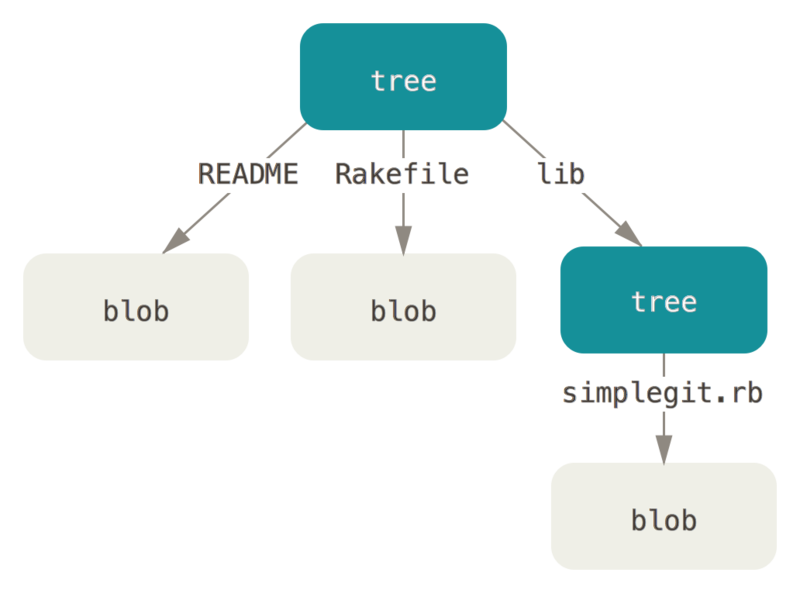
例如,某项目当前对应的最新树对象可能是这样的:
1 | # master^{tree}语法表示 master 分支上最新的提交所指向的树对象 |
如果基于这个新的树对象创建一个工作目录,你会发现工作目录的根目录包含两个文件、以及一个目录:
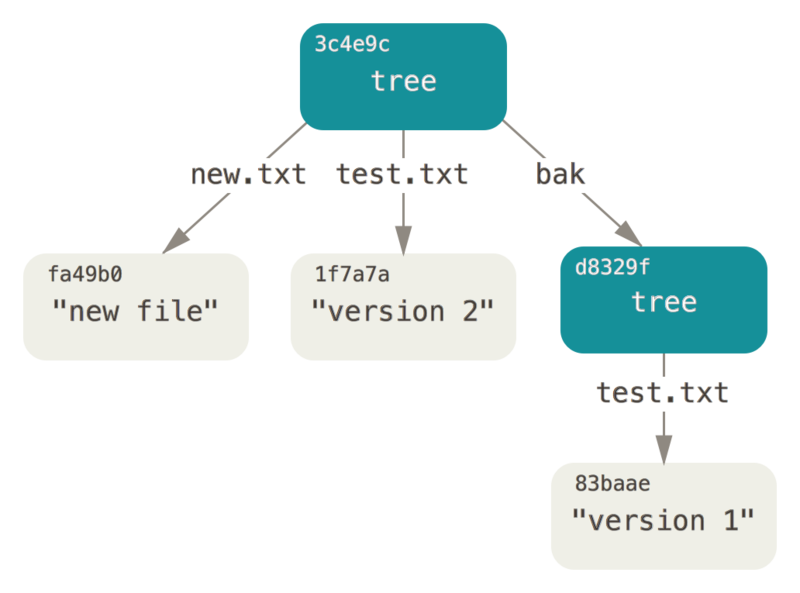
下面是个(非常规操作…)举例,你可以将一个旧的树对象加入新的树对象,使其成为新的树对象的一个子目录。 通过调用 read-tree 命令,可以把树对象读入暂存区。本例中,可以通过对 read-tree 指定 --prefix 选项,将一个已有的树对象作为子树读入暂存区:
1 | $ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579 |
如果基于这个新的树对象创建一个工作目录,你会发现工作目录的根目录包含两个文件以及一个名为 bak 的子目录,该子目录包含 test.txt 文件的第一个版本。 可以认为 Git 内部存储着的用于表示上述结构的数据是这样的:
3. 提交对象
树对象代表了我们想要跟踪的不同项目快照。然而问题依旧:若想重用这些快照,你必须记住所有三个 SHA-1 哈希值。 并且,你也完全不知道是谁保存了这些快照,在什么时刻保存的,以及为什么保存这些快照。 而以上这些,正是提交对象(commit object)能为你保存的基本信息。
- 可以通过调用
commit-tree命令创建一个提交对象,为此需要指定一个树对象的 SHA-1 值,以及该提交的父提交对象(如果有的话)。 - 提交对象的格式很简单:
- 它先指定一个顶层树对象,代表当前项目快照;这个树对象记录了此刻工作目录所有文件的状态,这也是Git切换快速便捷的原理。
- 然后是作者/提交者信息(依据你的user.name和user.email配置来设定,外加一个时间戳);
- 留空一行,最后是提交注释。(重要的两点:顶层树对象、父提交对象)
- 提交对象的SHA-1值即为commit id
提交对象对应的这个最顶层的树对象就对应了我们的工作目录,下面的每一个tree对象对应我们项目中的文件夹,每一个的blob对象就是此时该文件的最新全部内容。比如下面是一个大项目的master分支上最新提交对应的树对象:
1 | $ git cat-file -p master^{tree} |
4. 三种对象的关系图
每次我们运行 git add 和 git commit 命令时, Git 所做的实质工作——将被改写的文件保存为数据对象,更新暂存区,记录树对象,最后创建一个指明了顶层树对象和父提交的提交对象。 这三种主要的 Git 对象——数据对象、树对象、提交对象——最初均以单独文件的形式保存在 .git/objects 目录下。 如果跟踪所有的内部指针,将得到一个类似下面的对象关系图:
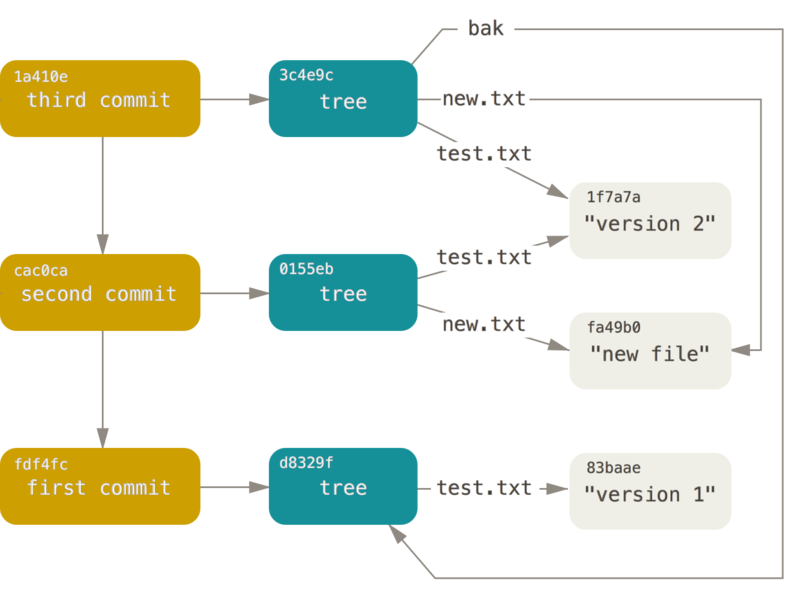
5. 对象的存储
Git在存储内容时,会有个头部信息一并被保存
- 以对象类型作为开头来构造一个头部信息:比如“blob”字符串,接着 Git 会添加一个空格,随后是数据内容的长度,最后是一个空字节(null byte)
"blob #{content.length}\0" - 将上述头部信息和原始数据拼接起来,并计算出这条新内容的 SHA-1 校验和
- 通过 zlib 压缩这条新内容
- 最后,需要将这条经由 zlib 压缩的内容写入磁盘上的某个对象。 要先确定待写入对象的路径(SHA-1 值的前两个字符作为子目录名称,后 38 个字符则作为子目录内文件的名称)。 如果该子目录不存在则创建它。
- 所有的 Git 对象均以这种方式存储,区别仅在于类型标识——另两种对象类型的头部信息以字符串“commit”或“tree”开头,而不是“blob”。 另外,虽然数据对象的内容几乎可以是任何东西,但提交对象和树对象的内容却有各自固定的格式。
6.2.3 refs/
存储指向数据(分支)的提交对象的指针;
GIT引用概述:由于一些地方需要用到SHA-1值,而SHA-1不易记录, 我们需要一个文件来保存 SHA-1 值,并给文件起一个简单的名字,然后用这个名字指针来替代原始的 SHA-1 值。
