
iOS 数据库方案
目前移动端数据库方案按其实现可分为两类,
- 关系型数据库,代表有CoreData、FMDB等。
- CoreData:它是苹果内建框架,和Xcode深度结合,可以很方便进行ORM;但其上手学习成本较高,不容易掌握。稳定性也堪忧,很容易crash;多线程的支持也比较鸡肋。
- FMDB:它基于SQLite封装,对于有SQLite和ObjC基础的开发者来说,简单易懂,可以直接上手;而缺点也正是在此,FMDB只是将SQLite的C接口封装成了ObjC接口,没有做太多别的优化,即所谓的胶水代码(Glue Code)。使用过程需要用大量的代码拼接SQL、拼装Object,并不方便。
- key-value数据库,代表有Realm、LevelDB、RocksDB等。
- Realm:因其在各平台封装、优化的优势,比较受移动开发者的欢迎。对于iOS开发者,key-value的实现直接易懂,可以像使用NSDictionary一样使用Realm。并且ORM彻底,省去了拼装Object的过程。但其对代码侵入性很强,Realm要求类继承RLMObject的基类。这对于单继承的ObjC,意味着不能再继承其他自定义的子类。同时,key-value数据库对较为复杂的查询场景也比较无力。
可见,各个方案都有其独特的优势及劣势,没有最好的,只有最适合的。
一、SQLite概述及其优点、不足
SQLite是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库不一样,您不需要在系统中配置。
就像其他数据库,SQLite 引擎不是一个独立的进程,可以按应用程序需求进行静态或动态连接。SQLite 直接访问其存储文件。
1.1 为什么要用 SQLite?
- 不需要一个单独的服务器进程或操作的系统(无服务器的)。
- SQLite 不需要配置,这意味着不需要安装或管理。
- 一个完整的 SQLite 数据库是存储在一个单一的跨平台的磁盘文件。
- SQLite 是非常小的,是轻量级的,完全配置时小于 400KiB,省略可选功能配置时小于250KiB。
- SQLite 是自给自足的,这意味着不需要任何外部的依赖。
- SQLite 事务是完全兼容 ACID 的,允许从多个进程或线程安全访问。
- SQLite 支持 SQL92(SQL2)标准的大多数查询语言的功能。
- SQLite 使用 ANSI-C 编写的,并提供了简单和易于使用的 API。
- SQLite 可在 UNIX(Linux, Mac OS-X, Android, iOS)和 Windows(Win32, WinCE, WinRT)中运行。
1.2 SQLite 局限性
在 SQLite 中,SQL92 不支持的特性如下所示:
| 特性 | 描述 |
|---|---|
| 查询 — 外连接 | 只实现了 LEFT OUTER JOIN。不支持RIGHT OUTER JOIN、FULL OUTER JOIN |
| 修改 — ALTER TABLE | 支持修改表名称、添加字段命令,但不支持删除字段、修改字段的属性(名称、类型、宽度等) 。 |
| Trigger 支持 | 支持 FOR EACH ROW 触发器,但不支持 FOR EACH STATEMENT 触发器。 |
| VIEWs | 在 SQLite 中,视图是只读的。您不可以在视图上执行 DELETE、INSERT 或 UPDATE 语句。 |
| GRANT 和 REVOKE | 可以应用的唯一的访问权限是底层操作系统的正常文件访问权限。 |
二、SQLite中的”连接“与”句柄“
2.1 MySQL的”连接“
数据库连接(database connection)是数据库服务器与客户端之间的通信联系(数据库也是个服务器,也需要远程连接操作)。客户通过数据库连接发送命令、接收服务器返回的结果。
通过可执行文件,连接服务器
以下是从命令行中,使用MySQL二进制方式,连接MySQL数据库,进入到mysql命令提示符下来操作数据库。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 在本实例中,使用root用户登录到mysql服务器,当然你也可以使用其他mysql用户登录。
# 如果用户权限足够,任何用户都可以在mysql的命令提示窗口中进行SQL操作。
[root@host]# mysql -u root -p
Enter password:******
# 以上命令执行后,登录成功输出结果如下:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2854760 to server version: 5.0.9
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
# 在登录成功后会出现 mysql> 命令提示窗口,你可以在上面执行任何 SQL 语句。
# 退出 mysql> 命令提示窗口可以使用 exit 命令,如下所示:
mysql> exit
Bye通过代码连接,比如Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public class MySQLDemo {
// MySQL 8.0 以下版本 - JDBC 驱动名及数据库 URL
static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
static final String DB_URL = "jdbc:mysql://localhost:3306/RUNOOB";
// MySQL 8.0 以上版本 - JDBC 驱动名及数据库 URL
//static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver";
//static final String DB_URL = "jdbc:mysql://localhost:3306/RUNOOB?useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=UTC";
// 数据库的用户名与密码,需要根据自己的设置
static final String USER = "root";
static final String PASS = "123456";
public static void main(String[] args) {
// 注册 JDBC 驱动
Class.forName(JDBC_DRIVER);
// 打开链接:连接数据库....
Connection conn = DriverManager.getConnection(DB_URL,USER,PASS);
// 执行查询:实例化Statement对象...
