
一、卡顿的难点
时不时会收到这样的卡顿反馈:“用户A 刚才碰到从后台切换前台卡了一下,最近偶尔会遇到几次”、“用户B 反馈点对话框卡了五六秒”、“现网有用户反馈切换 tab 很卡”。
这些反馈有几个特点,导致跟进困难:
- 不易重现。可能是特定用户的手机上才有问题,由于种种原因这个手机不能拿来调试;也有可能是特定的时机才会出问题,过后就不能重现了(例如线程抢锁)。
- 操作路径长,日志无法准确打点
对于这些界面卡顿反馈,通常我们拿用户日志作用不大,增加日志点也用处不大。只能不断重试希望能够重现出来,或者埋头代码逻辑中试图能找的蛛丝马迹。
二、原理
在开始之前,我们先思考一下,界面卡顿是由哪些原因导致的?
- 死锁:主线程拿到锁 A,需要获得锁 B,而同时某个子线程拿了锁 B,需要锁 A,这样相互等待就死锁了。
- 抢锁:主线程需要访问 DB,而此时某个子线程往 DB 插入大量数据。通常抢锁的体验是偶尔卡一阵子,过会就恢复了。
- 主线程大量 IO:主线程为了方便直接写入大量数据,会导致界面卡顿。
- 主线程大量计算:算法不合理,导致主线程某个函数占用大量 CPU。
- 大量的 UI 绘制:复杂的 UI、图文混排等,带来大量的 UI 绘制。
针对这些原因,我们可以怎么定位问题呢?
- 死锁一般会伴随 crash,可以通过 crash report 来分析。
- 抢锁不好办,将锁等待时间打出来用处不大,我们还需要知道是谁占了锁。
- 大量 IO 可以在函数开始结束打点,将占用时间打到日志中。
- 大量计算同理可以将耗时打到日志中。
- 大量 UI 绘制一般是必现,还好办;如果是偶现的话,想加日志点都没地方,因为是慢在系统函数里面。
如果可以将当时的线程堆栈捕捉下来,那么上述难题都迎刃而解。主线程在什么函数哪一行卡住、在等什么锁而这个锁又是被哪个子线程的哪个函数占用、是在进行I/O操作、或者是进行复杂计算,有了堆栈,我们都可以知道。自然也能知道是慢在UI绘制,还是慢在我们的代码。
所以,思路就是起一个子线程,监控主线程的活动情况,如果发现有卡顿,就将堆栈 dump 下来。
流程图描述如下:
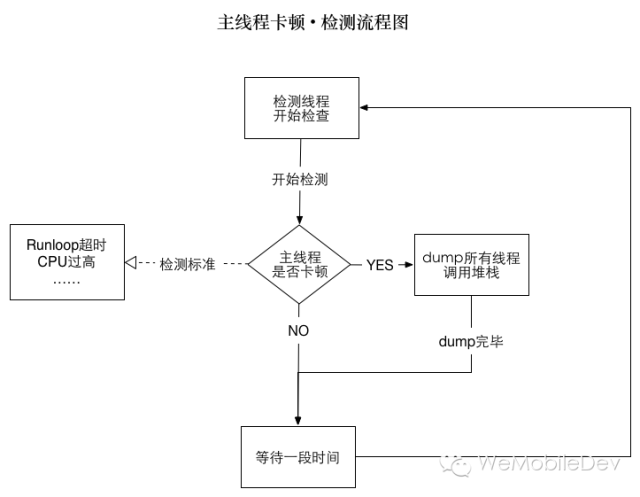
三、细节
原理一旦讲出来,好像也不复杂。魔鬼都是隐藏在细节中,效果好不好,完全由实现细节决定。具体到卡顿检测,有几个问题需要仔细处理:
- 怎么知道主线程发生了卡顿?
- 子线程以什么样的策略和频率来检测主线程?这个是要发布到现网的,如果处理不好,带来明显的性能损耗(尤其是电量),就不能接受了。
- 堆栈上报了上来怎么分类?直接用 crash report 的分类不适合。
- 卡顿 dump 下来的堆栈会有多频繁?数据量会有多大?
- 全量上报还是抽样上报?怎么在问题跟进与节省流量之间平衡?