- 在 Git 里,这样的文件被称为“引用(references,或缩写为 refs)”;可以在.git/refs目录下找到这类含有 SHA-1 值的文件。(帮助我们记忆最新提交所在的位置);
- 这基本就是 Git 分支的本质:一个指向某一系列提交之首的指针或引用, 当运行类似于
git branch (branchname)这样的命令时,Git 实际上会运行update-ref命令,取得当前所在分支最新提交对应的 SHA-1 值,并将其加入你想要创建的任何新引用中。
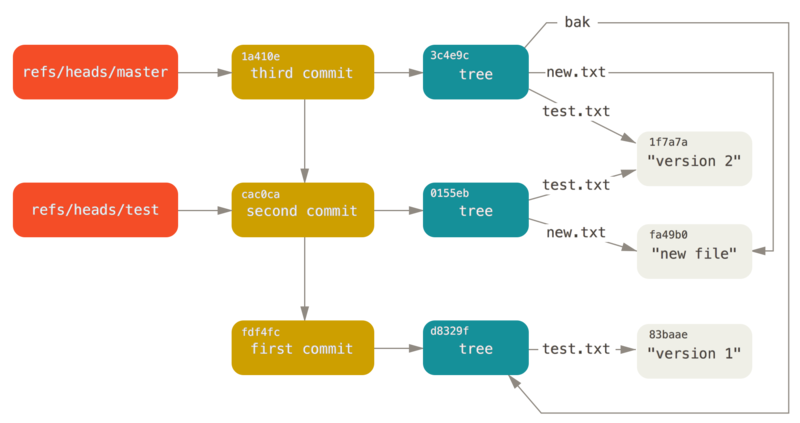
1. heads/ — HEAD引用
现在的问题是,当你执行git branch (branchname)时,Git 如何知道最新提交的 SHA-1 值呢? 答案是 HEAD 文件。
HEAD 文件是一个符号引用(symbolic reference),指向目前所在的分支。 所谓符号引用,意味着它并不像普通引用那样包含一个 SHA-1 值——它是一个指向其他引用的指针:
- 如果查看 HEAD 文件的内容,一般而言我们看到的类似这样:
ref: refs/heads/master(或者当前分支名); - 当我们执行
git commit时,该命令会创建一个提交对象,并用 HEAD 文件中那个引用所指向的 SHA-1 值设置其父提交字段。
/refs/heads/ 记录本地每个分支的提交之首
2. tags/ — Tag引用
标签对象(tag object)非常类似于一个提交对象——它包含一个标签创建者信息、一个日期、一段注释信息,以及一个指针。
主要的区别在于,标签对象通常指向一个提交对象,而不是一个树对象。 它像是一个永不移动的分支引用——永远指向同一个提交对象,只不过给这个提交对象加上一个更友好的名字罢了。
- 轻量标签: 只是一个特定提交的固定引用
- 附注标签:Git 会创建一个标签对象,并记录一个引用来指向该标签对象,而不是直接指向提交对象
标签对象并非必须指向某个提交对象;你可以对任意类型的 Git 对象(比如数据、树对象)打标签
3. remotes/ — 远程引用(remote reference)
如果你添加了一个远程版本库并对其执行过推送操作,Git 会记录下每一个分支最近一次推送操作时所对应的SHA-1值,并保存在refs/remotes目录下(文件名为远程分支名)
- 远程引用和分支(位于refs/heads目录下的引用)之间最主要的区别在于,远程引用是只读的(本地仓库的commit可以reset来修改HEAD的指向,但是remote repo的是不能的)
子文件夹为远程仓库的名称(如果有多个远程仓库(config文件中有多个[remote xxx])就有多个子文件夹),文件夹中的文件名称是远程仓库中执行过推送操作的远程分支名。
4. for/ — Gerrit
如果我们使用的是Gerrit(一种开放源代码的代码审查软件,使用网页界面。利用网页浏览器,同一个团队的软件开发者,可以在评审网页上相互审阅彼此修改后的代码,决定是否能够提交,回退或是继续修改。它使用版本控制系统Git作为底层)
- Gerrit为了保证每次代码提交都强制开启代码评审,要求研发人员在提交代码的时候统一使用: git push [remote_name] HEAD:refs/for/[branch_name],执行后会在评审界面创建一条新的code review,只有通过review之后才可以合入远程仓库。
- 此时如果执行
git push origin HEAD:refs/head/master,那么就会有“! [remote rejected] master -> master (prohibited by Gerrit)”的错误信息,命令失效。 - 对于那些希望将Code Review粒度控制在单次提交级别的研发团队,使用基于Gerrit机制的工具是比较合适的。( 百度效率云的iCode就是基于Gerrit机制开发的 )
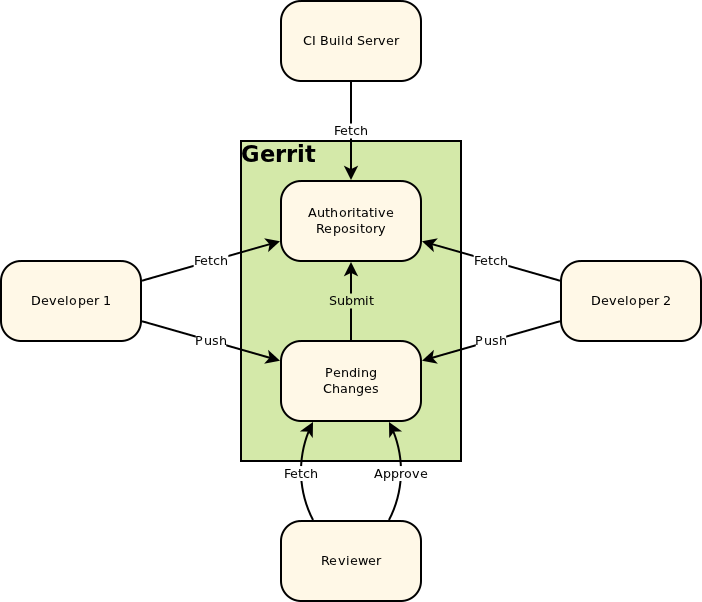
下面一段是对“refs/for”更详细的描述:
The documentation for Gerrit explains that you push to the “magical refs/for/‘branch’ ref using any Git client tool”.