Statement stmt = conn.createStatement();
String sql = "SELECT id, name, url FROM websites";
ResultSet rs = stmt.executeQuery(sql);
// 展开结果集数据库
while(rs.next()){
// 通过字段检索
int id = rs.getInt("id");
String name = rs.getString("name");
String url = rs.getString("url");
// 输出数据
}
// 完成后关闭
rs.close();
stmt.close();
conn.close();
}
}
IBM DB2, Microsoft SQL Server, Oracle, MySQL, PostgreSQL, 与Neo4j使用连接池技术来改善性能。
建造连接时,通常要提供一个驱动程序或provider与一个连接字符串。例如,Server=sql_box;Database=Common;User ID=uid;Pwd=password;
一旦连接建立,它可以被打开、关闭、设置性质。
2.2 操作系统中句柄与文件
2.2.1 操作系统中的”句柄“
在程序设计中,句柄(handle)是Windows操作系统用来标识被应用程序所创建或使用的对象的整数。其本质相当于带有引用计数的智能指针。当一个应用程序要引用其他系统(如数据库、操作系统)所管理的内存块或对象时,可以使用句柄。
句柄与普通指针的区别在于:
- 指针包含的是引用对象的内存地址,而句柄则是由系统所管理的引用标识,该标识可以被系统重新定位到一个内存地址上。这种间接访问对象的模式增强了系统对引用对象的控制。(参见封装)。
- 通俗的说就是我们调用句柄就是调用句柄所提供的服务,即句柄已经把它能做的操作都设定好了,我们只能在句柄所提供的操作范围内进行操作,但是普通指针的操作却多种多样,不受限制。
句柄与安全性:客户获得句柄时,句柄不仅是资源的标识符,也被授予了对资源的特定访问权限。
1 | // C 打开文件,返回文件指针(FILE是个结构体,记录了打开文件的一些信息) |
关于句柄,下面举一个实际的例子,在Linux中,值为0、1、2的fd分别代表标准输入、标准输出和标准错误输出。在程序中打开文件得到的fd从3开始增长。fd具体是什么呢?
在内核中,每一个进程都有一个私有的“打开文件表”,这个表是一个指针数组,每一个元素都指向一个内核的打开文件对象。而fd,就是这个表的下标。当用户打开一个文件时,内核会在内部生成一个打开文件对象,并在这个表里找到一个空项,让这一项指向生成的打开文件对象,并返回这一项的下标作为fd。由于这个表处于内核,并且用户无法访问到,因此用户即使拥有fd,也无法得到打开文件对象的地址,只能够通过系统提供的函数来操作。
在C语言里,操纵文件的渠道则是FILE结构,不难想象,C语言中的 FILE结构必定和fd有一对一的关系,每个FILE结构都会记录自己唯一对 应的fd。
2.2.2 文件打开多次(多句柄)
一个文件可以被打开多次(同一进程/不同进程),返回的文件指针、fd(文件描述符/句柄)、文件的读写指针(光标)都不同,都是独立的。
- 如果是不同进程中,因为打开文件表是每个进程私有的,得到的fd也是可能一样的。
被打开多次时:
- 记得要关闭多次
- 此时,文件是可以同时读写的,需要注意避免读写冲突:
- 如果打开模式是r/r+/w/w+,那写入的数据因为文件读写指针是独立的,所以会发生数据覆盖写入的问题。
- 如果打开模式是a/a+,那写入前会自动调整文件读写指针到文件末尾,此时就是多线程/多进程并发操作文件的效果。
所以,如果是多进程写日志的场景中,一个日志文件打开了多次,那写数据时,最好通过进程号标记每一条日志是由哪个进程写入的,因为各进程写入文件是随机的。
2.3 SQLite中的”连接“与”句柄“
SQLite作为应用或产品的嵌入式数据库,此时不是作为一个服务(server)在工作,对SQLite的操作,更类似于文件系统中,对本地文件的操作(打开/关闭)。API也很相似:(但为了跟MySQL等数据库系统看齐,有时候也称这个文件打开操作是个创建连接(Connection))
1 | struct sqlite3 { |
这个传出参数 ppDb 定义与C语言中的文件指针很相似,一点都不符合操作系统中对句柄的定义。不知道为什么SQLite中将其叫做句柄。不过注意点就好了,知道sqlite3中的句柄本质上是个文件指针,区别于Windows句柄就行。
三、SQLite 简单使用示例
1 | // SQLite初体验原生实现(了解) |
四、SQLite的两种日志模式
SQLite主要有两种日志模式(journal mode):DELETE模式和WAL(Write-Ahead Log)模式,默认是DELETE模式。
DELETE模式下,日志文件记录的是数据页变更前的内容。当事务开启时,将db-page的内容写入日志,写操作直接修改db-page,读操作也是直接读取db-page,db-page存储了事务最新的所有更新,当事务提交时直接删除日志文件即可,事务回滚时将日志文件覆盖db-page文件,恢复原始数据。
WAL:预写日志。是指在数据写入到数据库之前,先写入到日志。再将日志记录变更到存储器中。
WAL模式下,日志文件记录的是数据变更后的内容。当事务开启时,写操作不直接修改db-page,而是以append的方式追加到日志文件末尾,当事务提交时不会影响db-page,直接将日志文件覆盖到db-page即可,事务回滚时直接将日志文件去掉即可。读操作也是读取日志文件,开始读数据时会先扫描日志文件,看需要读的数据是否在日志文件中,如果在直接读取,否则从对应的db-page读取,并引入.shm文件,建立日志索引,采用哈希索引来加快日志扫描。
两种模式对读写并发的影响:
- DELETE模式下因为读写操作都是直接在db-page上面进行,因此读写操作必须串行执行。
- WAL模式下,读写操作都是在日志文件上进行,写操作会先append到日志文件末尾,而不是直接覆盖旧数据。而读操作开始时,会记下当前的日志文件状态,并且只访问在此之前的数据。这就确保了多线程读与读、读与写之间可以并发地进行。
- 更多关于WAL模式的内容可以阅读SQLite官方文档。
iOS中,如果使用了WAL模式,那么打开app沙盒里面的会有三种类型的文件:sqlite、sqlite-shm、sqlite-wal。
- sqlite-shm是共享内存(Shared Memory)文件,该文件里面会包含一份sqlite-wal文件的索引,系统会自动生成shm文件,所以删除它,下次运行还会生成。
- sqlite-wal是预写式日志(Write-Ahead Log)文件,这个文件里面会包含尚未提交的数据库事务,所以看见有这个文件了,就代表数据库里面还有还没有处理完的事务需要提交,所以说如果有sqlite-wal文件,再去打开sqlite文件,很可能最近一次数据库操作还没有执行。
在调试的时候,如果需要即时的观察数据库的变化,我们就可以先将日志模式设置为DELETE。
五、数据库的升级
5.1 数据库升级是指什么?
