
上一篇说到源码经过预处理、编译、汇编之后生成目标文件,这一章介绍一下iOS、Mac OS中目标文件的格式Mach-O的结构,方便了解之后的链接生成可执行文件的过程。
先附上相关源码地址:与Mach-O 文件格式有关的结构体定义都可以从 /usr/include/mach-o/loader.h 中找到(直接在xcode项目中找到loader.h,然后Show In Finder即可)。
一、进程与二进制格式
进程在众多操作系统中都有提及,它是作为一个正在执行的程序的实例,这是 UNIX 的一个基本概念。而进程的出现是特殊文件在内从中加载得到的结果,这种文件必须使用操作系统可以认知的格式,这样才对该文件引入依赖库,初始化运行环境以及顺利地执行创造条件。
Mach-O(Mach Object File Format)是 macOS 上的可执行文件格式,类似于 Linux 和大部分 UNIX 的原生格式 ELF(Extensible Firmware Interface)。macOS 支持三种可执行格式:解释器脚本格式、通用二进制格式和 Mach-O 格式(关于三者区别,在下面说到Mach-O Header的时候介绍)。
二、相关工具
命令行工具
- file 命令,查看Mach-O文件的基本信息:
file 文件路径 - otool 命令,查看Mach-O特定部分和段的内容
1
2
3
4
5
6
7
8
9
10#查看Mach-O文件的header信息
otool -h 文件路径
#查看Mach-O文件的load commands信息
otool -l 文件路径
#查看Mach-O文件所使用到的动态库
otool -L 文件路径
# 更多使用方法,终端输入otool -help查看 - lipo 命令,来处理多架构Mach-O文件,常用命令如下
1
2
3
4
5
6
7
8#查看架构信息
