一、概述
1.2 汇编语言
早期的程序员发现机器语言在阅读、书写方面的问题,是如此的难以辨别和记忆,需要记住所有抽象的二进制码,为了解决这个问题,汇编语言就产生了。汇编语言是各种CPU提供的机器指令的助记符的集合,人们可以用汇编语言直接控制硬件系统进行工作。
汇编语言的主体是汇编指令。汇编指令和机器指令的差别在于指令的表示方法上。汇编指令是机器指令便于记忆的书写格式。
汇编语言与硬件关联很深,所以涉及到的知识点有很多,如:寄存器、端口、寻址方式、内外中断、以及指令的实现原理等,额,如果想了解这些知识点,可以阅读《汇编语言(第3版)》 王爽著。本篇博客类似阅读手册,主要记录一些常见的寄存器、以及不同汇编语言规范中指令的编写风格(intel及AT&T的篇幅很少,毕竟我是一个iOSer,以移动端主流ARM64汇编为例)。
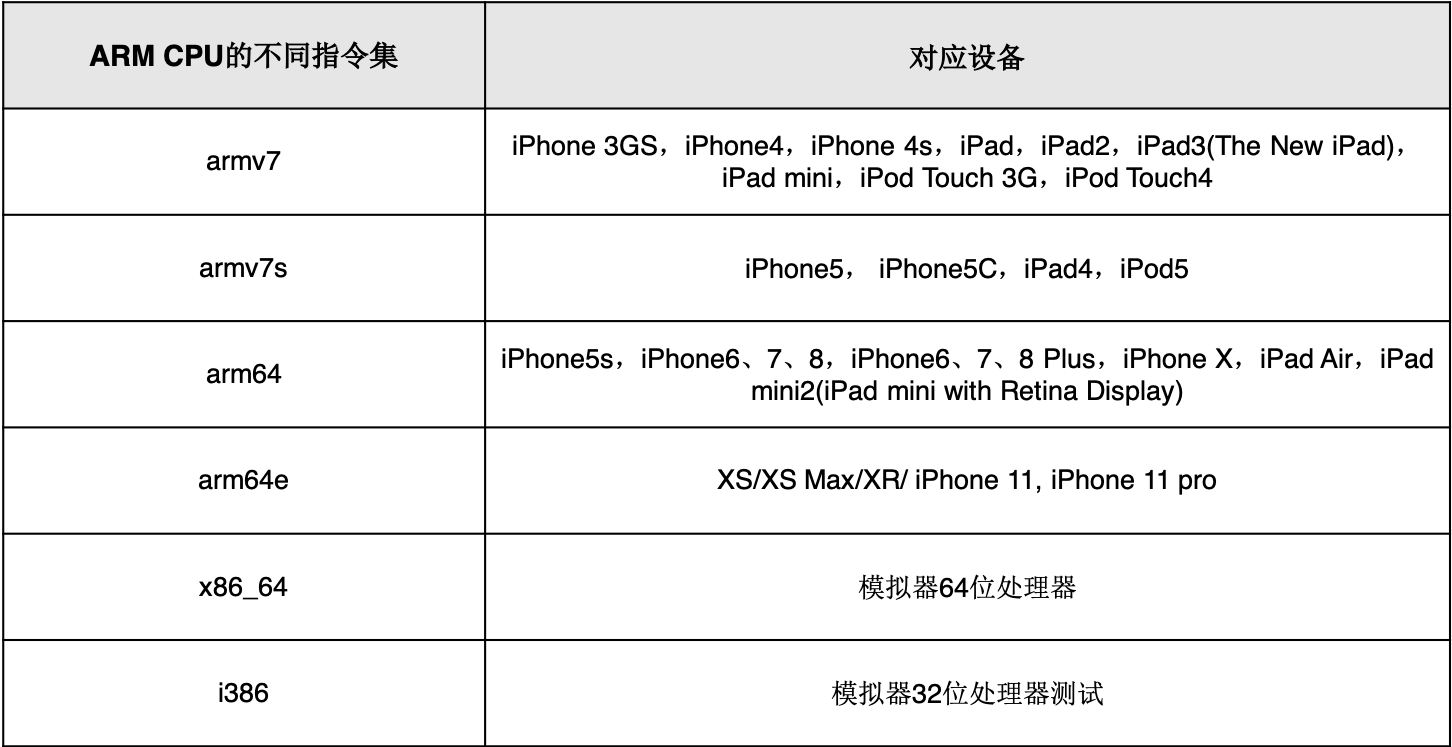
1.2 iOS相关的指令集及对应的ARM汇编语言
作为iOS开发工程师,主要需要了解的汇编语言是:
- iOS模拟器:兼容x86指令集,对应
AT&T 汇编语言规范 - iOS真机设备:兼容ARM指令集,对应
ARM 汇编语言规范
二、ARM64 汇编
- 汇编里面要学习的三个重要概念:寄存器、内存模型、指令。
- arm64架构又分为2种执行状态:
AArch64 Application Level和AArch32 Application Level(后者是为了兼容以前的32bit的程序)- AArch64执行A64指令,使用64bit的通用寄存器;
- AArch32执行A32/T32指令,使用32bit的通用寄存器;
2.1 先放代码 — Hello world
1 |
|
生成汇编文件:xcrun --sdk iphoneos clang -S -arch arm64 helloworld.c。也可以在XCode中,Product -> Perform Action -> Assemble 来生成汇编文件。
1 | __TEXT,__text,regular,pure_instructions |
汇编代码几个规则:
- 以
.(点)开头的是汇编器指令。汇编器指令是告诉汇编器如何生成机器码的,阅读汇编代码的时候通常可以忽略掉。.section __TEXT,__text,regular,pure_instructions:表示接下来的内容在生成二进制代码的时候,应该生成到Mach-O文件__TEXT(Segment)中的__text(Section);.cfi_startproc:用在每个函数的开始,用于初始化一些内部数据结构;.cfi_endproc:在函数结束的时候使用与.cfi_startproc相配套使用;.cfi_def_cfa <register>, <offset>:从寄存器中获取地址并向其添加偏移量;.cfi_offset <register>, <offset>:寄存器以前的值保存在CFA的offset偏移处;
- 以
:(冒号)结尾的是标签(Label)。代表一个地址,在需要时可以使用跳转指令跳转到标签处执行。其中,以小写字母l开头的是本地(local)标签,只能用于函数内部。
2.2 ARM中的寄存器
2.2.1 寄存器
CPU 本身只负责运算,不负责储存数据。数据一般都储存在内存之中,CPU 要用的时候就去内存读写数据。但是,CPU 的运算速度远高于内存的读写速度,为了避免被拖慢,CPU 都自带一级缓存和二级缓存。基本上,CPU 缓存可以看作是读写速度较快的内存。
但是,CPU 缓存还是不够快,另外数据在缓存里面的地址是不固定的,CPU 每次读写都要寻址也会拖慢速度。因此,除了缓存之外,CPU 还自带了寄存器(register),用来储存最常用的数据。也就是说,那些最频繁读写的数据(比如循环变量),都会放在寄存器里面,CPU 优先读写寄存器,再由寄存器跟内存交换数据。
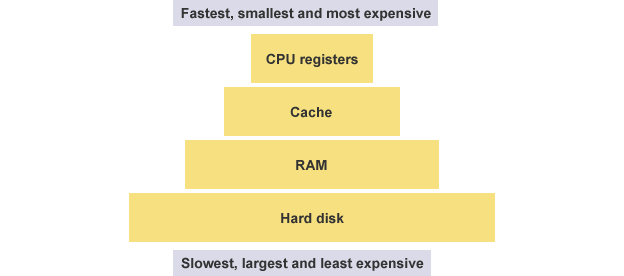
寄存器不依靠地址区分数据,而依靠名称。每一个寄存器都有自己的名称,我们告诉 CPU 去具体的哪一个寄存器拿数据,这样的速度是最快的。有人比喻寄存器是 CPU 的零级缓存。
这里介绍一下arm64常见的一些寄存器:
- 通用寄存器 31个:x0-x30,64位
- 浮点寄存器 32个:v0-v31,128位
- 特殊寄存器:ZR、SP、PC、SPRs
2.2.2 通用寄存器x0 – x30
x0 - x30 是31个通用整形寄存器。每个寄存器可以存取一个64位大小的数。 当使用 x0 - x30 访问时,它就是一个64位的数。当使用 w0 - w30 访问时,访问的是这些寄存器的低32位,如图:

为了函数调用的目的,通用寄存器分为四组(官网文档):
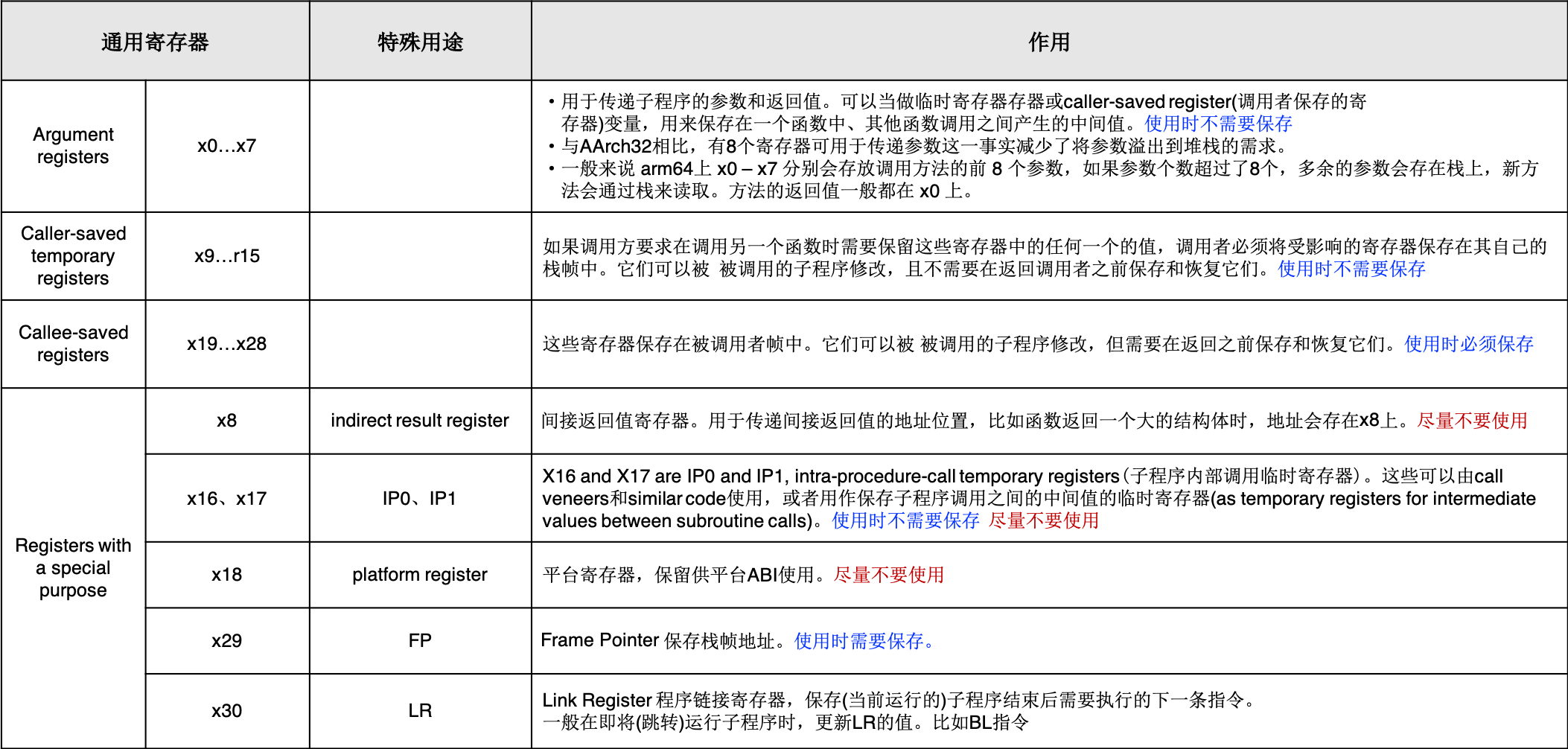
- 注意,但参数过多、返回值过大时,比如是个成员很多的结构体,通用x0-x7不够用,会通过栈来传递
2.2.3 一些特殊寄存器
ZR
zero register 零寄存器,与通用寄存器一样,x、w分别代表64/32位(XZR/WZR),作用就是0,写进去代表丢弃结果,拿出来是0.