This image is taken from the Intro to Gerrit. When you push to Gerrit, you do git push gerrit HEAD:refs/for/
<BRANCH>. This pushes your changes to the staging area (in the diagram, “Pending Changes”). Gerrit doesn’t actually have a branch called<BRANCH>; it lies to the git client.Internally, Gerrit has it’s own implementation for the Git and SSH stacks. This allows it to provide the “magical” refs/for/
<BRANCH>refs.When a push request is received to create a ref in one of these namespaces Gerrit performs its own logic to update the database, and then lies to the client about the result of the operation. A successful result causes the client to believe that Gerrit has created the ref, but in reality Gerrit hasn’t created the ref at all.
After a successful patch (i.e, the patch has been pushed to Gerrit, [putting it into the “Pending Changes” staging area], reviewed, and the review has passed), Gerrit pushes the change from the “Pending Changes” into the “Authoritative Repository”, calculating which branch to push it into based on the magic it did when you pushed to refs/for/
<BRANCH>. This way, successfully reviewed patches can be pulled directly from the correct branches of the Authoritative Repository.
6.2.4 HEAD
指向当前分支的当前提交;
6.2.5 config
文件包含项目特有的配置选项,覆盖Git的全局配置
6.2.6 description
仅供 GitWeb 程序使用,我们无需关心
6.2.7 hooks/
包含客户端或服务端的钩子脚本(hook scripts), hook用户操作,拦截一些不合理的行为命令
6.2.8 info/
目录包含一个全局性排除(global exclude)文件,用以放置那些不希望被记录在 .gitignore 文件中的忽略模式(ignored patterns)
七、常用命令
7.1 提交、撤销与查看
1. git checkout 工作区的撤销
1 | # 撤销文件在工作区的修改(处于暂存区的修改不受影响) |
- 注意:如果不加
--,就变成了“切换到另一个分支”的命令 - untracked的文件修改不受影响
2. git add 暂存区的提交
1 | git add <filename> # .表示全选 |
是个多功能命令,根据目标文件的状态不同,此命令的效果也不同:
- 可以用它开始跟踪新文件
- 把已跟踪的文件放到暂存区。
- 还能用于合并时把有冲突的文件标记为已解决状态
3. git rm 暂存区的提交
删除文件,并将这个删除添加到暂存区
1 | git rm <filename> |
等价于
1 | rm <filename> |
4. git commit 本地仓库的提交
1 | git commit -m 'commit message' |
将暂存区里所有的修改提交到本地仓库的当前分支:
- 会显示: file changed(文件修改)、insertions(插入行)、deletions(删除行)
- 可以多次add,一次commit
commit id解释说明:
- 看到的一串类似
1094adb...的是commit id(版本号),和SVN不一样,Git的commit id不是1,2,3……递增的数字,而是一个SHA1计算出来的一个非常大的数字,用十六进制表示。 - 为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统,后面我们还要研究多人在同一个版本库里工作,如果大家都用1,2,3……作为版本号,那肯定就冲突了。
5. git reset 暂存区与本地仓库的撤销
1 | git reset [<mode>] [<commit>] |
将当前分支的HEAD指向给定的版本,并根据模式的不同决定是否修改index和working tree。
- –soft模式
- 指定commit id之后的所有commit的修改、目前index中暂存的修改都被保留在index中;
- working tree中还没暂存的修改保持原样。
- –mixed(默认)
- 清空index
- 指定commit id之后的所有commit的修改、目前index中暂存的修改、目前working tree中还没暂存的修改都被保留在工作区中
- 可以巧用
git reset来撤销添加到暂存区中的修改(放入了工作区),即git reset HEAD <file>
- –hard:
- 清空index、workingtree,指定commit id之后的所有提交修改也不会保留。
其他应用:
- 可以先将修改提交到远程仓库,然后使用
--soft、--mixed来将某个功能的一系列提交(本地仓库中),重置到最开始的commitid,此时该功能的所有代码都会被保留到工作区或暂存区。方便我们做Code Review。类似git diff等补丁创建命令。
需要注意:
- reset是操作的本地仓库,所以只能reset那些未push到remote仓库的commit。
- Git的版本回退速度非常快,因为Git会保存所有修改,而reset实质上是重置本地仓库的HEAD到指定的commit id,即当你回退版本的时候,Git仅仅是在改变HEAD指向。
- 想从3回滚到1,可以使用
git log来查看提交日志,获取commit id; - 如果commit已经push到远程仓库,那么origin/HEAD是不受影响的(
提交的修改仍保留在远程仓库),还是指向最新的commit id,此时sourceTree会提示有提交未拉取。
如果在这个本地仓库的版本上做修改,提交的时候会失败:Updates were rejected because the tip of your current branch is behind its remote counterpart,即告诉你需要先pull再push。
撤销之后想恢复
假如我们刚刚使用了reset –hard从commit3回滚到了1(并清空了工作区),想再恢复到3:
前提是被丢弃的分支或commit信息还没有被git gc清除,一般情况下,gc对那些无用的object会保留很长时间后才清除的。
第一步:通过git log -g命令来找到需要恢复的信息对应的commitid。可以通过提交的时间和日期来辨别,找到执行reset –hard之前的那个commit对应的commitid。(使用 git reflog 从命令日志中找到commit对应的commitid也是可以的)。
第二步:
- 仍然可以使用git reset:
git reset <commitid> - 使用
git branch <branchname> <commitid>,会新建分支,并将到commitid为止的代码、各种提交记录等信息都恢复到了新分支上。
6. git revert 本地仓库的撤销
1 | git revert <commit> |
回滚指定的提交,并产生一条新的commit。
在指定commit id的时候,除了通过git log、git reflog来查看,还可以指定通过HEAD(大写)来指定,HEAD表示当前分支当前版本, 上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
7. git status
查看仓库当前的状态:
- changes to be committed: 将要被提交的修改包括以下
- no changes added to commit:没有被暂存修改要提交
- changes not staged for commit:以下修改没有被暂存
- no thing to commit, working tree clean:没有需要提交的修改,而且工作目录是干净的
8. git log
显示从最近到最远的提交日志。