lipo -info 文件路径
#导出某种类型的架构
lipo 文件路径 -thin 架构类型 -output 输出文件路径
#合并多种架构类型
lipo 文件路径1 文件路径2 -output 输出文件路径 - nm命令,llvm提供,可以查看目标文件符号表里的内容:符号、对应的地址、符号的一些修饰符。
1
2OVERVIEW: llvm symbol table dumper
USAGE: nm [options] <input files>
GUI工具
- MachOView:文件浏览。MachOView官网
- Hopper Disassembler、IDA Pro:反汇编工具
三、Mach-O 文件格式
Mach-O 文件格式在官方文档中有一个描述图,很多教程中都引用到。官网文档
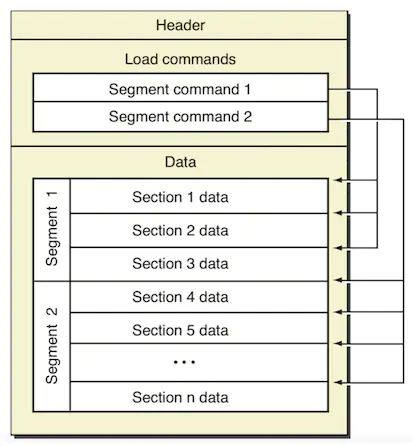
可以看的出 Mach-O 主要由 3 部分组成,下面一一讲述。
3.1 示例
用 helloworld 来做个试验:
1 | /// main.cpp |
使用 clang -g main.cpp -o main 生成执行文件。然后拖入到 MachOView 中来查看一下加载 Segment 的结构(当然使用 Synalyze It! 也能捕捉到这些信息的,但是 MachOView 更对结构的分层更加一目了然):
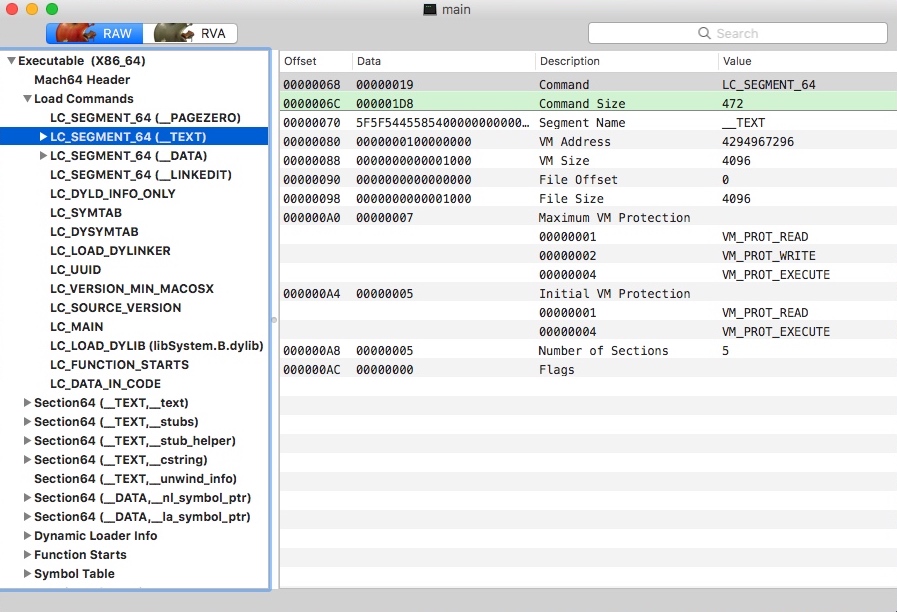
3.2 Mach-O 头
Mach-O 头(Mach Header)描述了 Mach-O 的 CPU 架构、大小端、文件类型以及加载命令等信息。它的作用是让内核在读取该文件创建虚拟进程空间的时候,检查文件的合法性以及当前硬件的特性是否能支持程序的运行。
以下只给出 64 位定义的代码,因为 32 位的区别是缺少了一个预留字段:
1 |
|