先弄清楚数据库、数据库系统的区别。
- 表(Table):以按行按列形式组织及展现的数据。一张表由表名、表中的字段和表的记录三个部分组成的。
- 数据库(Database):相互之间有关联关系的Table的集合。
- 数据库是电子化信息的集合。将信息规范化并使之电子化,形成电子信息 ‘库’,以便利用计算机对这些信息进行快速有效的存储、检索、统计与管理。
- 数据库管理系统(Database Management System,DBMS):能实现数据库的定义、操纵(增删改查)、控制(权限等)、维护(转储/恢复/重组/性能监测/分析)。
- 其实可以就是个SDK,一般提供命令行工具、编程API两种使用方式。
- 常见的有:MySQL、SQL Server、DB2、Oracle Database等。
一般移动端开发中的所说的数据库升级,无非就是对库、表的增删,对表结构(设计数据表结构就是定义数据表文件名,确定数据表包含哪些字段,各字段的字段名、字段类型、及宽度)的修改。
移动端中的数据库升级,需要考虑不同存量APP版本,升级时的不同处理:比如:
1 | // V1: 表A 表B |
服务端开发中,因为数据库升级,不需要考虑上面的存量用户使用问题,所以很简单,不值一提。所以一般服务端开发人员所说的数据库升级是指数据库管理系统升级,比如MySQL版本升级。
5.2 表结构修改的几种处理方式
数据库升级中库、表的增删不提,关于表结构修改的几种处理方式:
直接删除旧表,丢弃已存储数据,再新建新表(除非评估后,数据可留可删。否则不推荐)
如果SQLite支持要进行的操作:在已有表的基础上对表结构进行修改。(SQLite的ALTER TABLE命令非常局限,只支持重命名表以及添加新的字段。)
- 优点:能够保留数据
- 缺点:规则比较繁琐,要建立一个数据库的字段配置文件,然后读取配置文件,执行SQL修改表结构、约束和主键等等,涉及到跨多个版本的数据库升级就变得繁琐并且麻烦了
如果SQLite不支持要进行的操作,比如:列的删除操作、字段名、长度、类型等属性的修改,那此时老表就不能用了,需要进行数据迁移操作。
- 数据迁移:将旧表改名为临时表,然后创建新表 — 导入数据 — 删除临时表。(或者先创建临时表,把数据导入到临时表,然后删除旧表,把临时表更名为旧表的名称,也行)
- 优点:能够保留数据,支持表结构的修改,约束、主键的变更,实现起来比较简单
- 缺点:实现的步骤比较多
1
2
3
4
5
6
7
8# 创建临时表
create table [new_table](id integer primary key, name text)
# 导入数据
create table [new_table] as select id, name from [old_table]
# 删除旧表
drop table if exists [old_table]
# 重命名临时表
alter table [new_table] rename to [old_table]
5.3 数据库升级常见的几种方式
假如:
1 | // V1: 表A 表B |
5.3.1 最原始的SQLite
在Android中,SQLiteOpenHelper 类中有一个方法onUpgrade,当我们创建对象的时候如果传入的版本号大于之前的版本号,该方法就会被调用,通过判断oldVersion 和 newVersion 就可以决定如何升级数据库。(iOS同理,只不过需要自己维护版本号)
1 |
|
注意点:
- 要记录每个数据库版本的库、表结构
- 每次数据库有了新版本,都需要重写所有存量版本的 if 分支的升级处理。
5.3.2 只需记录每次迭代改动
谷歌在 2018 I/O 大会上发布了一系列辅助android开发者的实用工具,这套工具就是Jetpack,它是一套库、工具和指南的合集,可以帮助开发者更轻松地编写和构建出色的 Android 应用程序。
其中,ROOM就是 JetPack组件中的数据库框架。使用ROOM时,数据库升级时,只需要写出相比上次的更新就行。
1 | static final Migration MIGRATION_4_5 = new Migration(4,5) { |
iOS方面也有相同的库:FMDB README_MD中推荐了FMDBMigrationManager开源库,来做数据库升级。
根据官方文档的解释,有两种方法实现升级:
第一种:每次升级对应一个文件。所谓升级文件,就是一些sql文件,在里面写入一些对数据库操作的语句。
- 文件名的格式是固定的
(数字)_(描述性语言).sql。前面的数字就是所谓的版本号,官方建议使用时间戳,也可以使用1,2,3,4,5……升级,保持单调递增即可。 - 文件内写入要对数据库做的操作sql语句,比如
create table user(name TEXT, ....)。
1 | // DBPath是要升级的数据库的地址 |
第二种:使用自定义类的形式。
1 |
|
使用方法也很简单,将自定义类对象添加进manager即可。