每提交一个新版本,实际上Git就会把它们自动串成一条时间线。如果使用可视化工具查看Git历史,就可以更清楚地看到提交历史的时间线。
- –graph:显示 ASCII 图形表示的分支合并历史
- –decorate 标记会让git log显示每个commit的引用(如:分支、tag等)
- –simplify-by-decoration 只显示被branch或tag引用的commit(如果去掉该参数,分支图与GUI显示的基本一致了)
- –all 表示显示所有的branch,这里也可以选择,比如我只想显示分支ABC的关系,则将–all替换为branchA branchB branchC
- –abbrev-commit:仅显示 SHA-1 的前几个字符,而非所有的 40 个字符。
- –pretty:使用其他格式显示历史提交信息。可用的选项包括 oneline(简写一行),short,full,fuller 和 format(后跟指定格式)
- -
<num>:显示几条 - 等等
常用的git log命令:
1 | git log --graph --decorate --oneline --simplify-by-decoration --all |
感觉再怎么着也没GUI清晰…
举例:一个统计代码仓库提交、去重的小脚本
1 | # 输出commit、然后手动去重(避免某些人不规范使用git,提msg一样的commit)即可 |
9. git reflog
显示命令历史,记录每一次命令
10. git push
将当前分支的修改推送到远程分支,如果没有该远程分支则创建;
1 | git push [-u | --set-upstream] [<远程仓库名>] [<本地分支名>] [<:远程分支名>] |
远程分支名可以写为refs/heads/xx或直接写为xx,好像没区别。
- 如果只省略
<:远程分支>:将指定的本地分支上的修改推送到同名的远程主机分支上; - 如果只省略
<本地分支名>:表示删除指定的远程分支,因为这等同于推送一个空的本地分支到远程分支,等同于git push origin --delete master。注意:不会影响本地分支; - 如果当前分支是某个远程仓库中某个分支的跟踪分支,且两者同名,git push后省略远程仓库名、本地分支名、远程分支名等一切参数;
- 不带任何参数的git push,默认只推送当前分支,这叫做simple方式,还有一种matching方式,会推送所有有对应的远程分支的本地分支, Git 2.0之前默认使用matching,现在改为simple方式。如果想更改设置,可以使用git config命令。
git config --global push.default matchingORgit config --global push.default simple;可以使用git config -l查看配置 - Tag对象与Commit对象十分相似,所以上面一些用法,在推送、删除tag对象时同样适用,比如git push origin :tagName 删除远程tag。
--force 参数:
- 用于强制推送本地分支到远程存储库,覆盖远程分支的内容。通常,Git 会阻止你推送会导致远程分支发生回退的更改,但使用
--force参数可以绕过这种保护。 - 这种操作通常在以下情况下使用:
- 重写历史记录:当你需要对本地分支进行变基(rebase)或重写历史记录后,想将这些变更推送到远程分支时。
- 修复错误的提交:当你在本地修正了一些错误的提交,并需要将这些更改强制推送到远程存储库时。
- 注意事项:使用
--force参数时需要非常小心,因为它会覆盖远程分支的内容,可能导致其他开发者的工作丢失或造成混乱。因此,通常建议在团队中使用--force前进行充分的沟通。 - 安全替代:为了减少误操作的风险,可以使用
--force-with-lease参数。它会在推送前检查远程分支是否被其他人更新过,如果没有更新则进行推送,有更新则推送失败。这可以避免覆盖其他人的工作。
11. 冲突处理
执行git push之前,养成git pull的好习惯,如果有冲突,先处理冲突。
如果远程分支有别人的提交,而本地没有拉取,git push的时候,会失败
1 | error: failed to push some refs to 'git@github.com:michaelliao/learngit.git' hint: Updates were rejected because the remote contains work that you do not have locally. |
此时,应先拉取,再push,push之后发现,提交分支图上,出现了分叉,这是因为你的commit及远程他人的提交的父提交对象都是同一个commit对象,所以图谱上当然有分叉。且额外创建了一个新的commit: Merge branch ‘<branch>’ of github.com...,如果不想要这种情况可以使用git rebase。
12. git rebase
1 | git rebase <branch> # 操作当前分支变基 |
功能:
- 将当前分支(分叉)上的一系列提交的基(父提交)改为指定分支的最新提交
- 视觉效果:消除了分支、push的时候远程有提交未拉取造成的分叉
- 注意:只能变基本地的分支,如果commit已经推到了远程,就不要再在本地操作了,会弄混乱:此时操作之后根据rebase的工作原理,相当于本地分支新增了数个commit,然后远程仓库中的几个老commit因为被本地分支上删除就会被认成是未拉取的commit。可以先删除远程分支,再变基,再推送。
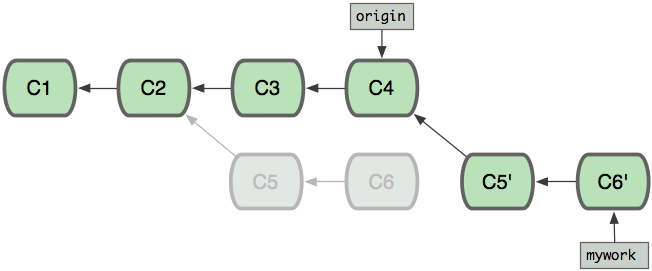
本质是:
- 把当前分支里的每个提交(commit)取消掉,并且把它们临时 保存为补丁(patch)(这些补丁放到”.git/rebase“目录中)
- 然后把当前分支的根commit更新为指定分支的最新commit
- 最后把保存的这些补丁重新应用到当前分支上
- 更新之后,老的commit会丢弃,而<当前分支>引用指向新创建的最新commit
rebase的目的是使得我们在查看历史提交的变化时更容易,因为分叉的提交需要三方对比。
13. git pull
取回远程主机某个分支的更新,再与本地的指定分支合并。
1 | git pull [远程仓库名] [远程分支名][:<本地分支名>] # git pull origin develop:develop (:前后无空格) |
- [:<本地分支名>] 可以省略,表示拉取并与当前分支合并;
- 如果当前分支是跟踪分支,那么可以直接
git pull; - 实质上,这等同于先做
git fetch(从远程获取最新版本(即对象和引用)到本地,不会自动合并),再执行git merge;
避免与本地的改动冲突:
- 如果本地仓库没有commit:先stash,再pull,再应用stash;
- 如果本地仓库中有commit:加
--rebase参数:与git rebase功能类似,表示把你的本地当前分支里的每个提交(commit)取消掉,并且把它们临时保存为补丁(patch)(这些补丁放到.git/rebase目录中),然后把本地当前分支更新为最新的”origin”分支,最后把保存的这些补丁应用到本地当前分支上。
7.2 分支(平行宇宙)
其他版本控制系统如SVN等都有分支管理,但是用过之后你会发现,这些版本控制系统创建和切换分支比蜗牛还慢,简直让人无法忍受,结果分支功能成了摆设,大家都不去用。
但Git的分支是与众不同的,无论创建、切换和删除分支都很快。
前面已经提到,每次提交,Git都把它们串成一条时间线,这条时间线就是一个分支,默认有一条分支叫主分支,即master分支。
1. git branch 创建/删除/查看分支
1 | # 创建分支 |
2. git checkout 切换
1 | git checkout <branch> # 切换到分支 |
前面讲过,撤销修改是 git checkout -- <file>,为了避免混淆,最新版本的Git提供了新的git switch命令来切换分支。
1 | git switch <branch> # 切换 |
3. 跟踪分支
跟踪分支是与远程分支有直接关系的本地分支。 如果在一个跟踪分支上输入git pull、git push,Git 能自动地识别去哪个服务器(仓库名指定的)上的哪个分支pull、push。
1) 跟踪分支的作用
如果未设置跟踪分支:
无论是否存在同名的远程分支,git push、git pull时都要加上<远程主机名> <本地分支名>
不然前者报错:
1 | fatal: The current branch <localBranch> has no upstream branch. |
后者报错:
1 | There is no tracking information for the current branch. Please specify which branch you want to merge with. See git-pull(1) for details. |
如果设置了跟踪分支:
设置成功后,会提示:Branch ‘testBranch’ set up to track remote branch ‘testBranch’ from ‘origin’.