魔数会表明文件的格式。filetype会表明具体是什么文件类型(都是猫,也分黑猫、白猫)。
1 | // magic:常见的魔数(Mac是小端模式) |
举例:利用otool工具查看Mach-o文件的头部
1 | $ otool -hv bibi.decrypted |
3.3 Load Command
概述
Mach-O文件头中包含了非常详细的指令,这些指令被称为“加载指令”,在被调用时清晰地指导了如何设置并加载二进制数据。
- Load Command的最终目标只有一个,就是:指导内核加载器、动态链接器怎么将可执行文件装载到内存进行执行。
- 每条命令都会描述其指向(或者是结构体中直接包含的)的数据是什么类型、数据的大小、用途等,内核加载器/动态链接器拿到这些数据之后,需要去做相应的处理。详细可见下面图片中命令 - 用途的说明。
这些指令,或称为“加载命令”,紧跟在基本的mach_header之后。
每一条命令,在load.c文件中,都有对应的结构体,来记录信息。共同点是都采用“类型-长度-值”的格式:
1 | struct xxx_command { |
有一些命令是由内核加载器(定义在bsd/kern/mach_loader.c文件中) 直接使用的, 其他命令是由动态链接器处理的。
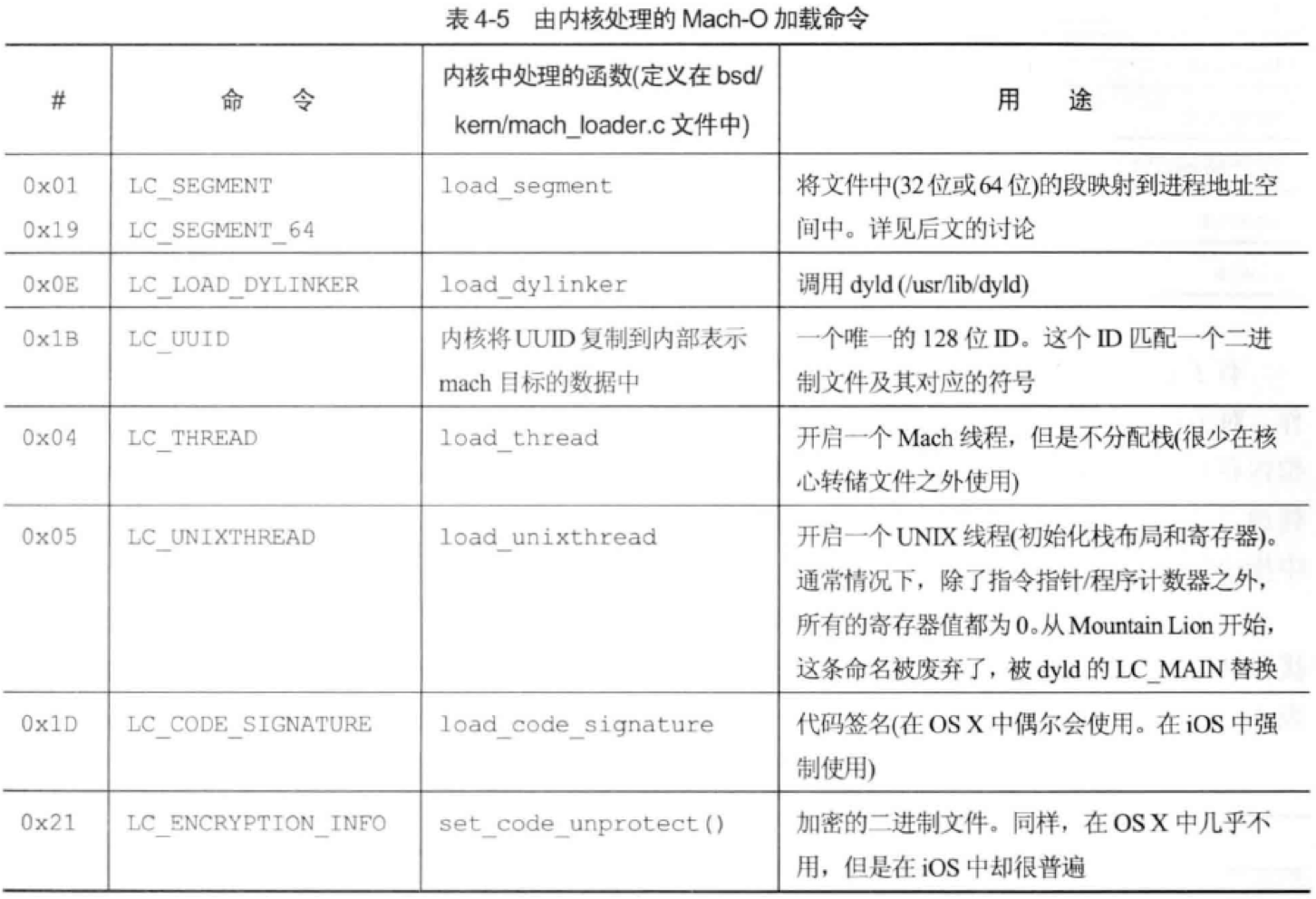
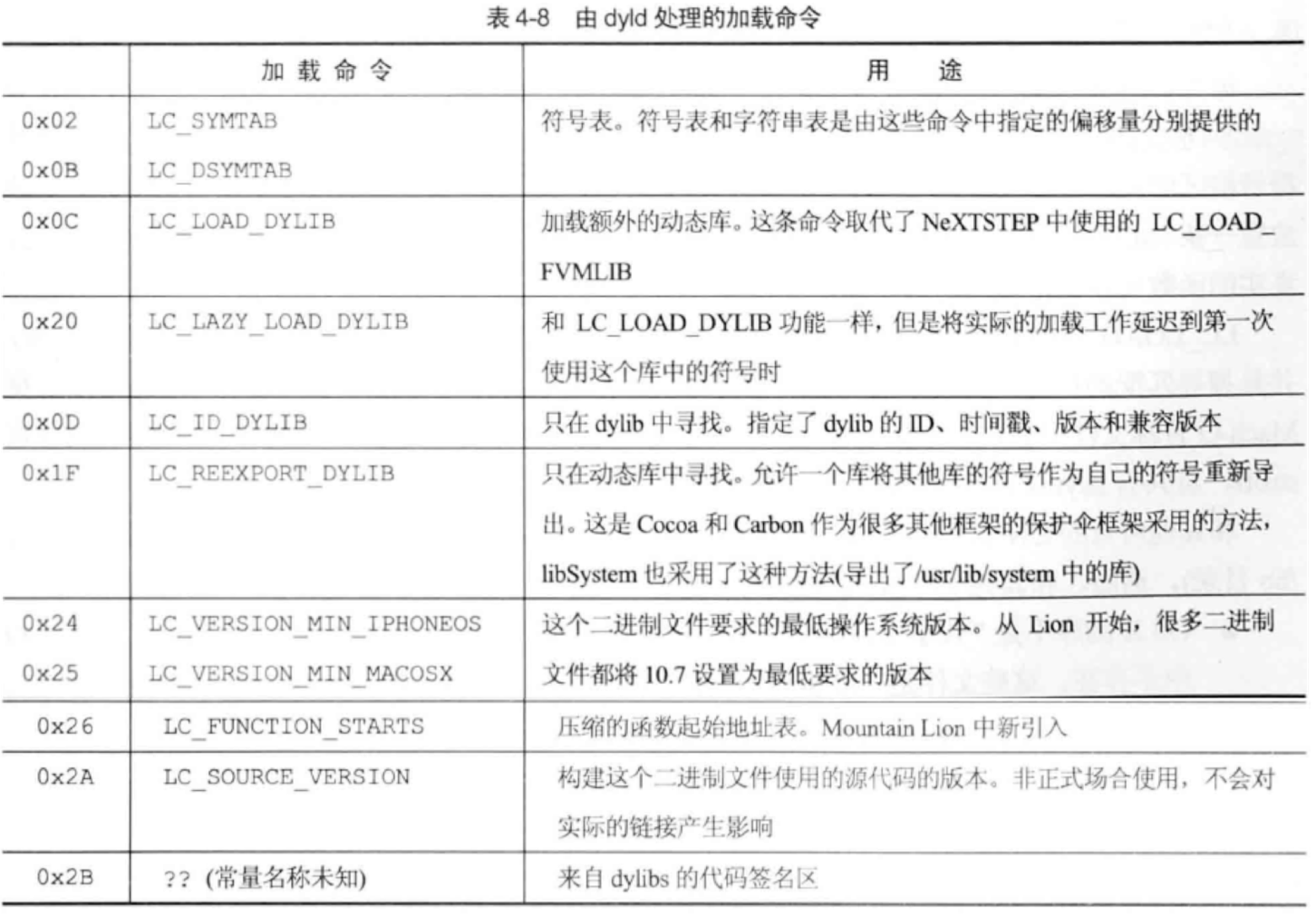
在Mach-O文件加载解析时,多个Load Command会告诉操作系统应当如何加载文件中每个Segment的数据,对系统内核加载器和动态链接器起引导作用。(不同的数据对应不同的加载命令,可以看到segment_command_64、symtab_command、dylib_command等,下面我们会讲解Segment的加载命令,下一节讲静态链接时,会涉及符号表symtab的加载命令)。