3.1 卡顿判断标准
怎么判断主线程是不是发生了卡顿?一般来说,用户感受得到的卡顿大概有三个特征:
- FPS 降低
- CPU 占用率很高
- 主线程 Runloop 执行了很久
看起来 FPS 能够兼容后面两个特征,但是在实际操作过程中发现 FPS 并不适用,不好衡量:
- 人眼结构上看,当一组动作在 1 秒内有 12 次变化(即 12FPS),我们会认为这组动作是连贯的;
- 平时看到的大部分电影或视频 FPS 其实不高,一般只有 25FPS ~ 30FPS,而实际上我们也没有觉得卡顿;
- 游戏玩家通常追求更流畅的游戏画面体验一般要达到 60FPS 以上
- FPS 低并不意味着卡顿发生,而卡顿发生 FPS 一定不高。FPS 可以衡量一个界面的流畅性,但往往不能很直观的衡量卡顿的发生。
而对于抢锁或大量 IO 的情况,光有 CPU 是不行的。所以我们实际上用到的是下面两个准则:
- 单核 CPU 的占用超过了 80%
- 主线程 Runloop 执行了超过2秒
3.2 卡顿检测实现
在 iOS/macOS 平台应用中,主线程有一个 Runloop。Runloop 是一个 Event Loop 模型,让线程可以处于接收消息、处理事件、进入等待而不马上退出。在进入事件的前后,Runloop 会向注册的 Observer 通知相应的事件。
Runloop 的详细介绍可以参考:深入理解RunLoop,一个简易的 Runloop 流程如下所示:
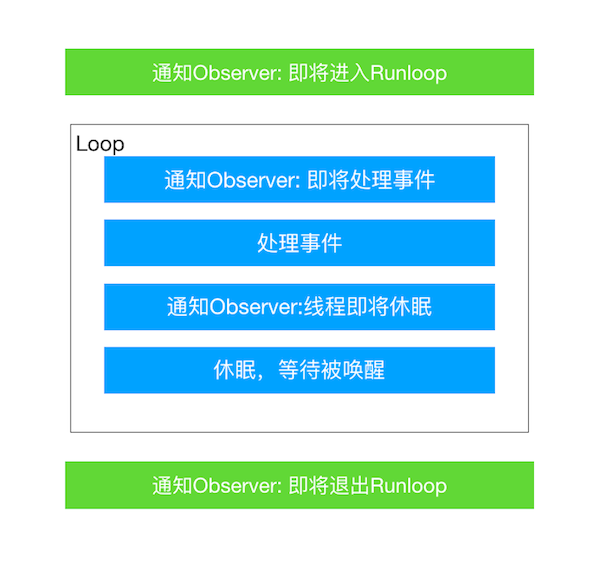
Matrix 卡顿监控在 Runloop 的起始最开始和结束最末尾位置添加 Observer,从而获得主线程的开始和结束状态。卡顿监控起一个子线程定时检查主线程的状态,当主线程的状态运行超过一定阈值则认为主线程卡顿,从而标记为一个卡顿。
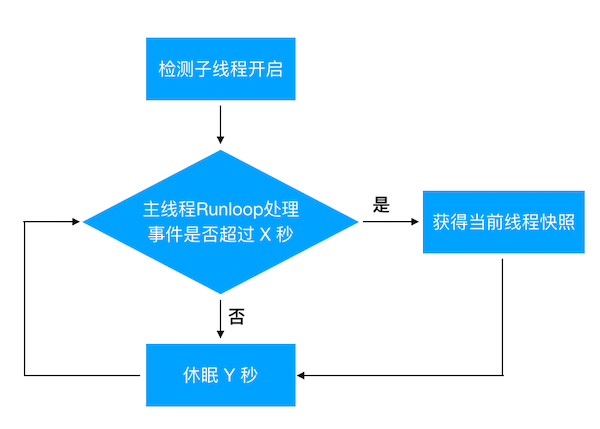
目前微信使用的卡顿监控,主程序 Runloop 超时的阈值是 2 秒,子线程的检查周期是 1 秒。每隔 1 秒,子线程检查主线程的运行状态;如果检查到主线程 Runloop 运行超过 2 秒则认为是卡顿,并获得当前的线程快照。
同时,我们也认为 CPU 过高也可能导致应用出现卡顿,所以在子线程检查主线程状态的同时,如果检测到 CPU 占用过高,会捕获当前的线程快照保存到文件中。目前微信应用中认为,单核 CPU 的占用超过了 80%,此时的 CPU 占用就过高了。
代码示例:SMLagMonitor.m
1 | //创建子线程监控 |
3.3 检测策略—退火算法
为了降低检测带来的性能损耗,我们仔细设计了检测线程的策略:
- 内存 dump:每次子线程检查到主线程卡顿,会先获得主线程的堆栈并保存到内存中(不会直接去获得线程快照保存到文件中);
- 文件 dump:将获得的主线程堆栈与上次卡顿获得的主线程堆栈进行比对:
- 如果堆栈不同,则获得当前的线程快照并写入文件中;
- 如果相同则会跳过,并按照斐波那契数列将检查时间递增(1,1,2,3,5,8…)直到没有遇到卡顿或者主线程卡顿堆栈不一样。
这样,可以避免同一个卡顿写入多个文件的情况;避免检测线程遇到主线程卡死的情况下,不断写线程快照文件。
3.4 卡顿时堆栈获取
3.4.1 直接调用系统函数
获取堆栈信息的一种方法是直接调用系统函数。这种方法的优点在于,性能消耗小。但是,它只能够获取简单的信息,也没有办法配合 dSYM 来获取具体是哪行代码出了问题,而且能够获取的信息类型也有限,且只能获取当前线程的调用栈。这种方法,因为性能比较好,所以适用于观察大盘统计卡顿情况,而不是想要找到卡顿原因的场景。
直接调用系统函数方法的主要思路是:用 signal 进行错误信息的获取。具体代码如下
1 | static int s_fatal_signals[] = { |
3.4.2 PLCrashReporter三方库
PLCrashReporter 是微软开源的第三方框架,用来做 crash 收集,可以直接用 PLCrashReporter 来获取堆栈信息。这种方法的特点是,能够定位到问题代码的具体位置,而且性能消耗也不大。所以,也是我推荐的获取堆栈信息的方法。
具体如何使用 PLCrashReporter 来获取堆栈信息,代码如下所示:
1 | // 获取数据 |
堆栈采集相关源码:
1 | // ▼ plcrash_write_report是核心,暂停线程,抓线程堆栈信息,写文件和恢复线程都在这个函数里。 |
3.4.3 KSCrash
KSCrash 是 iOS 上一个知名的 crash 收集框架。包括腾讯开源的 APM 框架 Matrix,其中 crash 收集部分也是直接使用的 KSCrash。
KSCrash 可以处理以下类型的崩溃:
- Mach kernel exceptions Mac内核异常
- Fatal signals
- C++ exceptions
- Objective-C exceptions
- Main thread deadlock (experimental) 主线程死锁
- Custom crashes (e.g. from scripting languages) 自定义崩溃。
堆栈采集源码:(看获取任意线程调用栈的那些事 _bestswifter BSBackTracelogger的参考资料中有KSCrash,貌似对KSCrash有参考,源码思路上有些相似)
1 | static bool advanceCursor(KSStackCursor *cursor) { |
3.4.4 WCCrashBlockMonitorPlugin
Matrix for iOS/macOS 是微信开源的一个工具,可以使用在 iOS、macOS 平台上。在日常开发中,微信iOS团队通过卡顿监控上报的堆栈,找到微信的代码不合理之处或者是一些性能瓶颈;通过卡顿监控的辅助,尽可能地提升微信的流畅性,给用户带来更加极致美好的体验。