1 | FMDBMigrationManager * manager=[FMDBMigrationManager managerWithDatabaseAtPath:DBPath migrationsBundle:[NSBundle mainBundle]]; |
看了一下实现代码,很简单,是根据版本号,循环将之前的数据库升级sql执行了一遍(简单粗暴)。而不是直接根据现有版本号与最新版本号,得出两者之间的差异,只做差异更新。
- 不知道google出版的roomdb是怎么做的。
- 不过,因为我们每次都是指定的升级sql,而不是当次升级至的数据库状态。通过每次的sql语句,比较指定两次的差异,也不是很好做吧?下面这种提供了ORM形式的数据库升级,应该可以做到直接比较(想到了git工作原理中,就是每次有)。
5.3.3 与ORM相结合的升级
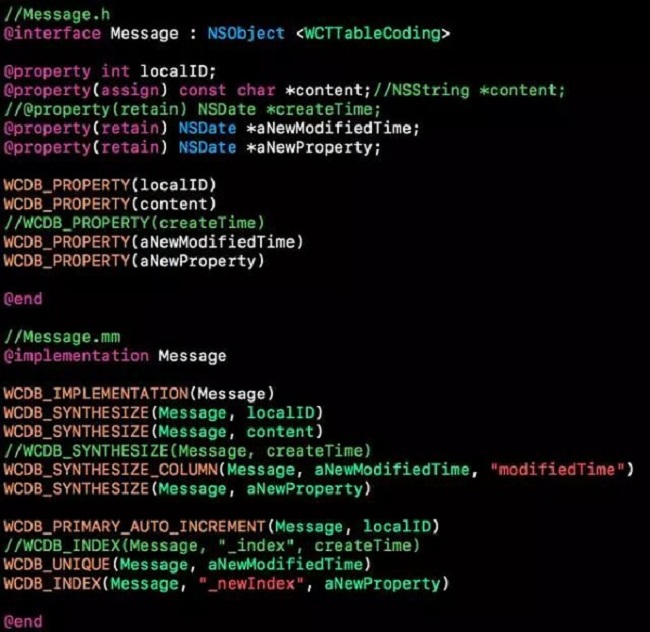
比如CoreData、WCDB等,以后者为例。
WCDB 将数据库升级和 ORM 结合起来,对于需要增删改的字段,只需直接在 ORM 层面修改,并再次调用 createTableAndIndexesOfName:withClass: 接口即可自动升级。以下是一个数据库升级的例子。
- 删除字段:如例子中的 createTime 字段,删除字段只需直接将 ORM 中的定义删除即可。
- 增加字段:如例子中的 aNewProperty 字段,增加字段只需直接添加 ORM 的定义即可。
- 修改字段类型:如例子中的 content 字段,字段类型可以直接修改,但需要确保新类型与旧类型兼容。
- 修改字段名称:如例子中的 aNewModifiedTime ,字段名称可以通过 WCDB_SYNTHESIZE_COLUMN(className, propertyName, columnName) 重新映射。
- 增加约束:如例子中的 WCDB_UNIQUE(Message, aNewModifiedTime) ,新的约束只需直接在 ORM 中添加即可。
- 增加索引:如例子中的 WCDB_INDEX(Message, “_newIndex”, aNewProperty) ,新的索引只需直接在 ORM 添加。
其他:有个ObjectBox,也支持ORM,跨平台 Android/iOS/Mac/Windows/Go。(Android同事用过),号称世界最快嵌入式数据库;体积小(最小压缩到增加体积1MB) ;函数设计简单优雅;支持DSL;支持监听数据库;浏览器查看数据库,仅查看;根据配置生成的JSON文件自动迁移;不支持嵌套对象。
六、SQLite的优化点
原文 — 微信iOS SQLite源码优化实践
随着微信iOS客户端业务的增长,在数据库上遇到的性能瓶颈也逐渐凸显。在微信的卡顿监控系统上,数据库相关的卡顿不断上升。而在用户侧也逐渐能感知到这种卡顿,尤其是有大量群聊、联系人和消息收发的重度用户。
我们在对SQLite进行优化的过程中发现,靠单纯地修改SQLite的参数配置,已经不能彻底解决问题。因此从6.3.16版本开始,我们合入了SQLite的源码,并开始进行源码层的优化。
本文将分享在SQLite源码上进行的多线程并发、I/O性能优化等,并介绍优化相关的SQLite原理。
6.1 多线程并发优化
6.1.1 背景
由于历史原因,旧版本的微信一直使用单句柄的方案,即所有线程共有一个SQLite Handle,并用线程锁避免多线程问题。当多线程并发时,各线程的数据库操作同步顺序进行,这就导致后来的线程会被阻塞较长的时间。
6.1.2 SQLite的多句柄方案及Busy Retry方案
SQLite 支持三种线程模式:(官方文档 — Using SQLite In Multi-Threaded Applications)
- 单线程(Single-thread) ,在此模式下,所有互斥锁都被禁用,并且SQLite连接不能在多个线程中使用。
- 多线程(Multi-thread),在此模式下,SQLite可以安全地由多个线程使用,前提是在两个或多个线程中不同时使用单个数据库连接。
- 串行(Serialized),在此模式下,SQLite可以被多个线程安全地使用而没有任何限制。(默认)
线程模式可以在以下三种时间设置:
- 编译时(从源代码编译 SQLite 库时)
- 启动时(当打算使用 SQLite 的应用程序正在初始化时)
- 运行时(当在应用程序中,创建新的 SQLite 数据库连接时)。
- 一般来说,运行时会覆盖启动时,启动时会覆盖编译时。注意:单线程模式一旦选择就不能被覆盖。
所以,SQLite实际是支持多线程(几乎)无锁地并发操作。只需
- 开启配置
PRAGMA SQLITE_THREADSAFE=2 - 确保同一个句柄同一时间只有一个线程在操作
Multi-thread. In this mode, SQLite can be safely used by multiple threads provided that no single database connection is used simultaneously in two or more threads.