下面,以几个内核加载器负责解析处理的load command,来简单看下:
3.3.1 LC_SEGMENT(进程虚拟内存设置)
LC_SEGMENT(或LC_SEGMENT_64) 命令是最主要的加载命令,这条命令指导内核如何设置新运行的进程的内存空间。这些“段”直接从Mach-O二进制文件加载到内存中。
每一条LC_SEGMENT[64] 命令都提供了段布局的所有必要细节信息。关于常见的LC_SEGMENT命令,可以见下面3.4.1 节的讲述,介绍了几个重要的段、其数据结构成员变量。
有了LC_SEGMENT命令,设置进程虚拟内存的过程就变成遵循LC_SEGMENT命令的简单操作。
- 对于每一个段,将文件中相应的内容加载到内存中:从偏移量为 fileoff 处加载 filesize 字节到虚拟内存地址 vmaddr 处的 vmsize 字节。
- 每一个段的页面都根据 initprot 进行初始化,initprot 指定了如何通过读/写/执行位初始化页面的保护级别。段的保护设置可以动态改变,但是不能超过 maxprot 中指定的值(在iOS中,+x和+w是互斥的)。
3.3.2 LC_LOAD_DYLIB与LC_ID_DYLIB
LC_LOAD_DYLIB:
- 可执行文件(MH_EXECUTE类型)的Mach-O都会存在LC_LOAD_DYLIB类型的Load Command,该Load Command指定了当前Mach-O需要依赖的动态库(可以是系统的动态库也可以是开发者创建的动态库)。
- LC_LOAD_DYLIB类型的Load Command在内存中对应struct dylib_command结构,dylib_command结构包含struct dylib结构,struct dylib结构中name字段标记了动态库的路径。那么这个路径是从哪里来的呢?