工具监控范围包括:崩溃、卡顿和爆内存,包含以下两款插件:
- WCCrashBlockMonitorPlugin:基于 KSCrash 框架开发,具有业界领先的卡顿堆栈捕获能力,同时兼备崩溃捕获能力。
- WCMemoryStatPlugin:一款性能优化到极致的爆内存监控工具,能够全面捕获应用爆内存时的内存分配以及调用堆栈情况。
3.4.5 BSBackTracelogger
见下文
3.5 耗时堆栈提取
子线程检测到主线程 Runloop 时,会获得当前的线程快照当做卡顿文件。但是这个当前的主线程堆栈不一定是最耗时的堆栈,不一定是导致主线程超时的主要原因。
例如,主线程在绘制一个微信logo,过程如下:
子线程在检测到超出阈值时获得的线程快照,主线程的当前任务是“画小气泡”。但其实“画大气泡”才是耗时操作,导致主线程超时的主要原因。Matrix 卡顿监控通过主线程耗时堆栈提取来解决这个问题。
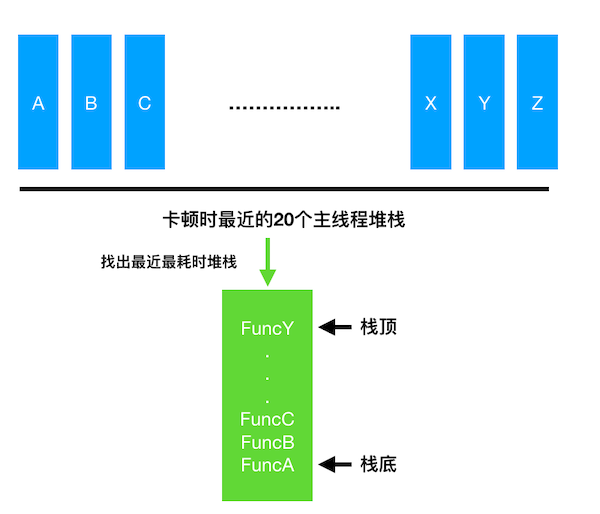
卡顿监控定时获取主线程堆栈,并将堆栈保存到内存的一个循环队列中。如下图,每间隔时间 t 获得一个堆栈,然后将堆栈保存到一个最大个数为 3 的循环队列中。有一个游标不断的指向最近的堆栈。
微信的策略是每隔 50 毫秒获取一次主线程堆栈,保存最近 20 个主线程堆栈。这个会增加 3% 的 CPU 占用,内存占用可以忽略不计。
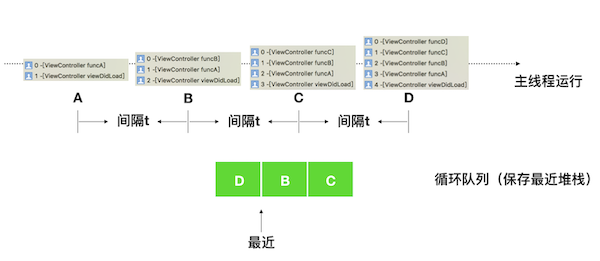
当主线程检测到卡顿时,通过对保存到循坏队列中的堆栈进行回溯,获取最近最耗时堆栈。
如下图,检测到卡顿时,内存的循环队列中记录了最近的20个主线程堆栈,需要从中找出最近最耗时的堆栈。Matrix 卡顿监控用如下特征找出最近最耗时堆栈:
- 以栈顶函数为特征,认为栈顶函数相同的即整个堆栈是相同的;
- 取堆栈的间隔是相同的,堆栈的重复次数近似作为堆栈的调用耗时,重复越多,耗时越多;
- 重复次数相同的堆栈可能很有多个,取最近的一个最耗时堆栈。
获得的最近最耗时堆栈会附带到卡顿文件中。
3.6 卡死卡顿
Matrix 中内置了应用被杀原因的检测机制。这个机制从 Facebook 的博文 中获得灵感,在其基础上增加了系统强杀的判定。Matrix 检测应用被杀原因的具体机制如下图所示:
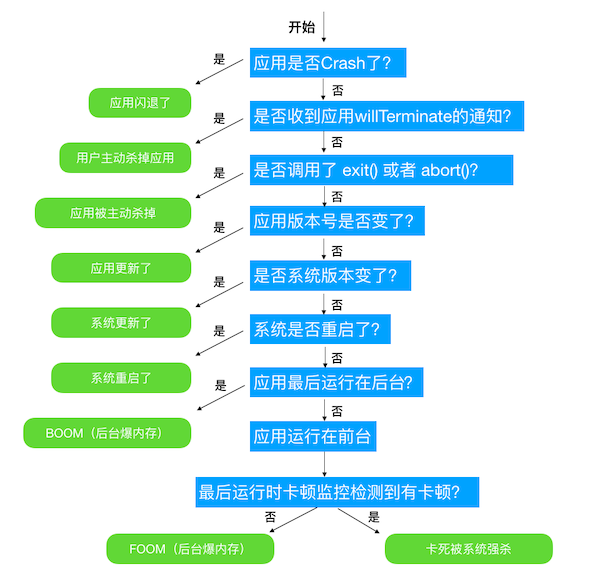
Matrix 检测到应用卡死被强杀,会把应用上次存活时的最后一份卡顿日志标记为卡死卡顿。
3.7 性能损耗
Matrix 卡顿监控不打开耗时堆栈提取,性能损耗可以忽略不计。
打开耗时堆栈提取后,性能损耗和定时获取主线程堆栈的间隔有关。实测,每隔 50 毫秒不断获取主线程堆栈,会增加 3% 的 CPU 占用。