本地分支与跟踪的远程分支是否同名:
- 是:可以直接使用git push、git pull,省略之后的参数
- 否:依然可以使用git pull。不能直接使用git push,省略之后报错:
1 | fatal: The upstream branch of your current branch does not match the name of your current branch. |
2) 跟踪分支的设置
- 从一个远程跟踪分支检出本地分支时,选择本地分支是否跟踪远程分支;
- 当克隆一个仓库时,它通常会自动地创建一个跟踪origin/master的master分支;
- 设置已有的本地分支跟踪一个刚刚拉取下来的远程分支,或者想要修改正在跟踪的上游分支,你可以在任意时间使用
-u或--set-upstream-to选项运行git branch来显式地设置。1
2
3
4
5
6git branch (--set-upstream-to=<upstream> | -u <upstream>) [<branchname>]
# 举例
git branch --set-upstream-to=origin/mybranch1 mybranch1
git branch -u origin/mybranch1 mybranch1
# 1. 后者可省略,表示当前本地分支
# 2. 一定要加origin,否则表示本地分支,而且还能跟踪成功,表示当前本地分支跟踪了另一个本地分支 - git push的时候设置:表示把localBranch分支上的修改提交到remoteBranch上,并建立跟踪关联。相比之下这种方式比上面那种使用的更普遍,因为上面那个首先需要有那个远程分支才可以用。
1
git push -u/--set-upstream origin localBranch:remoteBranch # 后者可省略,表示远程同名分支
3) 跟踪分支的查看
如果想要查看设置的所有跟踪分支,可以使用git branch -vv: 会将所有的本地分支列出来并且包含更多的信息,如每一个分支正在跟踪哪个远程分支与本地分支是否是领先、落后或是都有。
4) 跟踪分支的取消
1 | git branch --unset-upstream [<branchname>] #branchname可省略,表示当前分支 |
4. git merge 合并
1 | git merge <branch> # 合并指定分支到当前分支 |
如果合并发生冲突(两个分支都对一个文件进行修改):
- 继续合并,那需要我们解决冲突后,再手动提交。
- 解决冲突就是把Git合并失败的文件手动编辑为我们希望的内容,再提交。
git status也可以告诉我们冲突的文件。- 处理完文件中的修改冲突后,git add .(或者git add 冲突文件),然后
git commit或者git merge --continue(会检查是否存在正在进行的(中断的)合并git commit)
- 决定不合并,可以使用
git merge --abort。
–no-ff
合并分支时,如果可能,Git会用Fast forward模式:
- 当你试图合并两个分支时,如果顺着一个分支走下去能够到达另一个分支,那么 Git 在合并两者的时候,只会简单的将指针向前推进(指针右移),因为这种情况下的合并操作没有需要解决的分歧——这就叫做 “快进(fast-forward)”
- 举例:比如从master上创建分支A,在A上有了数个commit,master上没有提交,此时将A合并到master,实质是将master直接指向A的最新commit(将master引用指向的SHA-1值改为A最新的commit对象的SHA-1值)。
- 普通模式的合并有分叉,可以看出曾经做过合并,而fast forward合并看不出来曾经做过合并。
如果不是fast-forward模式,Git就会在merge时生成一个新的commit。
可以强制禁用Fast forward模式:
1 | git merge --no-ff -m <“merge”> <branch> # 要加commit message,因为会生成一个新commit对象 |
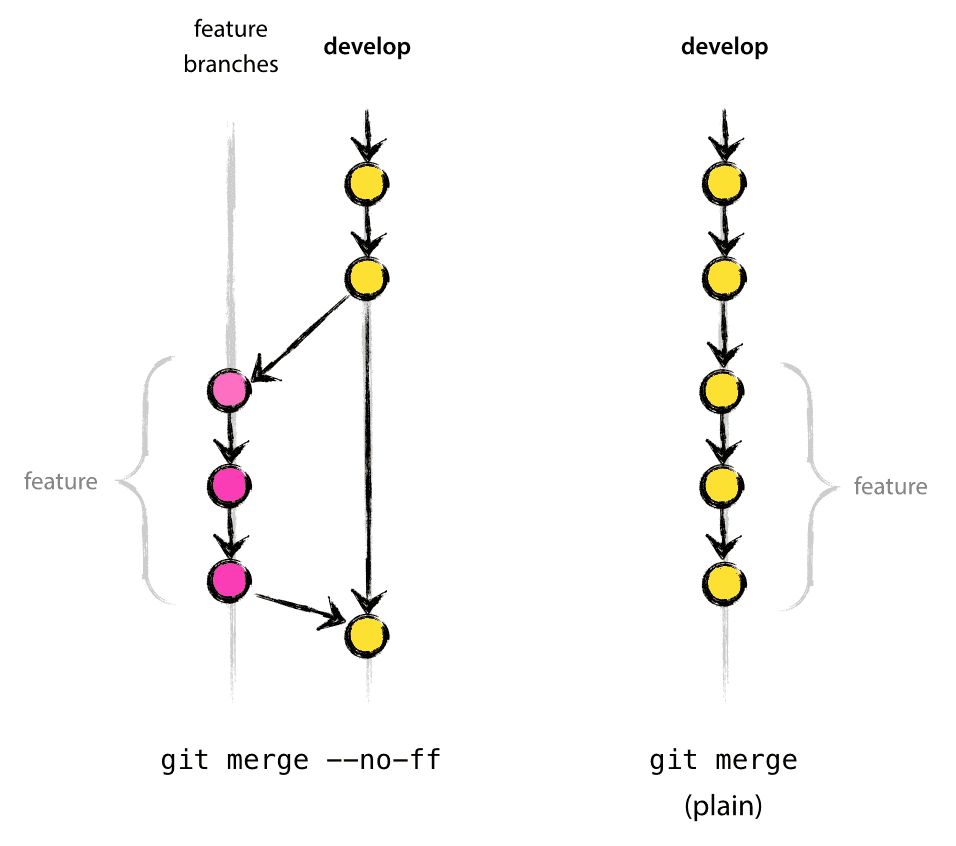
建议都加上 --no-ff:
- 如果有些分支合并后删除,那么
--no-ff可以很清楚的看到这些分支的历史存在的信息。反之,fast-forward模式就会导致不知道这些分支曾经存在过。 - 可以将所有一起实现了一项功能的 commit 组合在一起。否则,您必须手动读取所有日志消息,来判定一项功能实现所需要的commit。此时,撤销整个功能(即一组提交)是一个真正令人头疼的问题。
- 是的,它会创建更多(空)commit 对象,但收益远大于成本。
5. git log 查看
显示分支合并图
1 | git log --graph --pretty=oneline --abbrev-commit |
6. git cherry-pick
1 | # 获得在另一个分支中单个提交中引入的变更,然后尝试将作为一个新的提交引入到你当前分支上。 |
如果操作过程中发生代码冲突,Cherry pick 会停下来,让用户决定如何继续操作。
- –continue
用户解决代码冲突后,第一步将修改的文件重新加入暂存区(git add .),第二步使用下面的命令,让 Cherry pick 过程继续执行。git cherry-pick --continue - –abort
发生代码冲突后,放弃合并,回到操作前的样子。 - –quit
发生代码冲突后,退出 Cherry pick,但是不回到操作前的样子。
7.3 stash
默认情况下,git stash 命令只暂存 Git 已跟踪的文件更改,不会暂存未跟踪的文件和 .gitignore 文件中忽略的文件。(Xcode新建项目时,会自动将新建的文件保存到暂存区,这是IDE自己做的,正常情况下不会的,VSCode也不会)
1 | git stash [save "save message"] # 将更改储藏在脏工作目录中,clean目前工作区. |
7.4 tag
1 | git tag <name> [commit] # 打一个轻量标签,如果省略<commit>,则表示最新提交 |
如果tag与分支同名,在/refs/heads/、/refs/tags/下都能找到文件名为这个名字的文件,此时操作时如果直接写标签名,可能会报错:...match more than one。
7.5 补丁的创建与应用
Git 提供了两种补丁方案
- 用
git diff生成的UNIX标准补丁.diff文件: .diff文件只是记录文件改变的内容,不带有commit记录信息,多个commit可以合并成一个diff文件。 - 用