1 | /* |
LC_ID_DYLIB:
- 动态库的Mach-O是MH_DYLIB类型的,一个动态库中必须包含一个LC_ID_DYLIB类型的Load Command(一般位于__LINKEDIT之后),它在内存中也是一个struct dylib_command结构,会有name字段。
- 这里的dylib_command信息会在LINK时作为LC_LOAD_DYLIB类型的Load Command插入进可执行文件(MH_EXECUTE 类型的Mach-O)中。
打开APP时,dyld会先递归遍历所有类型为LC_LOAD_DYLIB的Load Command从而查找依赖库,查找的路径即是由对应的dylib_command结构的name指定,一般为@rpath/DYNAME.framework/DYNAME。如果在指定各种查找路径都找不到,就会出现”dyld: Library not loaded”错误。
3.3.3 LC_CODE_SIGNATURE(数字签名)
Mach-O二进制文件有一个重要特性就是可以进行数字签名。尽管在 OS X 中仍然没怎么使用数字签名,不过由于代码签名和新改进的沙盒机制绑定在一起,所以签名的使用率也越来越高。在 iOS 中,代码签名是强制要求的,这也是苹果尽可能对系统封锁的另一种尝试:在 iOS 中只有苹果自己的签名才会被认可。在 OS X 中,code sign(1) 工具可以用于操纵和显示代码签名。man手册页,以及 Apple’s code signing guide 和 Mac OS X Code Signing In Depth文档都从系统管理员的角度详细解释了代码签名机制。
LC_CODE_SIGNATURE 包含了 Mach-O 二进制文件的代码签名,如果这个签名和代码本身不匹配(或者如果在iOS上这条命令不存在),那么内核会立即给进程发送一个SIGKILL信号将进程杀掉,没有商量的余地,毫不留情。
在iOS 4之前,还可以通过两条sysctl(8)命令覆盖负责强制执行(利用内核的MAC,即Mandatory AccessControl)的内核变量,从而实现禁用代码签名检查:
1 | sysctl -w security.mac.proc_enforce = 0 //禁用进程的MAC |
而在之后版本的iOS中,苹果意识到只要能够获得root权限,越狱者就可以覆盖内核变量。因此这些变量变成了只读变量。untethered越狱(即完美越狱)因为利用了一个内核漏洞所以可以修改这些变量。由于这些变量的默认值都是启用签名检查,所以不完美越狱会导致非苹果签名的应用程序崩溃——除非i设备以完美越狱的方式引导。
此外,通过 Saurik 的 ldid 这类工具可以在 Mach-O 中嵌入伪代码签名。这个工具可以替代OS X的code sign(1),允许生成自我签署认证的伪签名。这在iOS中尤为重要,因为签名和沙盒模型的应用程序“entitlement”绑定在一起, 而后者在iOS中是强制要求的。entitlement 是声明式的许可(以plist的形式保存),必须内嵌在Mach-O中并且通过签名盖章,从而允许执行安全敏感的操作时具有运行时权限。
OS X 和 iOS 都有一个特殊的系统调用csops(#169)用于代码签名的操作
3.3.4 LC_MAIN(设置主线程入口地址)
从Mountain Lion开始,一条新的加载命令LC_MAIN替代了LC_UNIX_THREAD命令。
- 后者的作用是:开启一个unix线程,初始化栈和寄存器,通常情况下,除了指令指针(Intel的IP)或程序计数器(ARM的r15)之外,所有的寄存器值都为0。
- 前者作用是设置程序主线程的入口点地址和栈大小。
这条命令比LC_UNIXTHREAD命令更实用一些, 因为无论如何除了程序计数器之外所有的寄存器都设置为0了。由于没有LC_UNIXTHREAD命令, 所以不可以在之前版本的 OS X 上运行使用了LC_MAIN的二进制文件(在加载时会导致dyld(1)崩溃)。