3.8 分类方法
直接用 crash report 的分类方法是不行的,这个很好理解:最终卡在 lock 函数的卡顿,外面可能是很多不同的业务,例如可能是读取消息,可能是读取联系人,等等。卡顿监控需要仔细定义自己的分类规则。可以是从调用堆栈的最外层开始归类,或者是取中间一部分归类,或者是取最里面一部分归类。各有优缺点:
- 最外层归类:能够将同一入口的卡顿归类起来。缺点是层数不好定,可能外面十来层都是系统调用,也有可能第一层就是微信的函数了。
- 中间层归类:能够根据事先划分好的“特征值”来归类。缺点是“特征值”不好定,如果要做到自动学习生成的话,对后台分析系统要求太高了。
- 最内层归类:能够将同一原因的卡顿归类起来。缺点是同一分类可能包含不同的业务。
综合考虑并一一尝试之后,我们采用了最内层归类的优化版,亦即进行二级归类。
- 第一级:按照 最内倒数2层 归类,这样能够将 同一原因 的卡顿集中起来;
- 第二级分类是从第一级点击进来,然后按照 最内层倒数4层 进行归类,这样能够将同一原因,根据 不同业务(不同入口) 分散归类起来。
3.9 可运营
在正式发布之前,我们进行了灰度,以评估卡顿对用户的影响。收集到的结果是用户平均每天会产生30个 dump 文件,压缩上传大约要 300k 流量。预计正式发布的话会对后台有比较大的压力,对用户也有一定流量损耗。所以必须进行抽样上报。
- 抽样上报:每天抽取不同的用户进行上报,抽样概率是5%。
- 文件上传:被抽中的用户1天仅上传前20个堆栈文件,并且每次上报会进行多文件压缩上传。
- 白名单:对于需要跟进问题的用户,可以在后台配置白名单,强制上报。
另外,为了减少对用户存储空间的影响,卡顿文件仅保存最近7天的记录,过期删除。
四、BSBackTracelogger堆栈获取原理
NSThread 有一个类方法 callstackSymbols 可以获取调用栈,但是它输出的是当前线程的调用栈。在利用 Runloop 检测卡顿时,子线程检测到了主线程发生卡顿,需要通过主线程的调用栈来分析具体是哪个方法导致了阻塞,这时系统提供的方法就无能为力了。
4.1 失败的方法
最初的想法很简单,既然 callstackSymbols 只能获取当前线程的调用栈,那在目标线程调用就可以了。比如 dispatch_async 到主队列,或者 performSelector 系列,更不用说还可以用 Block 或者代理等方法。
我们以 UIViewController 的viewDidLoad 方法为例,推测它底层都发生了什么。
首先主线程也是线程,就得按照线程基本法来办事。线程基本法说的是首先要把线程运行起来,然后(如果有必要,比如主线程)启动 runloop 进行保活。我们知道 runloop 的本质就是一个死循环,在循环中调用多个函数,分别判断 source0、source1、timer、dispatch_queue 等事件源有没有要处理的内容。