SP
Stack Pointer 保存栈指针。在指令编码中,使用 SP/WSP来进行对SP寄存器的访问。
PC
程序计数器,俗称PC指针,总是指向即将要执行的下一条指令。在arm64中,软件是不能改写PC寄存器的。
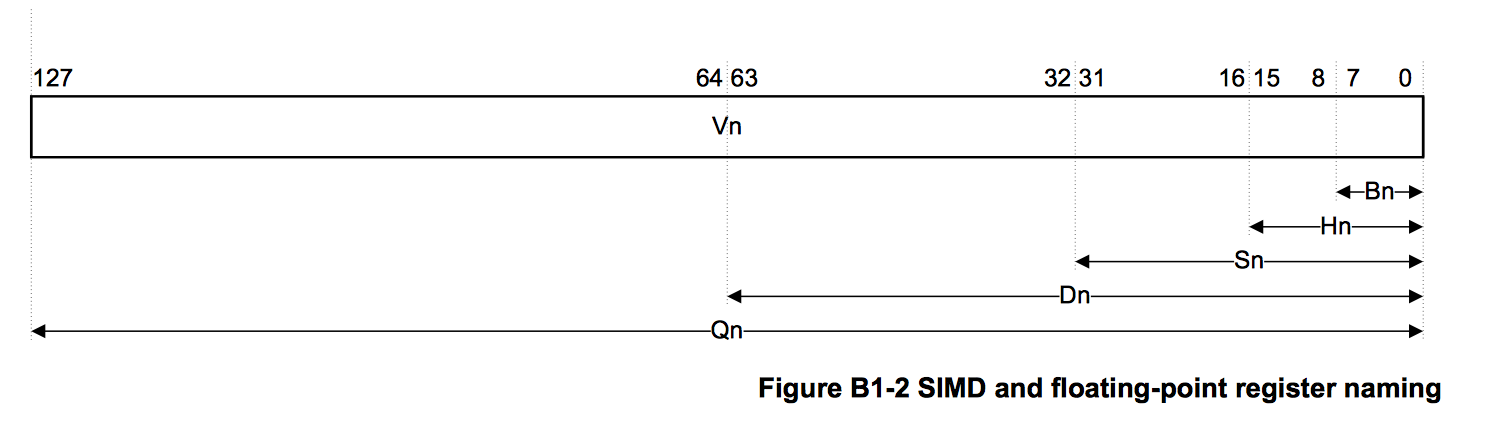
V0 – V31
向量寄存器,也可以说是浮点型寄存器。它的特点是每个寄存器的大小是 128 位的。 分别可以用 Bn Hn Sn Dn Qn 的方式来访问不同的位数。可以这样理解记忆,基于一个word是32位,也就是4Byte大小:
- Bn:一个Byte的大小
- Hn:half word. 就是16位
- Sn:single word. 32位
- Dn:double word. 64位
- Qn:quad word. 128位
程序状态寄存器
状态寄存器,用于存放程序运行中一些状态标识。不同于编程语言里面的if else。在汇编中就需要根据状态寄存器中的一些状态来控制分支的执行。状态寄存器又分为
- The Current Program Status Register (CPSR)
- The Saved Program Status Registers (SPSRs)
一般都是使用 CPSR ,当发生异常时,CPSR 会存入 SPSR 。当异常恢复,再拷贝回 CPSR。
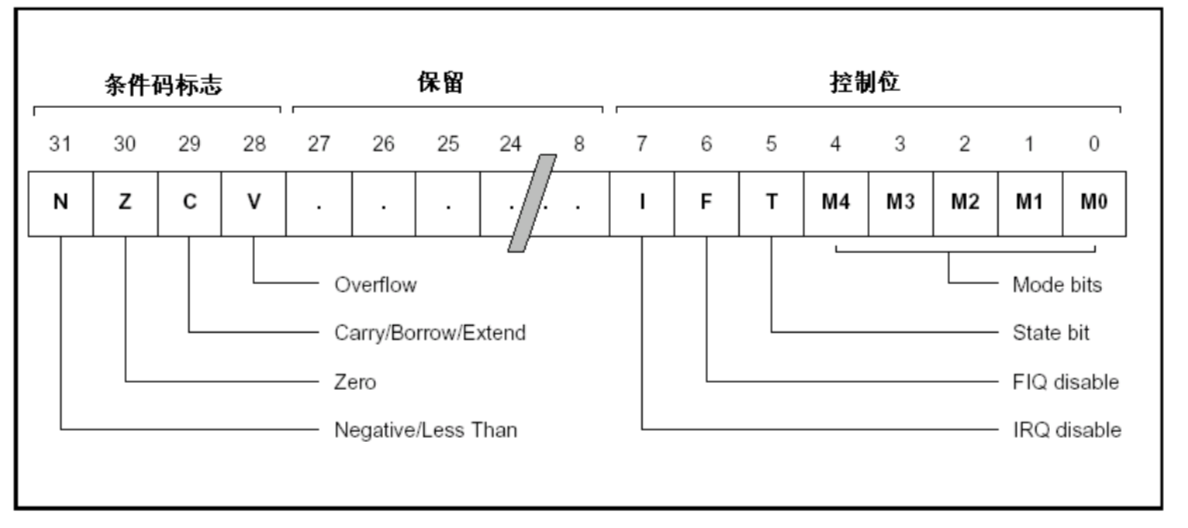
不同于其他寄存器,其他寄存器是用来存放数据的,都是整个寄存器具有一个含义。而CPSR寄存器是按位起作用的,也就是说,它的每一位都有专门的含义,记录特定的信息。
- CPSR寄存器是32位的
- CPSR的低8位(包括I、F、T和M[4:0])称为
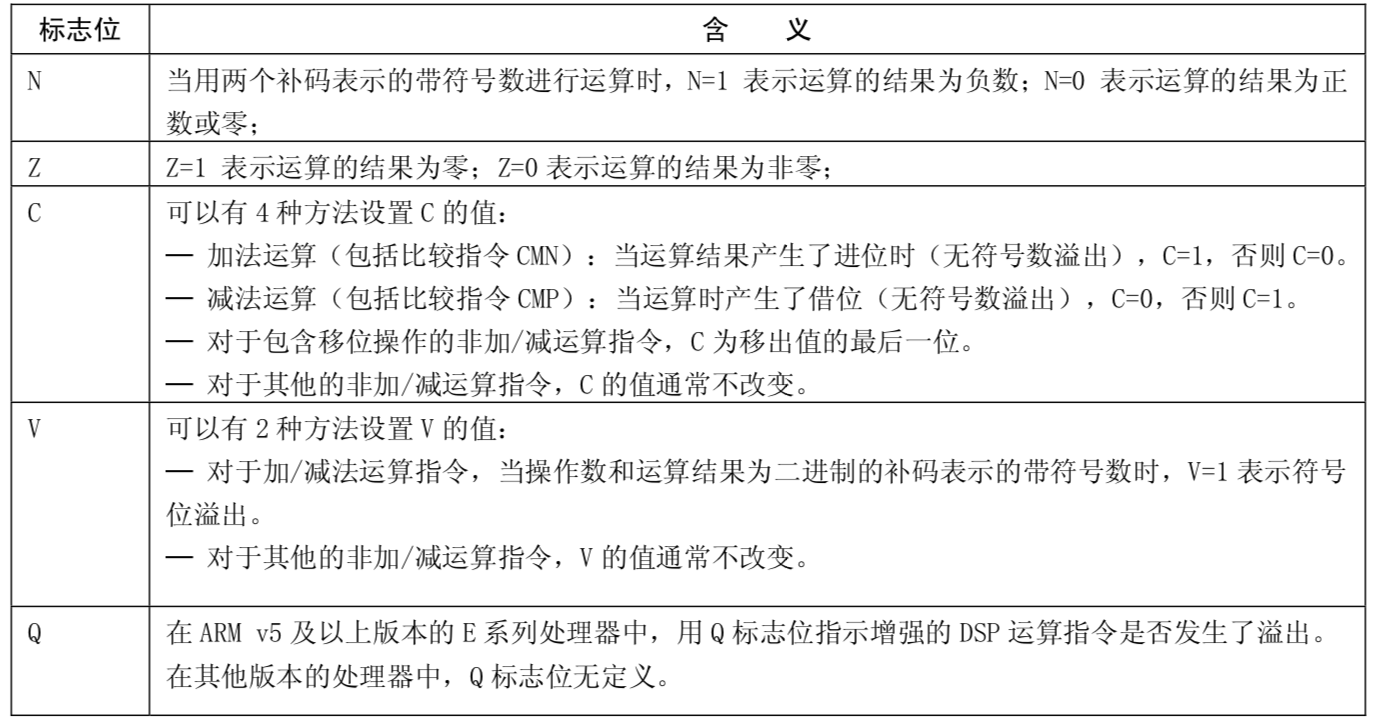
控制位,程序无法修改,除非CPU运行于特权模式下,程序才能修改控制位。 - N、Z、C、V均为
条件标志位,分别代表运算过程中产生的状态。它们的内容可被算术或逻辑运算的结果所改变,并且可以决定某条指令是否被执行。
还有一些系统寄存器,如 FPSR FPCR是浮点型运算时的状态寄存器等。基本了解上面这些寄存器就可以了。
2.3 ARM指令的使用格式
ARM作为精简指令集(RISC),所有 ARM 指令(RISC)的长度都是 32 位。行成对比的是复杂指令集(CISC,如x86),指令长度不同,最长的指令长达15 bytes,等于120位。
ARM指令使用的基本格式如下:<opcode>{<cond>}{S} <Rd>,<Rn>,{<operand2>}
- Opcode:操作码;指令助记符,如LDR、STR等。
- Cond:可选的条件码;执行条件,如EQ、NE等。
- S:可选后缀;若指定S,则根据指令执行结果更新CPSR中的条件码
- Rd:目标寄存器
- Rn:存放在第1操作数的寄存器。
- operand2:第2个操作数。
- “< >”:“< >”内的项是必需的,例如,