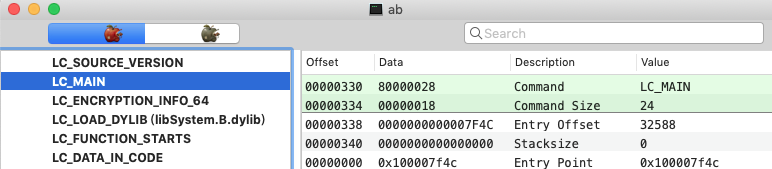
LC_Main对应的加载命令如下,记录了可执行文件的入口函数int main(int argc, char * argv[])的信息:
1 | struct entry_point_command { |
从定义上可以看到入口函数的地址计算:Entry Point = vm_addr(__TEXT) + entryOff + Slide
从dyld的源码里能看到对Entry Point的获取和调用:
1 | dyld |
这里简单看一下这几种load command所表示的信息。关于进程地址空间分布、线程入口在第四节 —— 装载会从进程启动到运行详细梳理一下流程。
3.4 Data
数据区(Data):Data 中每一个段(Segment)的数据都保存在此,段的概念和 ELF 文件中段的概念类似,都拥有一个或多个 Section ,用来存放数据和代码。
Raw segment data存放了所有的原始数据,而Load commands相当于Raw segment data的索引目录
3.4.1 Segment(段)
其中,LC_SEGMENT_64定义了一个64位的段,当文件加载后映射到地址空间(包括段里面节的定义)。64位段的定义如下:
1 | struct segment_command_64 { /* for 64-bit architectures */ |
系统将 fileoff 偏移处 filesize 大小的内容加载到虚拟内存的 vmaddr 处,大小为vmsize,段页面的权限由initprot进行初始化。它的权限可以动态改变,但是不能超过maxprot的值,例如 _TEXT 初始化和最大权限都是可读/可执行/不可写。
常见的LC_SEGMENT Segment (cmd为LC_SEGMET),其segname[16]有以下几种值:
- __PAGEZERO:空指针陷阱段,映射到虚拟内存空间的第1页,用于捕捉对 NULL 指针的引用。
LC_SEGMENT_64(__PAGEZERO)中:File Offset、File Size都是0、VM Address=0x0、VM Size=0x100000000,可以看出__PageZero在macho文件中不存在,只存在于虚拟内存中。- 在 32 位的系统中,这是内存中单独的一个页面(4KB),而且这个页面所有的访问权限都被撤消了。
- 在 64 位系统上,这个段对应了一个完整的32位地址空间(即前4GB)。
- 这个段有助于捕捉空指针引用(因为空指针实际上就是 0),或捕捉将整数当做指针引用(因为32位平台下的 4095 以下的值,以及64位平台下4GB以下的值都在这个范围内)。
- 由于这个范围内所有访问权限(读、写和执行)都被撤消了,所以在这个范围内的任何解引用操作都会引发来自 MMU 的硬件页错误, 进而产生一个内核可以捕捉的陷阱。内核将这个陷阱转换为C++异常或表示总线错误的POSIX信号(SIGBUS) 。
- PAGEZERO不是设计给进程使用的,但是多少成为了恶意代码的温床。想要通过“额外”代码感染Mach-O的攻击者往往发现可以很方便地通过PAGEZERO实现这个目的。PAGEZERO通常不属于目标文件的一部分(其对应的加载指令LC_SEGMENT将filesize指定为0),但是对此并没有严格的要求。
- __TEXT:代码段/只读数据段。
LC_SEGMENT_64(__TEXT )中:File Offser = 0,可以看出,mach header、load commands都是属于代码段的地址范围,都是只读的,放一起也可以。紧接着就是数据段。- vm size = file size,数据是直接拷贝过去。
- 和其他所有操作系统一样,文本段被设置为r-x,即只读且可执行。这不仅可以防止二进制代码在内存中被修改,还可以通过共享这个只读段优化内存的使用。通过这种方式,同一个程序的多个实例可以仅使用一份TEXT副本。