git format-patch生成的Git专用.patch 文件: .patch文件带有记录文件改变的内容,也带有commit记录信息。每个commit对应一个patch文件。
在Git下,我们可以使用.diff文件也可以使用.patch 文件来打补丁,主要应用场景有:CodeReview、代码迁移等。
7.5.1 创建补丁git diff
顾名思义就是查看已跟踪tracked文件的difference:
1 | git diff [--cached] [<commit> [(^.. | ..)<commit>]] [-- 查看文件名(路径写全)] [> diff补丁文件名] |
- 不加参数即默认比较工作区与暂存区;
- 如果加了一个commit id,表示比较目前代码与指定commit的差异 = 当前工作区+暂存区+指定commit后的commit修改;
- 如果加了两个commit id,表示比较后者与前者两次提交之间的差异;(新提交的commit id在后)
- 如果加了–cached(后面即使没有commit id,默认相当于有个HEAD),意义是在上条的基础上忽略工作区的改动,即差异 = 当前暂存区 + 指定commit后的commit修改;
- 在上面的基础上,后面如果加了
> 文件名,表示将上面比较出的差异,导出一个补丁,可以拷贝到另一机器或者另一个马甲项目中应用。
7.5.2 创建补丁git patch
会将指定commit id 后的每一个commit分别单独生成patch文件。
patch文件按照commit的先后顺序从1开始编号。
patch文件会生成到当前目录下。
1 | git format-patch [<commit> [(^.. | ..)<commit>]] [-n] [> patch补丁文件名] |
- commitId 如果省略,表示HEAD指针指向的commit
- -n 表示为HEAD后的n个 commit 生成 patch
7.5.3 补丁应用git apply
1 | # 检查patch/diff是否能正常打入。如果没有任何输出,那么表示可以顺利接受这个补丁 |
此外,patch补丁文件,还可以使用git am命令来应用
1 | git am <path/to/xxx.patch> |
补丁冲突解决:
在打补丁过程中有时候会出现冲突的情况,有冲突时会打入失败。此时需要解决冲突:
- 首先使用 以下命令行,自动合入 patch 中不冲突的代码改动,同时保留冲突的部分: git apply –reject xxxx.patch . 此时会在终端中显示出冲突的大致代码, 同时会生成后缀为 .rej 的文件,保存没有合并进去的部分的内容,可以参考这个进行冲突解决。
- 解决完冲突后删除后缀为 .rej 的文件,并执行
git add .添加改动到暂存区. - 接着执行
git am --resolved或者git am --continue
说明:在打入patch冲突时,可以执行git am –skip跳过此次冲突,也可以执行git am –abort回退打入patch的动作,还原到操作前的状态。
7.5.4 手动修改补丁文件
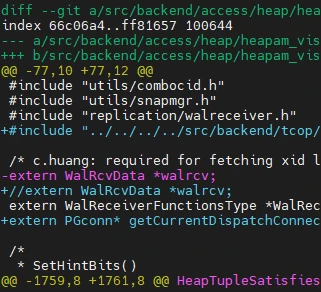
有时候patch apply遇到问题,可以根据当前上下文,手动修改patch再进行apply。
上图就是修改前的patch。patch格式说明,其格式为:
1 | @@ -[起始行号],[修改前的行数] +[起始行号],[修改后的行数] |
在新增或删除一行时,记得修改 [修改后的行数]
7.6 子模块的使用
Git 子模块允许你将一个 Git 仓库作为另一个 Git 仓库的子目录。 它能让你将另一个仓库克隆到自己的项目中,同时还保持提交的独立。
.gitmodules 配置文件保存了项目 URL 与已经拉取的本地目录之间的映射。
- 如果有多个子模块,该文件中就会有多条记录。
- 该文件也像
.gitignore文件一样受到(通过)版本控制。 它会和该项目的其他部分一同被拉取推送。 这就是克隆该项目的人知道去哪获得子模块的原因。
1 | [submodule "DbConnector"] |
常用的命令:
- 添加子模块
1
git submodule add <repository> [<path>]
- 将指定的 Git 仓库作为子模块添加到当前 Git 仓库中。
<repository>是要添加的 Git 仓库的 URL,<path>是子模块存放的路径(默认为当前目录+子模块仓库名)。- 运行之后,会发现,已经有了仓库对应的子目录,并且代码已经拉取下来了
- 不过,git status查看,可以看到只显示了多了两个文件,不会将子仓库纳入到主仓库的版本管理中。
1
2
3
4
5
6On branch main
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: .gitmodules
new file: react-native
- 克隆含有子模块的项目
1
2
3
4
5
6
7
8
9
10
11
12
13# 方法1
git clone https://github.com/chaconinc/MainProject # 默认会包含该子模块目录,但是是空的,其中还没有任何文件
git submodule init # 根据.gitmodules文件中的信息来初始化本地配置文件,但是也不会下载子模块内容。
git submodule update # 从该项目中抓取所有数据并检出父项目中列出的合适的提交。
# 注意:此时,子目录不是远程最新,而是处在和之前提交时相同的状态(主仓库上一次添加/更新子仓库的状态)。
# 第2步、第3步,可以合为:
git submodule update --init
# 如果还要初始化、抓取并检出任何嵌套的子模块
git submodule update --init --recursive
# 方法2
git clone --recurse-submodules https://github.com/chaconinc/MainProject
# --recurse-submodules选项,会自动初始化并更新仓库中的每一个子模块,包括可能存在的嵌套子模块。 - 更新子仓库
- 在项目中使用子模块的最简模型,就是只使用子项目并不时地获取更新,而并不在你的检出中进行任何更改。
1
2
3
4
5
6
7
8
9
10# 方法1
# 可以进入到子仓库目录中,运行 git fetch 与 git merge,来从远程更新本地代码。
# 方法2
git submodule update --remote # Git将会进入子模块然后抓取并更新。