是指令助记符,这是必须书写的。 - “{ }”:“{ }”内的(ˇˍˇ) 项是可选的,例如,{< code>}为指令执行条件,是可选项。若不书写,则使用默认条件AL(无条件执行)。
有几个注意点:
- 寄存器:为标号,不加前缀(ARM汇编中,标号就是一个符号,代表着汇编程序中指令或数据的内存地址)
- 操作数顺序:目标操作数在左,源操作数在右
- 立即数:前加#作为前缀
- 寻址格式:
1
2
3
4
5
6
7
8
9
10
11
12;寻址格式:
[x10, #0x10] ; signed offset。意思是从 x10 + 0x10的地址取值
[sp, #-16]! ; pre-index。意思是从 sp-16地址取值,取值完后在把 sp-16 writeback 回 sp
; ! 表示寄存器写回,如果没有!,那么只会从 sp-16 地址读写值,而不会修改 sp 的值
[sp], #16 ; post-index。意思是从 sp 地址取值,取值完后在把 sp+16 writeback 回 sp
;举例:
ldr x0, [x1] ; 从`x1`指向的地址里面取出一个 64 位大小的数存入 `x0`
ldp x1, x2, [x10, #0x10] ; 从 x10 + 0x10 指向的地址里面取出 2个 64位的数,分别存入x1, x2
str x5, [sp, #24] ; 把x5的值(64位数值)存到 sp+24 指向的内存地址上
stp x29, x30, [sp, #-16]! ; 把 x29, x30的值存到 sp-16的地址上,并且把 sp-=16.
ldp x29, x30, [sp], #16 ; 从sp地址取出 16 byte数据,分别存入x29, x30. 然后 sp+=16;
除此之外,还有两种地址表示方式(相对寻址):
程序相对地址(程序相对的表达式):是命名寄存器的值加上或减去一个数字常数寄存器相对地址(寄存器相对的表达式):表示为相对当前程序计数器 (PC) 的偏移量。它通常是标签与数字
表达式的组合(如ADR指令)
2.4 ARM常用指令
ARM处理器的指令集可以分为跳转指令、数据处理指令、程序状态寄存器(PSR)处理指令、加载/存储指令、协处理器指令和异常产生指令6大指令。
由于篇幅原因,只列举了常用的一些,可以正常阅读汇编代码即可。更多的可以跳转ARM64指令简易手册查阅。全面的可以查看ARM官网文档。如果想看中文版的资料可以看《汇编器指南》— 第二章、第四章
2.4.1 数据处理指令
1 | MOV X1,X0 ; 将寄存器X0的值传送到寄存器X1。MOV:从另一个寄存器、被移位的寄存器或将一个立即数加载到目的寄存器。 |
ARM指令中,不支持将立即数直接写入内存,需要先通过mov写入寄存器,然后通过str将寄存器中的值存储进内存
2.4.2 寄存器加载/存储指令
1 | LDR X5,[X6,#0x08] ; ld(load): X6寄存器加0x08的和的地址值内的数据传送到X5 |
2.4.3 跳转和控制指令
1 | CBZ ; 比较(Compare),如果结果为零(Zero)就转移(只能跳到后面的指令) |
2.4.4 异常产生指令