和 UI 相关的事件都是 source0,因此会执行 __CFRunLoopDoSources0,最终一步步走到 viewDidLoad。当事件处理完后 runloop 进入休眠状态。
假设我们使用 dispatch_async,它会唤醒 runloop 并处理事件,但此时 __CFRunLoopDoSources0 已经执行完毕,不可能获取到 viewDidLoad 的调用栈。
performSelector 系列方法的底层也依赖于 runloop,因此它只是像当前的 runloop 提交了一个任务,但是依然要等待现有任务完成以后才能执行,所以拿不到实时的调用栈。
总而言之,一切涉及到 runloop,或者需要等待 viewDidLoad 执行完的方案都不可能成功。
4.2 ARM64 函数调用栈
从汇编入手,看一下实际的Arm64的栈帧格式:案例来自BSBackTracelogger学习笔记,图解的非常清晰,感谢。
1 | void b() { |
汇编代码如下:
1 | armtest`a: |
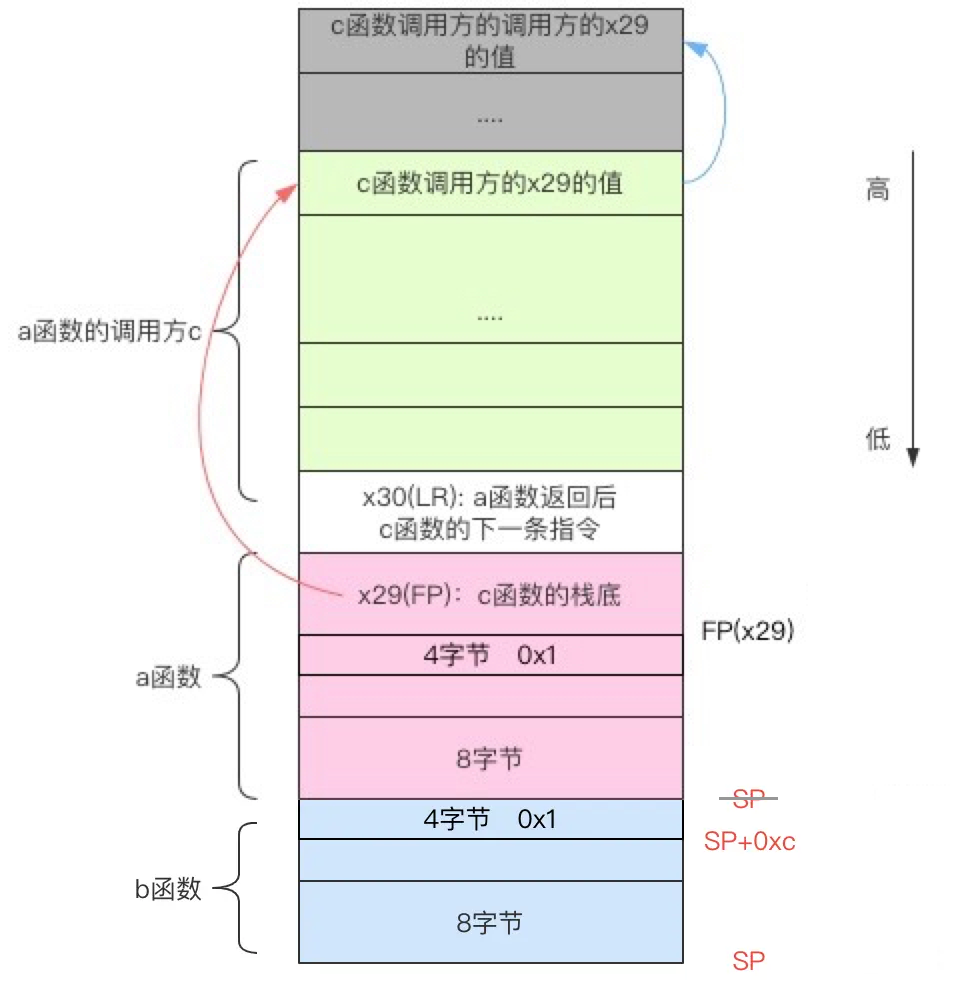
c函数调用a函数是一个入栈出栈的过程,调用开始的时候入栈,同时需要保存c函数的FP(x29)和LR(x30)在a函数的FP和FP+8的位置,即当前函数a的FP位置保存的就是调用方的FP位置,a函数调用结束时返回到LR的位置继续执行下一条指令,而这条指令属于c函数,因此我们可以通过FP来建立整个调用链的关系,通过LR来确认调用方函数的符号。
尽管如此,有两种情况是获取不到调用堆栈的,一种是尾调用优化,一种是内联函数。
4.3 BSBackTracelogger步骤
上文中我们谈到了函数调用栈,那么通过调用栈,只要我们可以拿到主线程的相关寄存器,就可以通过调用关系一步一步拿到主线程的调用堆栈,这也正是BSBackTracelogger的原理所在。
以下是获取调用栈原理(根据 arm64 情况)。
第一步 获取所有mach线程标识
Unix 系统提供的 thread_get_state 和 task_threads 等方法,操作的都是内核线程,每个内核线程由 thread_t 类型的 id 来唯一标识,pthread 的唯一标识是 pthread_t 类型。
mach 线程 — pthread — NSThread
获取主线程标识:
-
static mach_port_t main_thread_id = mach_thread_self();可以获取主线程的标识。 - 上述方案要求我们在主线程中执行代码,一个很好的方案就是在 load 方法里。
- 在使用的地方,判断目标
[NSThread isMainThread]为真,则直接获取上面全局变量值。
获取子线程标识:
- 通过