倘若再开启SQLite的WAL模式(Write-Ahead-Log),多线程的并发性将得到进一步的提升。
此时写操作会先append到wal文件末尾,而不是直接覆盖旧数据。而读操作开始时,会记下当前的WAL文件状态,并且只访问在此之前的数据。这就确保了多线程读与读、读与写之间可以并发地进行。
然而,阻塞的情况并非不会发生。
- 当多线程写操作并发时,后来者还是必须在源码层等待之前的写操作完成后才能继续。
SQLite提供了Busy Retry的方案,即发生阻塞时,会触发Busy Handler,此时可以让线程休眠一段时间后,重新尝试操作。重试一定次数依然失败后,则返回SQLITE_BUSY错误码。
6.1.3 SQLite Busy Retry方案的不足
Busy Retry的方案虽然基本能解决问题,但对性能的压榨做的不够极致。在Retry过程中,休眠时间的长短和重试次数,是决定性能和操作成功率的关键。
然而,它们的最优值,因不同操作不同场景而不同。
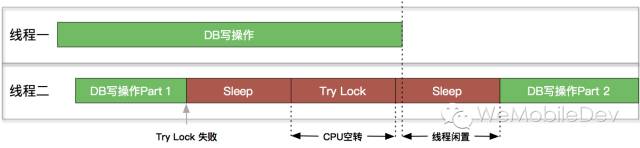
- 若休眠时间太短,使得重试次数太多,会空耗CPU的资源;(CPU重试加锁的时间里,是空转的,不响应任何别的工作程序。如下图中第二段红色Try Lock。)
- 若休眠时间过长,会造成等待的时间太长;(如下图第三段红色Sleep,CPU可用的情况下,因为sleep时间还没截止,会继续等待。)
- 若重试次数太少,则会降低操作的成功率。
我们通过A/B Test对不同的休眠时间进行了测试,得到了如下的结果:
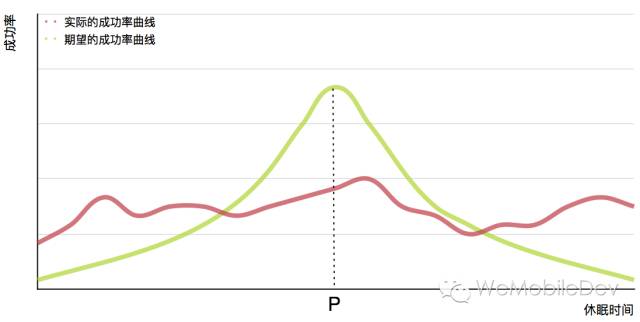
可以看到,倘若休眠时间与重试成功率的关系,按照绿色的曲线进行分布,那么p点的值也不失为该方案的一个次优解。然而事总不遂人愿,我们需要一个更好的方案。
6.1.4 SQLite中的线程锁及进程锁
作为有着十几年发展历史、且被广泛认可的数据库,SQLite的任何方案选择都是有其原因的。在完全理解由来之前,切忌盲目自信、直接上手修改。因此,首先要了解SQLite是如何控制并发的。
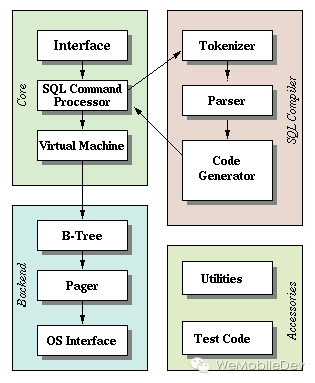
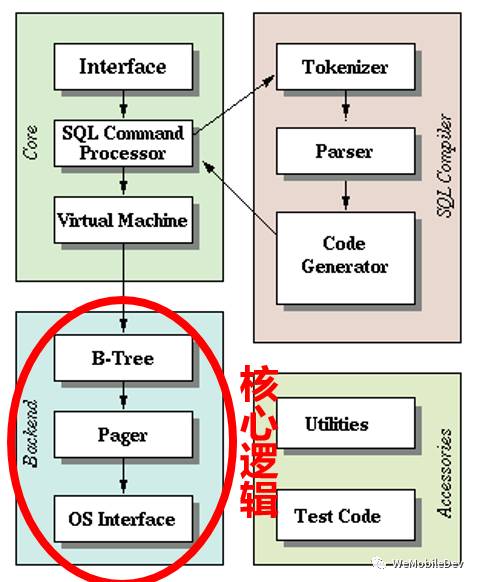
SQLite是一个适配不同平台的数据库,不仅支持多线程并发,还支持多进程并发。它的核心逻辑可以分为两部分:
- Core层。包括了接口层、编译器和虚拟机。通过接口传入SQL语句,由编译器编译SQL生成虚拟机的操作码opcode。而虚拟机是基于生成的操作码,控制Backend的行为。
- Backend层。由B-Tree、Pager、OS三部分组成,实现了数据库的存取数据的主要逻辑。
在架构最底端的OS层是对不同操作系统的系统调用的抽象层。它实现了一个VFS(Virtual File System),将OS层的接口在编译时映射到对应操作系统的系统调用。锁的实现也是在这里进行的。
SQLite通过两个锁来控制并发:
- 第一个锁对应DB文件,通过5种状态进行管理;
- 第二个锁对应WAL文件,通过修改一个16-bit的unsigned short int的每一个bit进行管理。
尽管锁的逻辑有一些复杂,但此处并不需关心。这两种锁最终都落在OS层的sqlite3OsLock、sqlite3OsUnlock和sqlite3OsShmLock上具体实现。
它们在锁的实现比较类似。以lock操作在iOS上的实现为例:
通过
pthread_mutex_lock进行线程锁,防止其他线程介入。然后比较状态量,若当前状态不可跳转,则返回SQLITE_BUSY通过
fcntl进行文件锁,防止其他进程介入。若锁失败,则返回SQLITE_BUSY多线程可以用多线程互斥量pthread_mutex_t实现线程之间上锁,那么多进程之间如何共享锁呢?