1 | SWI(Software Interrupt) ; 软件中断指令。用于产生软中断,从而实现处理器从用户模式变换到管理模式,CPSR保存到管理模式的SPSR中,执行转移到SWI向量,在其他模式下也可以使用SWI指令,处理器同样切换到管理模式。 |
2.5 ARM指令的二进制编码
2.5.1 对应的二进制编码格式
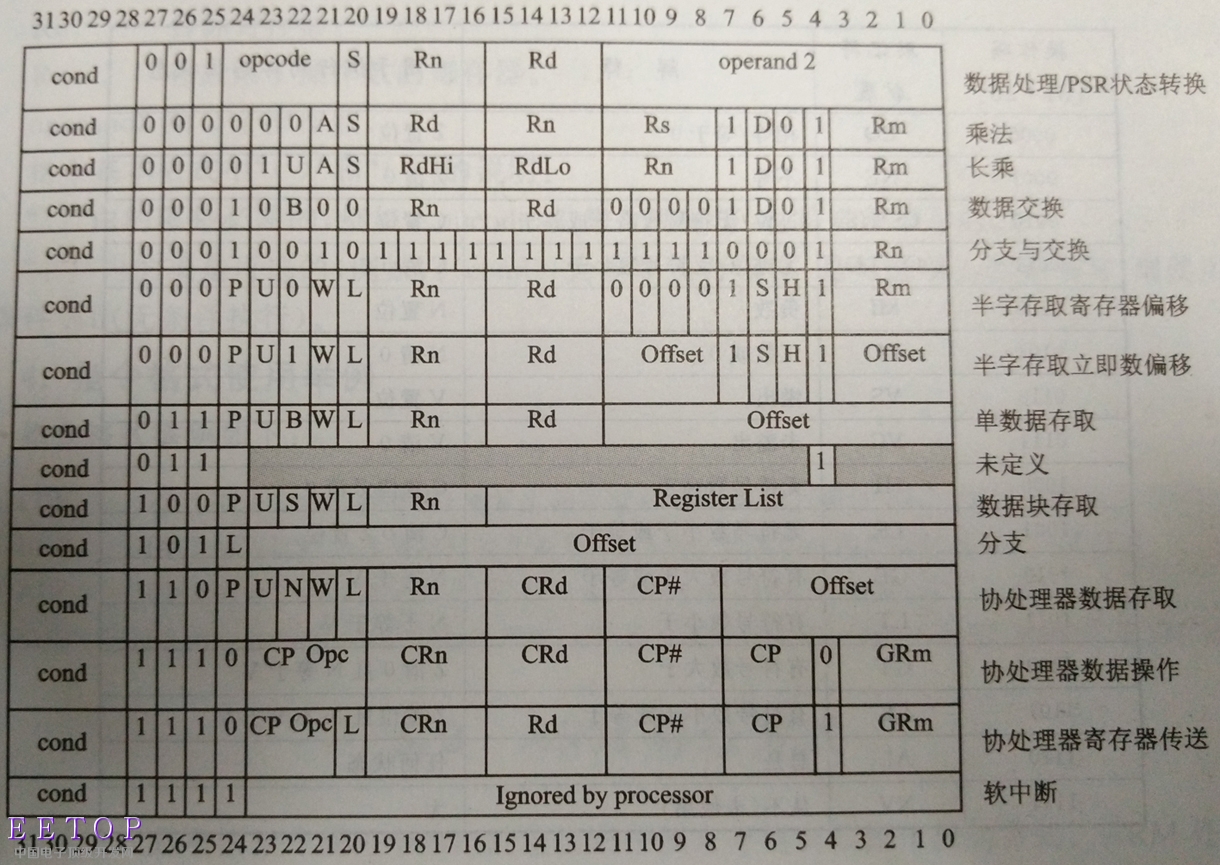
ARM指令集是以32位二进制编码的方式给出的,大部分的指令编码中定义了第一操作数、第二操作数、目的操作数、条件标志影响位以及每条指令所对应的不同功能实现的二进制位。每条32位ARM指令都具有不同的二进制编码方式,与不同的指令功能相对应。
如图所示表示了ARM指令集编码:
2.5.2 条件执行
ARM指令的一个重要特点就是所有指令都是带有条件的,就是说汇编中可以根据状态寄存器中的一些状态来控制分支的执行。
在ARM的指令编码表中,统一占用编码的最高4位[31:28]来表示条件码。每种条件码用两个英文缩写字符表示其含义,可添加在指令助记符的后面,表示指令执行时必须要满足的条件。ARM指令根据CPSR中的条件位自动判断是否执行指令。在条件满足时,指令执行;否则,指令被忽略。
例如,数据传送指令MOV加上条件后缀EQ后成为MOVEQ,表示“相等则执行传送”,“不相等则本条指令不执行”,即只有当CPRS中的Z标志为1时,才会发生数据传送。ARM指令集编码表列举了4位条件码的16种编码中能为用户所使用的15种,而编码1111为系统暂不使用的保留编码。
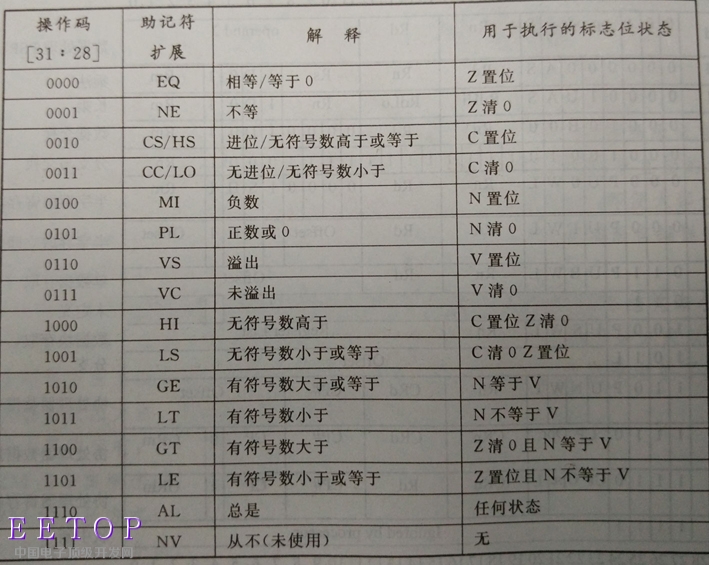
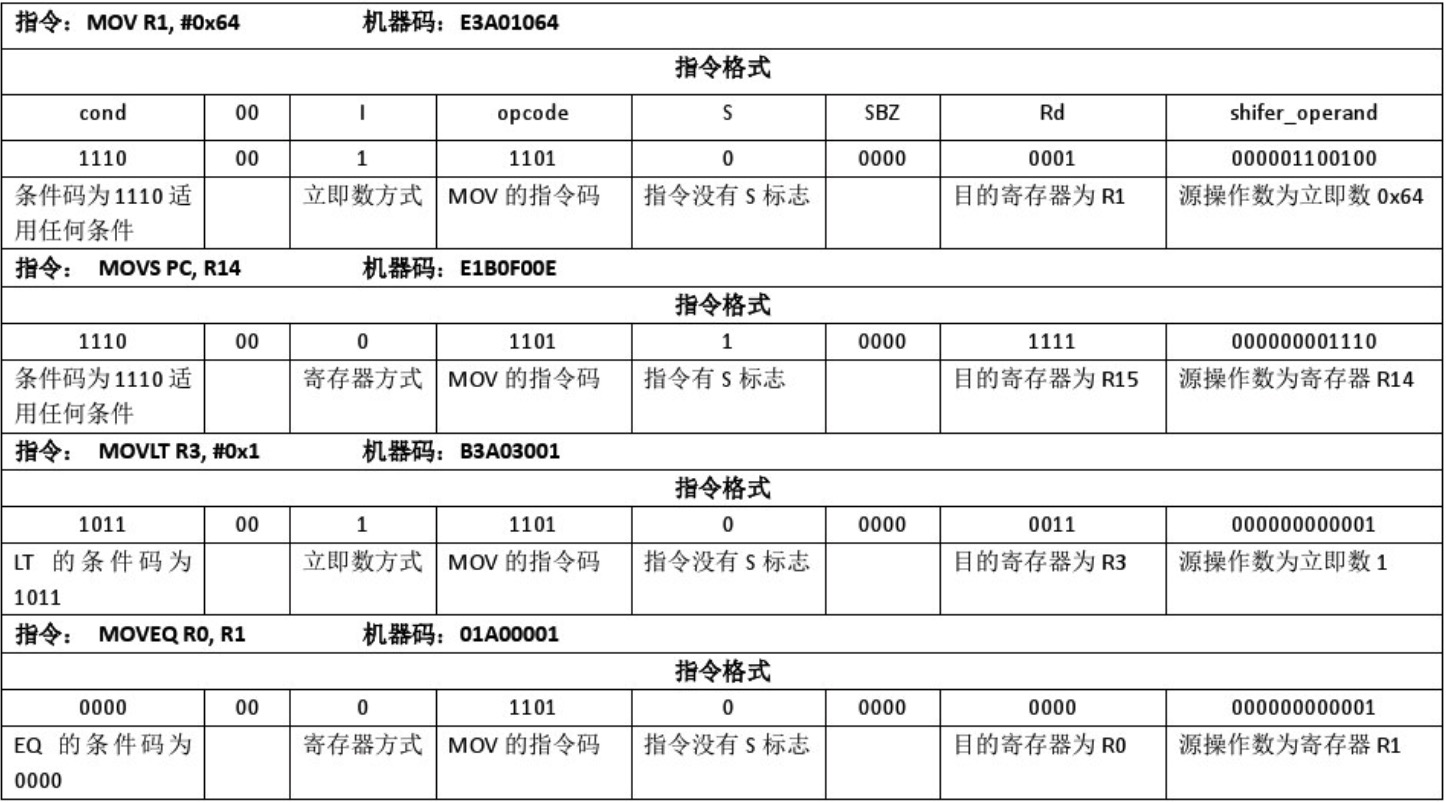
看下面几行汇编指令:
1 | cmp x2, #0 ; x2 - 0 = 0。 状态寄存器标识zero: PSTATE.NZCV.Z = 1 |
三、函数调用栈
先简单再说一下内存模型:
3.1 堆
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从 0x1000 到 0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。
程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址 0x1000 开始给他分配,一直分配到地址 0x100A ,如果再要求得到22个字节,那么就分配到 0x1020。
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
3.2 栈
Stack 是由于函数运行而临时占用的内存区域。或者说栈是指令执行时存放临时变量的内存空间。一个函数对应一帧,
fp指向当前frame的栈底,sp指向栈顶
1 | int main() { |
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
如果函数内部调用了其他函数,会发生什么情况?