task_threads函数获取当前进程中线程列表thread_act_array_t,里面保存的是 mach 线程的标识,可以通过这个线程标识获取对应线程的 name、idle 状态等。
将子线程 NSThread 与 mach 线程对应起来(详见4.4.3小节):
- 如果不是主线程,那么可以给 NSThread 设置 name(比如设置为时间戳)。
- NSThread 的 name 和 pthread name 是一致的,所以可以遍历
thread_act_array_t,逐个通过pthread_from_mach_thread_np函数转为 pthread 获取 name 进行比对,匹配则标识找到了 NSThread 对应的 mach 线程标识。
关键函数、类型定义如下:
1 |
|
第二步 根据线程标识获取调用栈
前面介绍了调用栈的结构:**当前栈帧的 X29 指向上一个栈帧的 X29(FP)、X30(LR)**,LR寄存器中保存的就是当前子程序结束后需要执行的下一条指令,即LR 的上一条指令即为函数调用处。
所以根据线程标识获取栈帧结构体:
- 最外侧的调用栈取 PC;
- 其余的调用栈都取 LR,LR 的上一条指令就是调用处,通过回溯 FP 不断获取上层调用栈;
- …
- 通过FP来建立整个调用链的关系,通过每个函数栈帧对应的LR值来确认调用方函数的符号。
所以构建一个递归结构体,分别指向自己和 LR,对应前面说的 X29、X30 结构,递归找到所有地址。
根据线程标识可以通过 thread_get_state 获取到线程寄存器状态结构体:
1 | typedef mach_port_t thread_t; |
BSBackTracelogger的源代码中使用的就是 _STRUCT_MCONTEXT 并从中取 __ss 字段,_STRUCT_MCONTEXT 判断了 32 位和 64 位,实质上是想取 _STRUCT_ARM_THREAD_STATExx:
1 |
|
第三步 地址符号化
本地符号化可以使用 dladdr 函数,原型如下:
1 | /* |
BSBacktraceLogger 采用的方式是:
- 根据地址找到所属镜像(主二进制、系统库);
- 然后从所属镜像中找到符号表;
- 再找到与地址最接近的符号名称;
BSBackTracelogger 中并没有使用系统的 dladdr 函数,而是重写了一个。下面是个issue,以及作者的解答:
系统提供的dladdr方法是线程安全的,而代码中的fl_dladdr其实底层调用的也是系统提供的_dyld_get_image_header和_dyld_get_image_name等方法,而这些方法是线程不安全的,经过我本人的实验对比,fl_dladdr返回的symbolbuffer和dladdr返回的结果是一样的,不清楚作者是出于什么样的考虑自己重写了一个fl_dladdr方法。
回答:这段代码是从 PLC (PLCrashReporter) 里面抄出来的….