# 方法3
# 主仓库项目下
git pull # 默认会递归地抓取子模块的更改。然而,它不会更新子模块。
git submodule update --init --recursive # 大部分情况下git submodule update就够了,但覆盖所有场景,可以加上参数
# 合上面为一体
git pull --recurse-submodules
- 在项目中使用子模块的最简模型,就是只使用子项目并不时地获取更新,而并不在你的检出中进行任何更改。
- 在主项目中,修改子仓库的代码,并发布。(略)
- 移除子仓库
1
2
3
4
5
6
7
8
9
10
11
12# 方法1
git submodule deinit <path> # 卸载子模块。如果添加上参数 -f,则子模块工作区内即使有本地的修改,也会被移除
# 作用:1.在 .git/config 配置项中删除了子模块相关条目 2.移除子仓库中的代码
git rm <path> # 加-f强制删除
# 作用:1.删除子仓库的空文件夹 2.在.gitmodules中删除子模块相关内容
# 此时 .git/module/ 目录下子模块相关内容还有残余,可自行删除
# 方法2:方法1的面向过程版
rm -rf 子模块目录 # 删除子模块目录及源码
vi .gitmodules # 删除项目目录下.gitmodules文件中子模块相关条目
vi .git/config # 删除配置项中子模块相关条目
rm .git/module/* # 删除模块下的子模块目录,每个子模块对应一个目录,注意只删除对应的子模块目录即可
八、分支管理策略
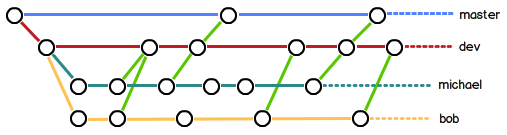
只有适合自己团队的,才是最好的。下面介绍的是一些经典的策略,但并不一定适合你。
8.1 develop—release—master
参考链接 — A successful Git branching model
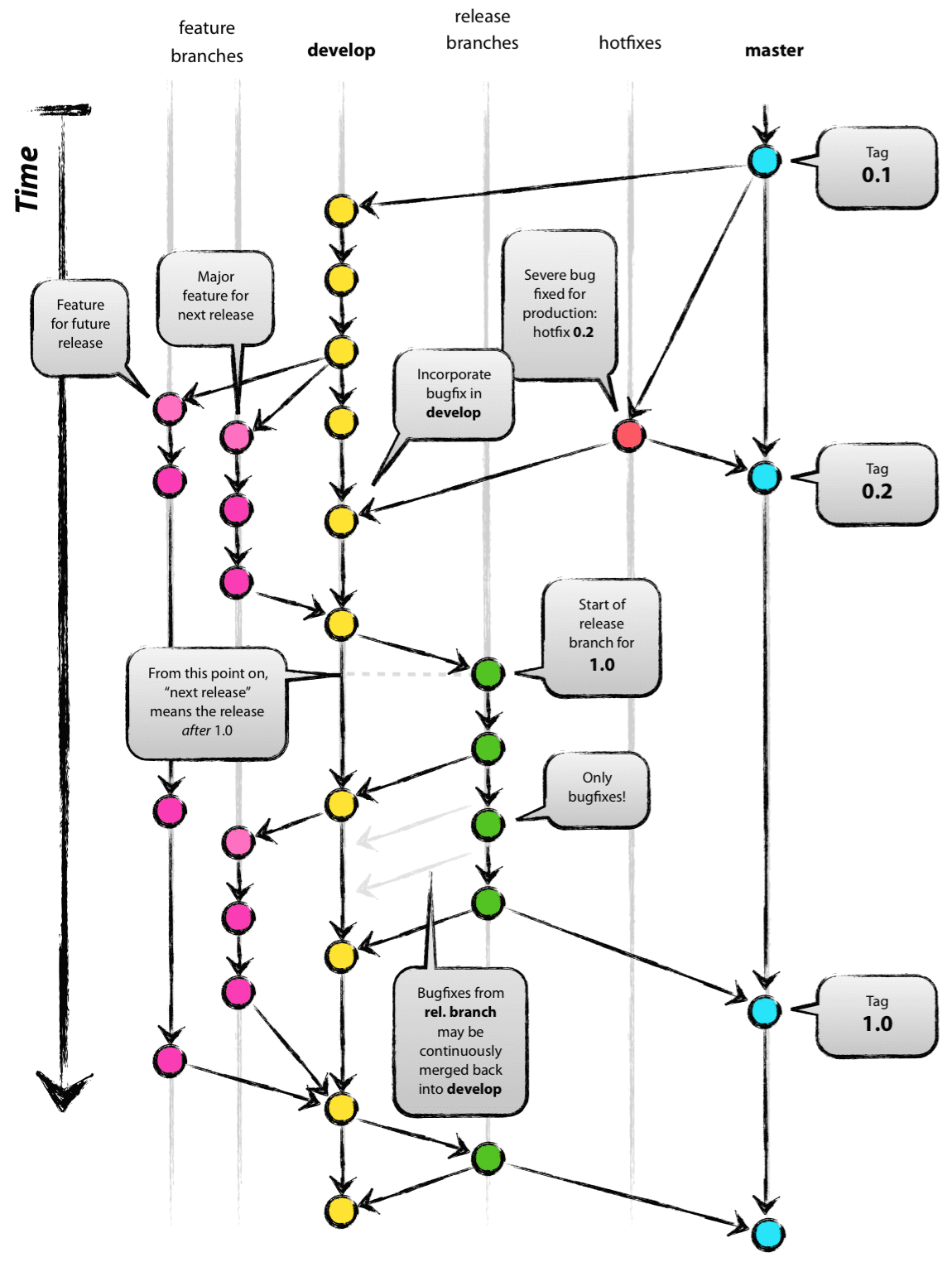
如果项目是持续交付软件(比如前端/后端),那建议采用更简单的工作流程(比如 GitHub flow);如果您正在构建明确版本化的软件,或者需要支持软件的多个版本同时运营,那本文的分支模型还是很有帮助的。
中央仓库拥有两个具有无限生命周期的主要分支:master与develop。这个两个分支的生命周期是整个项目周期。
- master与develop分支:
- master分支是创建git仓库时自动生成的,随即我们就会从master分支创建平行分支 — develop分支。
- master分支的
HEAD始终指向/反映当前生产环境的代码状态。 - develop分支的
HEAD始终指向/反映下一个交付版本的开发的最新状态。有人将其称为“集成分支”(integration branch)。 - 当develop分支中的源代码达到稳定点并准备发布时,所有更改都应该以某种方式(中间经过Release branches处理,后面细讲)合并回master,然后打个Tag(使用发布版本号命名)。
- 严格遵守:每次将更改合并回master分支时,这必然表示是一个新的生产版本。即master 上的每个提交都是定义的新版本。因此理论上,每次在 master 上进行提交,我们可以使用 Git hook 脚本来自动构建我们的软件并将其推出到我们的生产服务器上。
之外,还有各种支持分支来实现团队成员之间的并行开发、生产版本的准备、快速修复生产问题。
与master和develop分支不同,这些分支的生命周期总是有限的,因为它们最终会被合并到 develop 或 master 分支,然后删除。(建议:merge分支时,都加上 --no-ff 参数)
这些分支中的每一个都有特定的目的,并且必须遵守严格的规则,即它们是从什么分支中创建,需要合并到什么分支。
- Feature branches:功能分支,有时也称主题分支(topic branches)。
- 从develop分支创建,完成后合并回develop分支。
- 用于为即将发布的、或遥远的未来版本开发新功能。
- 当我们开始开发一个特性时,这个特性将被合并到的目标发布版本很可能是未知的。只要特性处于开发阶段,feature 分支就会一直存在,直到最终被合并回develop分支(新特性确定要添加到即将发布的版本中)或丢弃(实验效果不佳)。
- feature 分支通常仅存在于开发人员的仓库中,而不存在于 origin 中。(取决于需不需要协作吧)。使用完就可以删除了。
- Release branches:发布分支。命名规范
release-*(*最好是版本号)- 从develop分支创建,完成后合并回develop和master分支。
- 当 develop(几乎)达到了新版本的期望状态,至少所有新版本中需要的 feature 都合并到 develop 中时,我们从develop分支出一个release分支。在此分支上做一些发布版本的准备工作,准备一些发布的元数据,如版本号、构建日期等。此时,develop分支就可以接收/集成下一个大版本的功能。
- release分支创建之时,我们才能根据版本号更新规则确定新版本的版本号,此前,develop 分支只是反映了“下一个版本”的变化,但不清楚“下一个版本”最终会变成 0.3 还是 1.0 等。
- 这个新分支可能会存在一段时间,直到发布可能确定推出。在此期间,可以在此分支(而不是develop)中修复一些小错误。严禁在此分支上添加新feature,它们必须合并到develop分支中,等待下一个发布版本。
- 当release分支真正准备好要发布时,我们需要:
- release 分支被合并到 master 中。对 master 上的此次提交打个Tag,以便将来参考此历史版本。
- 在release分支上所做的更改需要合并回 develop,以便将来的版本也包含这些错误修复。
1
2
3
4
5
6
7$ git checkout master
$ git merge --no-ff release-1.2
$ git tag -a 1.2
$ git checkout develop
$ git merge --no-ff release-1.2
# 这一步很可能会导致合并冲突(因为我们已经更改了版本号)。如果是这样,修复它并提交。
- 此时,发布完成,release分支可以被删除,不再需要它。
- Hotfix branches:热修复分支,命名规范
hotfix-*(*可以是版本号,也可以约定为其他)。主要为修复线上特别紧急的bug准备的。- 从master分支创建,完成后合并回develop与master分支。