使用文件锁
flock实现多进程锁由于文件锁是存放到位于内存的系统文件表中, 所有进程/线程可通过系统访问。如果不同进程使用同一文件锁(写锁/排他锁),当取得文件锁时,进程可继续执行;如果没有取得锁,则阻塞等待。而唯一标识该文件的是文件路径,因此,可以通过一个共同的文件路径,来实现多进程锁机制。
使用多线程锁实现多进程锁
多线程之间天然共享内存/变量,而多进程各有自己的进程空间,它们之间是不共享数据的。2个关键步骤
1)互斥锁变量存放到共享内存;
2)设置互斥锁变量的进程共享属性(PTHREAD_PROCESS_SHARED);
而SQLite选择Busy Retry的方案的原因也正是在此---文件锁没有线程锁类似pthread_cond_signal的通知机制。当一个进程的数据库操作结束时,无法通过锁来第一时间通知到其他进程进行重试。因此只能退而求其次,通过多次休眠来进行尝试。
6.1.5 优化开始
通过上面的各种分析、准备,终于可以动手开始修改了。
我们知道,iOS app是单进程的,并没有多进程并发的需求,这和SQLite的设计初衷是不相同的。这就给我们的优化提供了理论上的基础。在iOS这一特定场景下,我们可以舍弃兼容性,提高并发性。
新的方案修改为,当OS层进行lock操作时:
- 通过
pthread_mutex_lock进行线程锁,防止其他线程介入。然后比较状态量,若当前状态不可跳转,则将当前期望跳转的状态,插入到一个FIFO的Queue尾部。最后,线程通过pthread_cond_wait进入休眠状态,等待其他线程的唤醒。 - 忽略文件锁
当OS层的unlock操作结束后:
- 取出Queue头部的状态量,并比较状态是否能够跳转。若能够跳转,则通过
pthread_cond_signal_thread_np唤醒对应的线程重试。
pthread_cond_signal_thread_np是Apple在pthread库中新增的接口,与pthread_cond_signal类似,它能唤醒一个等待条件锁的线程。不同的是,pthread_cond_signal_thread_np可以指定一个特定的线程进行唤醒。
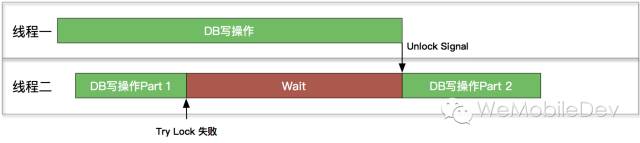
新的方案可以在DB空闲时的第一时间,通知到其他正在等待的线程,最大程度地降低了空等待的时间,且准确无误。此外,由于Queue的存在,当主线程被其他线程阻塞时,可以将主线程的操作“插队”到Queue的头部。当其他线程发起唤醒通知时,主线程可以有更高的优先级,从而降低用户可感知的卡顿。
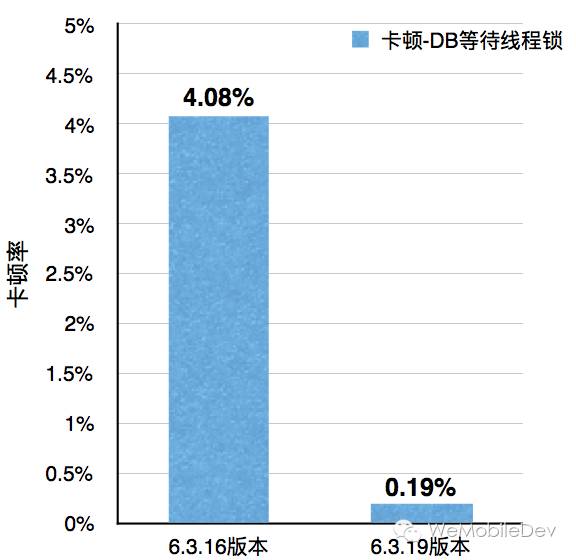
该方案上线后,卡顿检测系统检测到
- 等待线程锁的造成的卡顿下降超过90%
- SQLITE_BUSY的发生次数下降超过95%
6.2 I/O 性能优化
6.2.1 保留WAL文件大小
如上文多线程优化时提到,开启WAL模式后,写入的数据会先append到WAL文件的末尾。待文件增长到一定长度后,SQLite会进行checkpoint。这个长度默认为1000个页大小,在iOS上约为3.9MB。
同样的,在数据库关闭时,SQLite也会进行checkpoint。不同的是,checkpoint成功之后,会将WAL文件长度删除或truncate到0。下次打开数据库,并写入数据时,WAL文件需要重新增长。而对于文件系统来说,这就意味着需要消耗时间重新寻找合适的文件块。
显然SQLite的设计是针对容量较小的设备,尤其是在十几年前的那个年代,这样的设备并不在少数。而随着硬盘价格日益降低,对于像iPhone这样的设备,几MB的空间已经不再是需要斤斤计较的了。
因此我们可以修改为:
- 数据库关闭并checkpoint成功时,不再truncate或删除WAL文件只修改WAL的文件头的Magic Number。下次数据库打开时,SQLite会识别到WAL文件不可用,重新从头开始写入。
保留WAL文件大小后,每个数据库都会有这约3.9MB的额外空间占用。如果数据库较多,这些空间还是不可忽略的。因此,微信中目前只对读写频繁且检测到卡顿的数据库开启,如聊天记录数据库。
6.2.2 mmap优化
mmap对I/O性能的提升无需赘言,尤其是对于读操作。SQLite也在OS层封装了mmap的接口,可以无缝地切换mmap和普通的I/O接口。只需配置 PRAGMA mmap_size=XXX 即可开启mmap。
There are advantages and disadvantages to using memory-mapped I/O. Advantages include:
Many operations, especially I/O intensive operations, can be much faster since content does need to be copied between kernel space and user space. In some cases, performance can nearly double.