- 文本段通常包含多个区,实际的代码在_text区中。
- 文本段还可以包含其他只读数据,例如常量和硬编码的字符串。
- __DATA:可读取和写入数据的段。
- vm size略大于file size。
- __LINKEDIT:动态链接器dyld需要使用的信息,包括符号表、重定位表、绑定信息、懒加载信息等。
- __OBJC:包含会被Objective Runtime使用到的一些数据。(从Macho文档上看,他包含了一些编译器私有的节。没有任何公开的资料描述)
- __IMPORT:用于 i386 的二进制文件的导入表。
- __MALLOC_TINY:用于小于一个页面大小的内存分配。
- __MALLOC_SMALL:用于几个页面大小的内存分配。
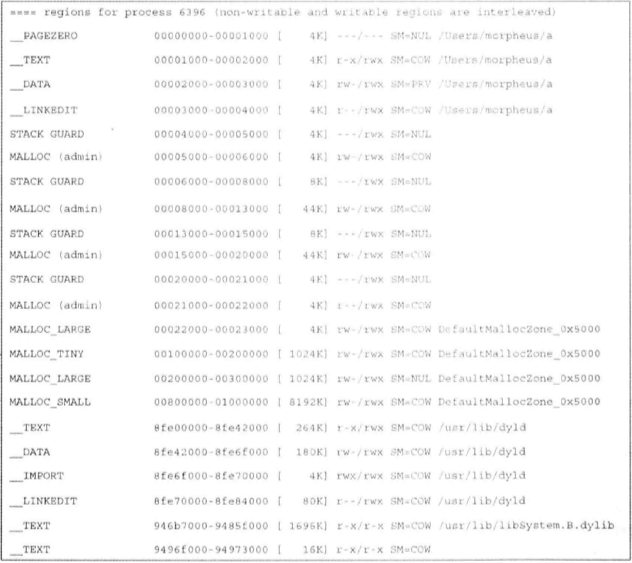
下面是使用vmmap(1)输出的一个实例程序a在32位硬件设备上运行的进程地址空间,显示了区域的名称、地址范围、权限(当前权限和最高权限)以及映射的名称(通常对应的是Mach-O目标文件,如果有的话)。
32位进程的虚拟地址空间布局:
3.4.2 Section(节)
从示例图中可以看到,部分的 Segment (__TEXT 和 __DATA) 可以进一步分解为 Section。
之所以按照 Segment(段) -> Section(节) 的结构组织方式,是因为在同一个 Segment 下的 Section,在内存中的权限相同(编译时,编译器把相同权限的section放在一起,成为segment),可以不完全按照 Page 的大小进行内存对齐,节省内存的空间。而 Segment 对外整体暴露,在装载程序时,完整映射成一个vma(Virtual Memory Address),更好的做到内存对齐,减少内存碎片(可以参考《OS X & iOS Kernel Programming》第一章内容)。
Section 具体的数据结构如下:
1 | struct section_64 { |
结合示例图,下面列举一些常见(并非全部)的 Section:(是按照在MachO文件的顺序排序的(也就是加载到虚拟地址空间中的排序),Swift相关的Section没有列出)
1 | // __TEXT Segment(段)下面的节: |
OC的无用代码检测和优化方案有很多种,优化方案遍布编译、链接、Product、运行等各个阶段。在OC的检测方案中,很大程度上是依赖classlist和classrefs做差集来实现的。其他技术手段不过是作为补充技术手段。
3.5 __stubs 与 __stub_helper
用来实现 LazyBind 的两个section:
__TEXT.__stubs、__TEXT.__stub_helper
在 wikipedia 有一个关于 Method stub 的词条,大意就是:Stub 是指用来替换一部分功能的程序段。桩程序可以用来模拟已有程序的行为(比如一个远端机器的过程)或是对将要开发的代码的一种临时替代。
总结来说:
__stub就是一段代码,功能为:跳转到__DATA.__la_symbol_ptr(__DATASegment 中的__la_symbol_ptrSection) 对应表项的数据,所指向的地址。__la_symbol_ptr里面的所有表项的数据在初始时都会被 binding 成__stub_helper。- 当懒加载符号第一次使用到的时候,按照上面的结构,会跳转到
__stub_helper这个section的代码,然后代码中会调用dyld_stub_binder来执行真正的bind。 bind结束后,就将__la_symbol_ptr中该懒加载符号 原本对应的指向__stub_helper的地址 修改为 符号的真实地址。 - 之后的调用中,虽然依旧会跳到
__stub区域,但是__la_symbol_ptr表由于在之前的调用中获取到了符号的真实地址而已经修正完成,所以无需在进入dyld_stub_binder阶段,可以直接使用符号。
这样就完成了LazyBind的过程。Stub 机制 其实和 wikipedia 上的说法一致,设置一个桩函数(模拟、占位函数)并采用 lazy 思想做成延迟 binding 的流程。