- hotfix 分支与 release 分支非常相似,因为它们也是在为新的生产版本做准备,尽管是计划外的…。当必须立即解决生产版本中的严重错误,等不到正常的版本迭代(develop/release分支代码还不够稳定)时,可以在 master 分支上,找到生产版本对应的Tag,从此处分支出一个 hotfix 分支。
- 后续跟release分支基本一致:确定版本号、通过一个或多个的commit修复错误、准备发布的元数据、测试完成合并回master、打tag标记发布版本、合并到develop。
- 此处规则有一个例外是,如果当前存在 release 分支,hotfix 分支需要合并到该 release 而不是 develop 分支中。一是因为 release 分支需要同步此修改,二是 release 完成时,会合并到develop 分支中,也会导致最终这个bugfix会合并develop分支中。(如果develop中的工作立即就需要这个bugfix,等不到release分支完成,那也可以将bugfix合并到develop中)
- 发布完成,hotfix 分支也可以删除了。
- 关于bugfix,可以在release分支上直接进行,也可以每个bug都可以通过一个新的临时分支来修复,修复后,合并分支,然后将临时分支删除。
下图剔除了一些说明,看起来简单些:
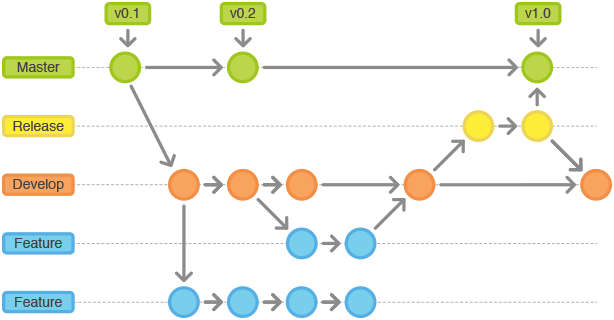
8.2 develop—release合并
总结下来:develop、release分支是分别负责版本发布流程中的feature分支集成/合并 和 测试、发布两部分。
这两个分支有两种合并方案:
- 省去release分支:在develop分支上合并feature分支、集成测试、发布准备。发布后合并master。
- 省去develop分支:版本的集成、测试、发布,都在对应的
release-*/release/xx分支上进行。如下图是据说是美团的命名示意图:
8.3 develop—release—feature合并
如果团队规模较小,每次开发功能时,基本就能确定要上线的版本号,并且功能比较耦合,几个团队成员没必要单独开辟各自的 feature/xxx 分支。
此时,就可以省略 feature 这类分支。
每次开发时,直接开辟 release/* / develop/* / daily/* 分支(*建议为版本号)。在此分支上完成开发、(中间就没有集成这一步了)、测试、发布。
九、实践中的规范
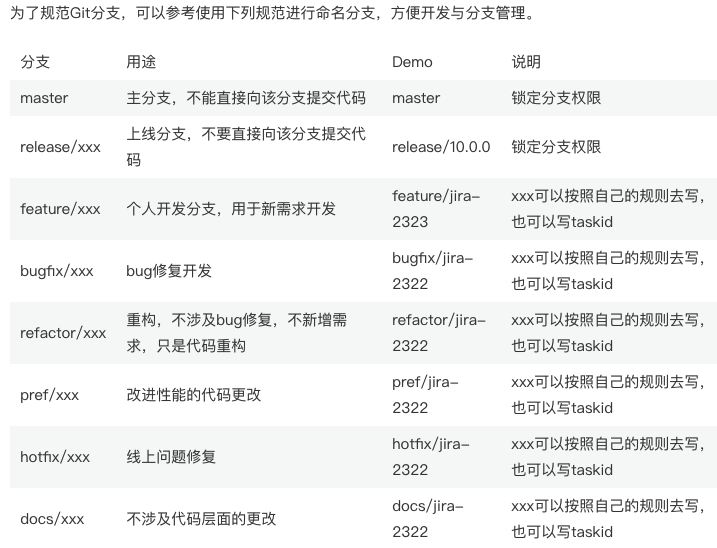
9.1 git commit 规范
commit message的前缀:
- feat - 新功能(feature)
- fix - 修改bug
- docs - 文档(documentration)
- style - 格式 (不影响代码运行的变动)
- refactor - 重构(既不是新增功能,也不是修改bug的代码变动)
- test - 增加测试
- chore - 构建过程或辅助工具的变动
- revert - 回滚
- upgrade - 第三方库升级
每次开发完后,需在changelog.md中记录详细的修改记录。
十、报错集锦
10.1 超过100M报错
超过50M警告:remote: warning: File ppt/Implementing AutoML Techniques at Salesforce Scale.pdf is 66.68 MB; this is larger than GitHub’s recommended maximum file size of 50.00 MB
超过100M报错:remote: error: GH001: Large files detected. You may want to try Git Large File Storage - https://git-lfs.github.com. 报错信息,里面提供了解决办法,就是使用 Git Large File Storage (LFS)。
Find 命令
1 | # 查找所有超过100M的文件 |
10.2 SSH调试:需要密码或直接被拒
两个现象,原因都一样:
- Permission denied (publickey)
- 一直要求输入密码
10.2.1 前提:公私钥已经配置正确
1 | $ git clone git@xxx.com |
10.2.2 SSH 调试信息
1 | $ ssh -vT git@xxx.com |
核心失败信息为:send_pubkey_test: no mutual signature algorithm
10.2.3 原因
原因:高版本OpenSSH默认不再支持ssh-rsa算法。说是该算法存在安全隐患, 具体可以看看这个新闻:OpenSSH to deprecate SHA-1 logins due to security risk | ZDNet
解决方案:
- 在
.ssh/config文件中添加PubkeyAcceptedKeyTypes +ssh-rsa配置即可 - 更换秘钥生成算法,使用 ed25519 算法生成
ssh-keygen -t ed25519 -C "your email" - 降低 OpenSSH版本
10.3 gitlab权限、角色权限造成的报错
Gitlab权限管理
Gitlab用户在组中有五种权限:Guest、Reporter、Developer、Master、Owner
- Guest:可以创建issue、发表评论,不能读写版本库
- Reporter:可以克隆代码,不能提交,QA、PM可以赋予这个权限
- Developer:可以克隆代码、开发、提交、push,RD可以赋予这个权限
- Master:可以创建项目、添加tag、保护分支、添加项目成员、编辑项目,核心RD负责人可以赋予这个权限
- Owner:可以设置项目访问权限 - Visibility Level、删除项目、迁移项目、管理组成员,开发组leader可以赋予这个权限
Gitlab中的组和项目有三种访问权限:Private、Internal、Public
- Private:只有组成员才能看到
- Internal:只有登录GitLab的用户才会看到该项目和进行克隆,未登录的用户是看不到该项目的。
- Public:所有人都能看到
在Linux服务器上,运维同事配置ssh key后操作项目,一直报错:
1 | GitLab: No such projoct |
十一、参考链接
GUI工具:
- 当我们对Git的提交、分支已经非常熟悉,可以熟练使用命令操作Git后,再使用GUI工具,就可以更高效。
- Git有很多图形界面工具,这里我们推荐SourceTree,它是由Atlassian开发的免费Git图形界面工具,可以操作任何Git库。