The SQLite library may need less RAM since it shares pages with the operating-system page cache and does not always need its own copy of working pages.
使用内存映射 I/O 有利有弊。优点包括:
- 许多操作,尤其是 I/O 密集型操作,可以更快。因为内容不再需要在内核空间和用户空间之间复制。在某些情况下,性能几乎可以翻倍。
- SQLite 库可能需要更少的 RAM,因为它与操作系统页面缓存(page cache)共享pages,而且并不总是需要自己的工作页面(working pages)副本。
然而,你在iOS上这样配置恐怕不会有任何效果。因为早期的iOS版本的存在一些bug,SQLite在编译层就关闭了在iOS上对mmap的支持,并且后知后觉地在16年1月才重新打开。所以如果使用的SQLite版本较低,还需注释掉相关代码后,重新编译生成后,才可以享受上mmap的性能。
开启mmap后,SQLite性能将有所提升,但这还不够。因为它只会对DB文件进行了mmap,而WAL文件享受不到这个优化。
WAL文件长度是可能变短的,而在多句柄下,对WAL文件的操作是并行的。一旦某个句柄将WAL文件缩短了,而没有一个通知机制让其他句柄更新mmap的内容。此时其他句柄若使用mmap操作已被缩短的内容,就会造成crash。而普通的I/O接口,则只会返回错误,不会造成crash。因此,SQLite没有实现对WAL文件的mmap。
还记得我们上一个优化吗?没错,我们保留了WAL文件的大小。因此它在这个场景下是不会缩短的,那么不能mmap的条件就被打破了。实现上,只需在WAL文件打开时,用unixMapfile将其映射到内存中,SQLite的OS层即会自动识别,将普通的I/O接口切换到mmap上。
6.3 其他优化
6.3.1 禁用文件锁
如我们在多线程优化时所说,对于iOS app并没有多进程的需求。因此我们可以直接注释掉os_unix.c中所有文件锁相关的操作。
也许你会很奇怪,虽然没有文件锁的需求,但这个操作耗时也很短,是否有必要特意优化呢?其实并不全然。耗时多少是比出来。
SQLite中有cache机制。被加载进内存的page,使用完毕后不会立刻释放。而是在一定范围内通过LRU的算法更新page cache。这就意味着,如果cache设置得当,大部分读操作都不会读取新的page。然而因为文件锁的存在,本来这个只需在内存层面进行的读操作,不得不进行至少一次I/O操作。而我们知道,I/O操作是远远慢于内存操作的。
6.3.2 禁用内存统计锁
SQLite会对申请的内存进行统计,而这些统计的数据都是放到同一个全局变量里进行计算的。这就意味着统计前后,都是需要加线程锁,防止出现多线程问题的。

内存申请虽然不是非常耗时的操作,但却很频繁。多线程并发时,各线程很容易互相阻塞。
阻塞虽然也很短暂,但频繁地切换线程,却是个很影响性能的操作,尤其是单核设备。
因此,如果不需要内存统计的特性,可以通过sqlite3_config(SQLITE_CONFIG_MEMSTATUS, 0)进行关闭。这个修改虽然不需要改动源码,但如果不查看源码,恐怕是比较难发现的。
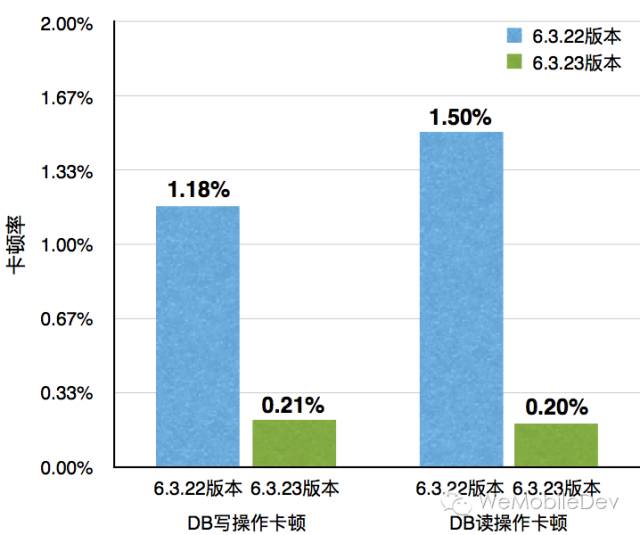