1 | int main() { |
上面代码中,main函数内部调用了add_a_and_b函数。执行到这一行的时候,系统也会为add_a_and_b新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_a_and_b。一般来说,调用栈有多少层,就有多少帧。
等到add_a_and_b运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做”入栈”,英文是 push;栈的回收叫做”出栈”,英文是 pop。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做”后进先出”的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
注意:
- Stack 是由内存区域的结束地址开始,
从高位(地址)向低位(地址)分配。- 栈顶置针向低移动,就是分配临时存储空间,栈顶置针向高移动,就是释放临时存储空间。
- 比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
- 栈中一个数据所分配到的内存中,存储(读取)数据时,是
从低位(地址)向高位(地址)读写的。即栈中数据的打印地址(起始地址)与堆中一样,是低地址开始。- 情况一:见下面代码块中的
stp、ldp。 - 情况二:复合类型,如创建一个结构体局部变量,打印成员变量,会发现是从低地址向高地址依次打印出来的
- 注意:基本数据类型的存储,还涉及到
大端、小端字节序的概念,即指高位字节在前(后)。
- 情况一:见下面代码块中的
- 补充:复合数据类型都是由基本数据类型组成的,基本数据类型的存储不会带来空闲(冗余)空间的:
- char类型的数据值为单个字符,ASCII码值对应为0-255,正好一个字节存储。
- int类型,比如int = 1,int占4字节,存的时候会存0x00000001,即会转成8位的16进制表示存储,占满4字节
- 冗余空间的产生,往往是因为一些比如对齐之类的存储策略造成的
下面的图简单的描述了 main 调用方法 printf 时,栈是如何划分的:

下面是方法的调用过程,分别对应方法头、方法尾:
1 | ; x29就是fp, x30就是lr |
总结:
- 方法头、尾的作用就是调用前保存程序状态,调用后恢复程序状态。
- 如果一个函数内部没有其他函数调用,也就没有这几行方法头、尾了,比如一个最简单的程序如:
1 | /* |
关于参数及返回值的传递,具有以下规则(赘述一遍,前面讲寄存器时提过):
- 当函数参数个数小于等于8个的时候,x0-x7依次存储前8个参数
- 参数个数大于8个的时候,多余的参数会通过栈传递
- 方法通常通过x0返回数据,如果返回的数据结构较大,则通过x8将数据的地址进行返回(寄存器最大为8字节,超过8字节的返回值,一个寄存器就传递不了了)
- 在Intel 32位汇编中:
- 小于等于4字节,函数将返回值存储在eax中(32位机器,eax本身只有4个字节)
- 5~8字节,几乎所有的调用惯例(调用约定)都是采用eax和edx 联合返回的方式进行的,eax存储返回值的低4字节,edx存储返回值的高4字节
- 大于8字节,在栈上临时开辟一块内存区域作为中转,eax返回数据的地址。返回时,先将值写入到这一块指定的栈内存,外部程序使用时再读取,多了两次内存读写,造成额外开销。(参考《程序员的自我修养—第10章内存》)
3.3 Stack backtrace与符号化
栈回溯对代码调试和crash定位有很重大的意义,通过之前几个步骤的图解,栈回溯的原理也相对比较清楚了。
- 通过当前的SP,FP可以得到当前函数的stack frame,通过PC可以得到当前执行的地址。
- 在当前栈的FP上方,可以得到Caller(调用者)的FP,和LR。通过偏移,我们还可以获取到Caller的SP。由于LR保存了Caller下一条指令的地址,所以实际上我们也获取到了Caller的PC
- 有了Caller的FP,SP和PC,我们就可以获取到Caller的stack frame信息,由此递归就可以不获取到所有的Stack Frame信息。