4.4 补充:NSThread、pthread、mach线程
4.4.1 pthread与mach内核线程
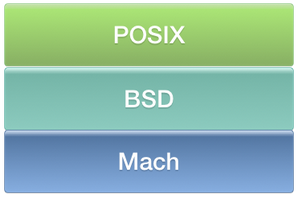
pthread 中的字母 p 是 POSIX 的简写,POSIX 表示 “可移植操作系统接口(Portable Operating System Interface)”。
每个操作系统都有自己的线程模型,不同操作系统提供的,操作线程的 API 也不一样,这就给跨平台的线程管理带来了问题,而 POSIX 的目的就是提供抽象的 pthread 以及相关 API,这些 API 在不同操作系统中有不同的实现,但是完成的功能一致。
iOS中的 POSIX API 就是通过 Mach 之上的 BSD 层实现的:
Unix 系统提供的 thread_get_state 和 task_threads 等方法,操作的都是内核线程,每个内核线程由 thread_t 类型的 id 来唯一标识,pthread 的唯一标识是 pthread_t 类型。
内核线程和 pthread 的转换(也即是 thread_t 和 pthread_t 互转)很容易,因为 pthread 诞生的目的就是为了抽象内核线程。
4.4.2 NSThread与pthread
NSThread 是苹果官方提供的,使用起来比 pthread 更加面向对象,简单易用,可以直接操作线程对象。
关于两者联系,可以查看 GNUStep-base 的源码,其中包含了 Foundation 库的源码,并不能确保 NSThread 完全采用这里的实现,但至少可以从 NSThread.m 类中挖掘出很多有用信息。
1 | - (void)start { |
NSThread 关于线程的实现,还是使用的pthread。但另一方面,NSThread 内部只有很少的地方用到了 pthread。从上面看到,NSThread 甚至都没有存储新建 pthread 的 pthread_t 标识。
另一处用到 pthread 的地方就是 NSThread 在退出时,调用了 pthread_exit()。除此以外就很少感受到 pthread 的存在感了。
1 | + (void)exit { |
4.4.3 NSThread 转 内核thread
由于系统没有提供相应的转换方法,而且 NSThread 没有保留线程的 pthread_t,所以常规手段无法满足需求。
一种思路是利用 performSelector 方法在指定线程执行代码并记录 thread_t,执行代码的时机不能太晚,如果在打印调用栈时才执行就会破坏调用栈。最好的方法是在线程创建时执行,上文提到了在利用 pthread_create 方法创建线程时,会注册一个回调函数 nsthreadLauncher 。
1 | /** |
很神奇的发现系统居然会发送一个通知,通知名不对外提供,但是可以通过监听所有通知名的方法得知它的名字: @"_NSThreadDidStartNotification",于是我们可以监听这个通知并调用 performSelector 方法。
一般 NSThread 使用 initWithTarget:Selector:object 方法创建。在 main 方法中 selector 会被执行,main 方法执行结束后线程就会退出。如果想做线程保活,需要在传入的 selector 中开启 runloop,详见这篇文章: 深入研究 Runloop 与线程保活。
可见,这种方案并不现实,因为之前已经解释过,performSelector 依赖于 runloop 开启,而 runloop 直到 main 方法才有可能开启。
回顾问题发现,我们需要的是一个联系 NSThread 对象和内核 thread 的纽带,也就是说要找到 NSThread 对象的某个唯一值,而且内核 thread 也具有这个唯一值。
观察一下 NSThread,它的唯一值只有对象地址,对象序列号(Sequence Number) 和线程名称:
1 | <NSThread: 0x144d095e0>{number = 1, name = main} |
地址分配在堆上,没有使用意义,序列号的计算没有看懂,因此只剩下 name。幸运的是 pthread 也提供了一个方法 pthread_getname_np 来获取线程的名字,两者是一致的,感兴趣的读者可以自行阅读 setName 方法的实现,它调用的就是 pthread 提供的接口。
这里的 np 表示 not POSIX,也就是说它并不能跨平台使用。
于是解决方案就很简单了,对于 NSThread 参数,把它的名字改为某个随机数(我选择了时间戳),然后遍历 pthread 并检查有没有匹配的名字。查找完成后把参数的名字恢复即可。
4.4.4 主线程 转 内核thread
本来以为问题已经圆满解决,不料还有一个坑,主线程设置 name 后无法用 pthread_getname_np 读取到。
好在我们还可以迂回解决问题: 事先获得主线程的 thread_t,然后进行比对。
上述方案要求我们在主线程中执行代码从而获得 thread_t,显然最好的方案是在 load 方法里:
1 | static mach_port_t main_thread_id; |