在《深入解析 Mac OS X & iOS操作系统》中有详细的验证,也可以参考深入剖析Macho (1) 自己动手验证一下。
四、通用二进制格式(Universal Binary)
通常也被称为胖二进制格式(Fat Binary),Apple 提出这个概念是为了解决一些历史原因,macOS(更确切的应该说是 OS X)最早是构建于 PPC 架构智商,后来才移植到 Intel 架构(从 Mac OS X Tiger 10.4.7 开始),通用二进制格式的二进制文件可以在 PPC 和 x86 两种处理器上执行。
说到底,通用二进制格式只不过是对多架构的二进制文件的打包集合文件,而 macOS 中的多架构二进制文件也就是适配不同架构的 Mach-O 文件。即一个通用二进制格式包含了很多个 Mach-O 格式文件。它有以下特点:
- 因为需要存储多种架构的代码,所以通用二进制文件要比单架构二进制文件要大
- 因为两种种架构之间可以共用一些资源,所以两种架构的通用二进制文件大小不会达到单一架构版本的两倍。
- 运行过程中只会调用其中的部分代码,所以运行起来不会占用额外的内存
Fat Header 的数据结构在 <mach-o/fat.h> 头文件中有定义,可以参看 /usr/include/mach-o/fat.h 找到定义头:
1 |
|
对于 cputype 和 cpusubtype 两个字段这里不讲述,可以参看 /usr/include/mach/machine.h 头中对其的定义,另外 Apple 官方文档中也有简单的描述。
在 fat_header 中,magic 也就是我们之前在表中罗列的 magic 标识符,也可以类比成 UNIX 中 ELF 文件的 magic 标识。加载器会通过这个符号来判断这是什么文件,通用二进制的 magic 为 0xcafebabe。nfat_arch 字段指明当前的通用二进制文件中包含了多少个不同架构的 Mach-O 文件。fat_header 后会跟着多个 fat_arch,并与多个 Mach-O 文件及其描述信息(文件大小、CPU 架构、CPU 型号、内存对齐方式)相关联。
这里可以通过 file 命令来查看简要的架构信息,这里以 iOS 平台 WeChat 4.5.1 版本为例:
1 | ~ file Desktop/WeChat.app/WeChat |
进一步,也可以使用 otool 工具来打印其 fat_header 详细信息:
1 | ~ otool -f -V Desktop/WeChat.app/WeChat |
之后我们用 Synalyze It! 来查看 WeChat 的 Mach64 Header 的效果:
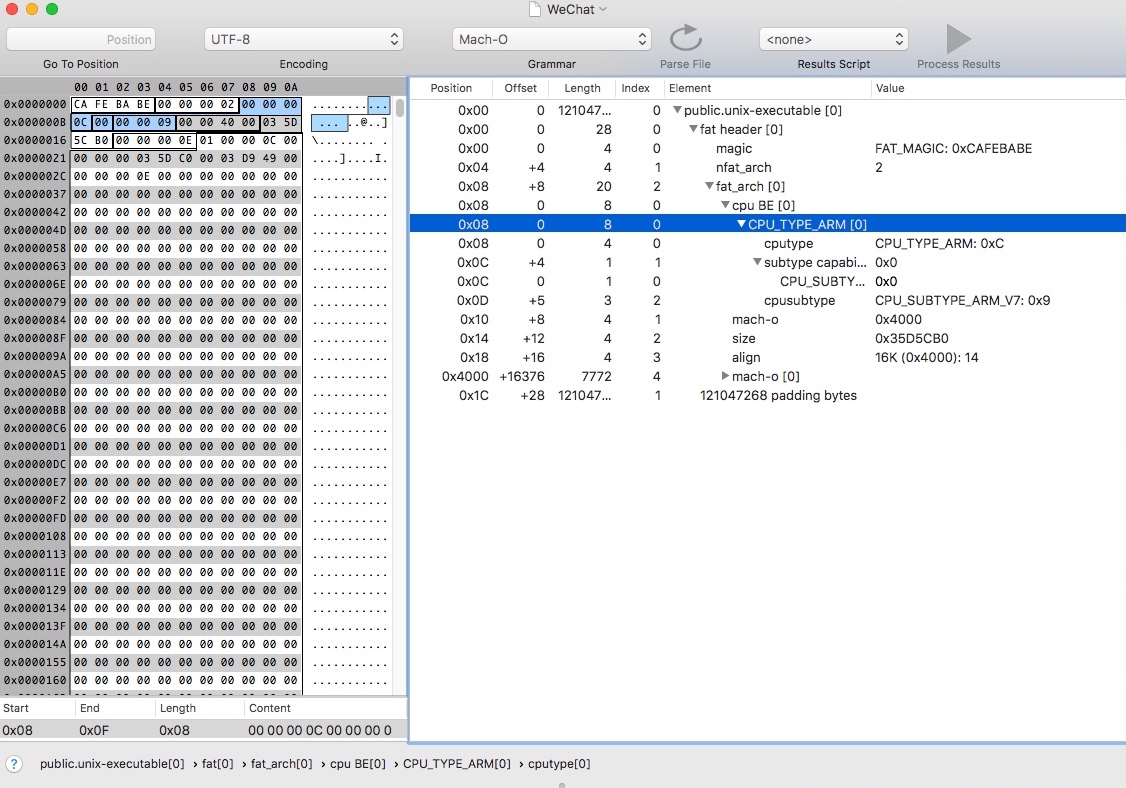
- 从第一个段中得到
magic = 0xcafebabe,说明是FAT_MAGIC。 - 第二段中所存储的字段为
nfat_arch = 0x00000002,说明该 App 中包含了两种 CPU 架构。 - 后续的则是
fat_arch结构体中的内容,cputype(0x0000000c)、cpusubtype(0x00000009)、offset(0x00004000)、size(0x03505C00)等等。如果只含有一种 CPU 架构,是没有 fat 头定义的,这部分则可跳过,从而直接过去arch数据。
注意,在mach-o中,数据结构中的地址表示:如果是value、address等,那一般是绝对地址;如果是偏移量offset等,一般都是相对于目标文件/可执行文件(注意,尤其是后者,起始地址不会是0,寻址时要加上起始地址)。