下面这个网图(BSBackTracelogger学习笔记)挺详细的:
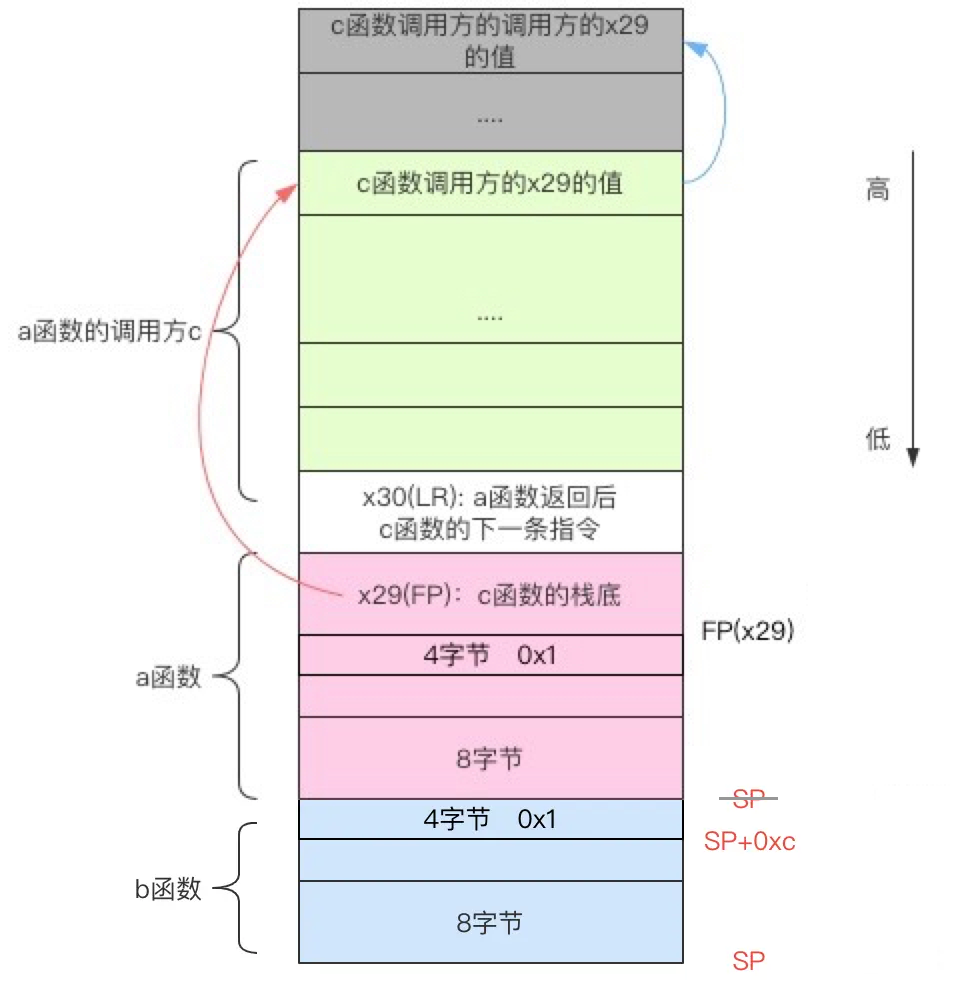
c函数调用a函数是一个入栈出栈的过程,调用开始的时候入栈,同时需要保存c函数的FP(x29)和LR(x30)在a函数的FP和FP+8的位置,即当前函数a的FP位置保存的就是调用方的FP位置,a函数调用结束时返回到LR的位置继续执行下一条指令,而这条指令属于c函数,因此我们可以 通过FP来建立整个调用链的关系,通过LR来确认调用方函数的符号。
尽管如此,有两种情况是获取不到调用堆栈的,一种是尾调用优化,一种是内联函数。
栈回溯的过程中,我们拿到的是函数的地址,又是如何通过函数地址获取到函数的名称和偏移量的呢?
- 对于系统的库,比如
CoreFoundation我们可以直接通过系统的符号表拿到 - 对于自己代码,则依赖于编译时候生成的dsym文件。
这个过程我们称之为 symbolicate ,对于iOS设备上的crash log,我们可以直接通过XCode的工具 symbolicatecrash 来符号化:
1 | cd /Applications/Xcode.app/Contents/SharedFrameworks/DVTFoundation.framework/Versions/A/Resources |
当然,可以用工具 dwarfdump 去查询一个函数地址:
1 | dwarfdump --lookup 0x000000010007528c -arch arm64 1.dSYM |
四、内联汇编
用汇编编写的程序虽然运行速度快,但开发速度非常慢,效率也很低。如果只是想对关键代码段进行优化,或许更好的办法是将汇编指令嵌入到 C 语言程序中,从而充分利用高级语言和汇编语言各自的特点。但一般来讲,在 C 代码中嵌入汇编语句要比”纯粹”的汇编语言代码复杂得多,因为需要解决如何分配寄存器,以及如何与C代码中的变量相结合等问题。
4.1 格式
4.1.1 格式说明
GCC 提供了很好的内联汇编支持。最基本的格式是:
1 | __asm__("asm statements"); |
例如:
1 | __asm__("nop"); |
通常嵌入到 C 代码中的汇编语句很难做到与其它部分没有任何关系,因此更多时候需要用到完整的内联汇编格式:
1 | /* |
插入到 C 代码中的汇编语句是以”:”分隔的四个部分:
- 第一部分是汇编代码本身,通常称为指令部,其格式和在汇编语言中使用的格式基本相同。指令部分是必须的,而其它部分则可以根据实际情况而省略。
- 在将汇编语句嵌入到C代码中时,操作数如何与C代码中的变量相结合是个很大的问题。
- GCC采用如下方法来解决这个问题:
- 程序员提供具体的指令,而对寄存器的使用则只需给出”样板”和约束条件就可以了,具体如何将寄存器与变量结合起来完全由GCC和GAS来负责。
- 汇编语句中,用到的操作数从输出部的第一个约束开始编号,序号从0开始,每个约束记数一次。在GCC内联汇编语句的指令部中,只需在序号前,加上前缀
%(如%0,%1),表示的就是需要使用寄存器的”样板”操作数。 - 指令部中使用了几个样板操作数,就表明有几个变量需要与寄存器相结合,这样GCC和GAS在编译和汇编时会根据后面给定的约束条件进行恰当的处理。
- 由于样板操作数也使用’ %’作为前缀,因此在涉及到具体的寄存器时,寄存器名前面应该加上两个
%,以免产生混淆。
- 紧跟在指令部后面的是输出部,是规定输出变量如何与样板操作数进行结合的条件,每个条件称为一个“约束”,必要时可以包含多个约束,相互之间用逗号分隔开就可以了。
- 每个输出约束都以’=’号开始,然后紧跟一个对操作数类型进行说明的字后,最后是如何与变量相结合的约束。
- 与输出部中说明的操作数相结合的寄存器或操作数本身,在执行完嵌入的汇编代码后均不保留执行之前的内容,这是GCC在调度寄存器时所使用的依据。
- 输出部后面是输入部,输入约束的格式和输出约束相似,但不带’=’号。
- 如果一个输入约束要求使用寄存器,则GCC在预处理时就会为之分配一个寄存器,并插入必要的指令将操作数装入该寄存器。
- 与输入部中说明的操作数相结合的寄存器或操作数本身,在执行完嵌入的汇编代码后也不保留执行之前的内容。
- 有时在进行某些操作时,除了要用到进行数据输入和输出的寄存器外,还要使用多个寄存器来保存中间计算结果,这样就难免会破坏原有寄存器的内容。在GCC内联汇编格式中的最后一个部分中,可以对将产生副作用的寄存器进行说明,以便GCC能够采用相应的措施。
4.1.2 举例(旧版本)
下面是一个内联汇编的简单例子:
1 | /* inline.c |
4.1.3 举例(新版本)
下面的汇编代码是从GCC 3.1版本开始才支持的,而在此之前一直是上面的形式。上述0%和1%分别表示第一个、第二个操作数。GCC的最新版本仍然支持上述语法,但明显,上述语法更容易出错,且难以维护:假设你写一个较长的内联汇编,然后需要在某个位置插入一个新的输出操作数,此时,之后的操作数都需要重新编号。
新版本:
- 人为指定每个输出数的符号名,用方括号包围,后面跟一个约束串,然后再加上一个括号包围的C表达式,这个括号里的符号就是C语言代码中的变量。
1 | asm( |
4.2 约束符与约束修饰符
需要注意的是,内联汇编语句的指令部在引用一个操作数时总是将其作为32位的长字使用,但实际情况可能需要的是字或字节,因此应该在约束中指明正确的限定符:
| 限定/约束符 | 意义 |
|---|---|
| “m”、”v”、”o” | 内存单元 |
| “r” | 通用寄存器 |
| “q” | 寄存器eax、ebx、ecx、edx之一 |
| “i”、”h” | 直接操作数 |
| “E”和”F” | 浮点数 |
| “g” | 任意 |
| “a”、”b”、”c”、”d” | 分别表示寄存器eax、ebx、ecx和edx |
| “S”和”D” | 寄存器esi、edi |
| “I” | 常数(0至31) |
| 约束修饰符 | 意义 |
|---|---|
| 无 | 被修饰的约束符是只读的 |
| = | 被修饰的约束符是只写的。通常用于所有输出操作数的属性 |
| + | 被修饰的约束符是可读写的。只能被列为输出操作数的属性,否则编译会报错。 |
| & | 被修饰的约束符只能作为输出 |
4.3 应用
题目:NSLog(@”Hello World”) 在这行代码上边加一行代码,让函数输出Goodbye World
1
2
3
4
5
6
7
8int main() {
__asm__("mov X0, %[xxx]\n"
"b 0xc \n"
:
:[xxx]"r"(@"Goodbye world")
:);
NSLog(@"Hello World");
}
五、汇编层次看高级语言
汇编层面上只有寄存器、内存及数据(地址(无符号整数)、数字(定点、浮点)、字符、逻辑数)
- 指针:本质上就是一个变量的地址。
- 结构体:本质上就是按照一定规则分配的连续内存。
- 结构体作为参数时,将成员通过连续的通用寄存器或者浮点型寄存器传入。当结构体过大(
成员过多、复杂)的时候,作为参数和返回值时,通过栈来传递,这一点和函数的参数个数过多的时候类似。 - 举例:当使用printf直接打印
结构体变量时(一般不这么使用,而是打印结构体.成员变量),不是直接打印地址,而是打印成员。前面有多少个打印字符,就会打印出多少个成员变量的值。(如果打印字符多于成员数,会打印出一些随机的东西)
- 结构体作为参数时,将成员通过连续的通用寄存器或者浮点型寄存器传入。当结构体过大(
- 数组:
- 数组作为函数参数的时候,是以指针的方式传入的,比如这个例子中,是把sp+12Byte的地址作为参数放到x0中,传递给logArray函数的。
- 初始化数组的变量是存储在代码段的常量区,
.section __TEXT,__const - 在编译过后,会在变量区域的上下各插入一个
___stack_chk_guard,在方法执行完毕后,检查栈上的___stack_chk_guard是否被修改过了,如果被修改过了报错。
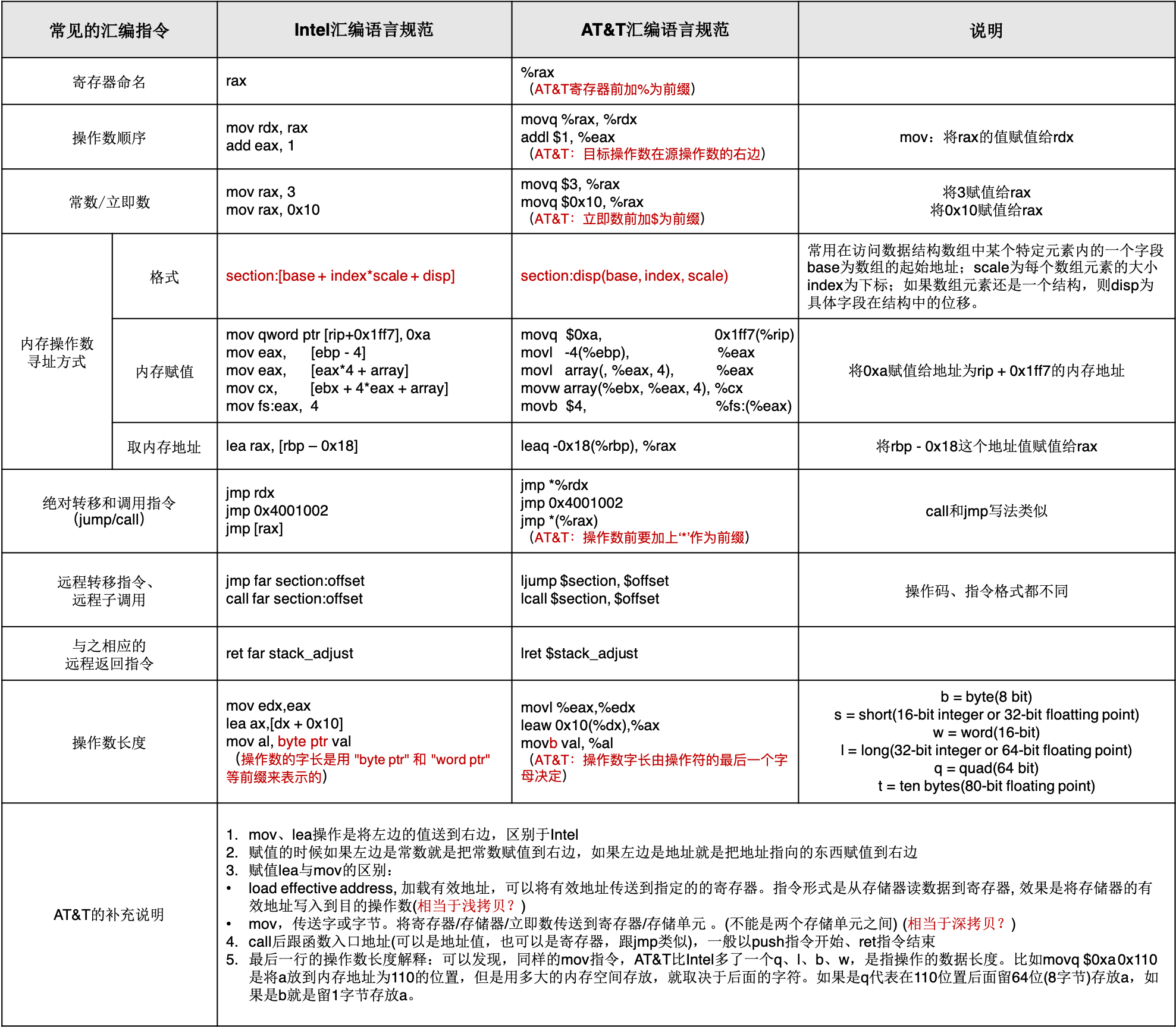
六、intel、AT&T汇编的简单对比了解