优化上线后,卡顿监控系统监测到
- DB写操作造成的卡顿下降超过80%
- DB读操作造成的卡顿下降超过85%
6.4 数据库修复
数据库修复指的是通过技术手段将损坏的数据库文件修复至可正常使用的数据库文件的过程。
6.4.1 前言
众所周知,微信在后台服务器不保存聊天记录,微信在移动客户端所有的聊天记录都存储在一个 SQLite 数据库中,一旦这个数据库损坏,将会丢失用户多年的聊天记录。而我们监控到现网的损坏率是0.02%,也就是每 1w 个用户就有 2 个会遇到数据库损坏。考虑到微信这么庞大的用户基数,这个损坏率就很严重了。更严重的是我们用的官方修复算法,修复成功率只有 30%。损坏率高,修复率低,这两个问题都需要我们着手解决。
6.4.2 SQLite 损坏原因及其优化(降低损坏率)
我们首先来看 SQLite 损坏的原因,SQLite官网(http://www.sqlite.org/howtocorrupt.html)上列出以下几点:
- 文件错写
- 文件锁 bug
- 文件 sync 失败
- 设备损坏
- 内存覆盖
- 操作系统 bug
- SQLite bug
但是我们通过收集到的大量案例和日志,分析出实际上移动端数据库损坏的真正原因其实就3个:
- 空间不足
- 设备断电
- 文件 sync 失败
我们需要针对这些原因一一进行优化。
1. 优化空间占用
首先我们来优化微信的空间占用问题。在这之前微信的部分业务也做了空间清理,例如朋友圈会自动删除7天前缓存的图片。但是总的来说对文件空间的使用缺乏一个全局把控,全靠各个业务自觉。我们需要做得更积极主动,要让开发人员意识到用户的存储空间是宝贵的。我们采取以下措施:
- 业务文件先申请后使用,如果某个文件没有申请就使用了,会被自动扫描出来并删除;
- 每个业务文件都要申明有效期,是一天、一个星期、一个月还是永久存储;
- 过期文件会被自动清理。

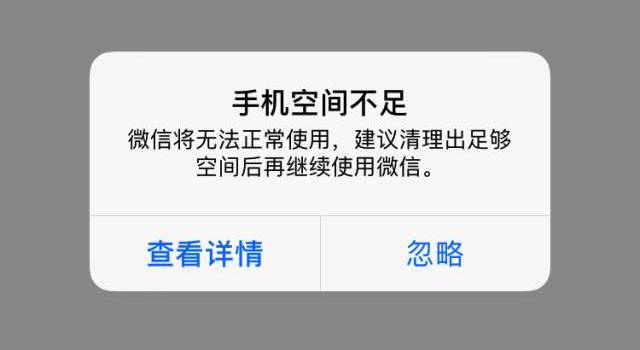
对于微信之外的空间占用,例如相册、视频、其他App的空间占用,微信本身是做不了什么事情的,我们可以提示用户进行空间清理:
2. 优化文件 sync
1) synchronous = FULL
设置SQLite的文件同步机制为全同步,亦即要求每个事务的写操作是真的flush到文件里去。
2) fullfsync = 1
通过与苹果工程师的交流,我们发现在 iOS 平台下还有 fullfsync (https://www.sqlite.org/pragma.html#pragma_fullfsync) 这个选项,可以严格保证写入顺序跟提交顺序一致。设备开发商为了测评数据好看,往往会对提交的数据进行重排,再统一写入,亦即写入顺序跟App提交的顺序不一致。在某些情况下,例如断电,就可能导致写入文件不一致的情况,导致文件损坏。
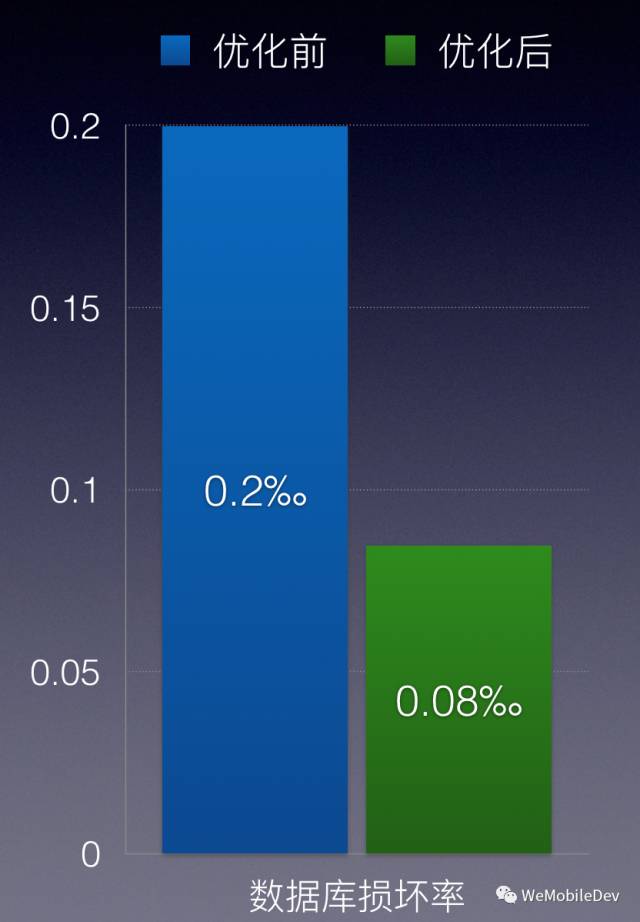
3. 优化效果
多管齐下之后,我们成功将损坏率降低了一半多;DB损坏还是无法完全避免,我们还是得提高修复成功率。
6.4.3 SQLite 修复逻辑优化(提高修复率)
长久以来SQLite DB都有损坏问题,从Android、iOS等移动系统,到Windows、Linux 等桌面系统都会出现。由于微信所有消息都保存在DB,服务端不保留备份,一旦损坏将导致用户消息数据丢失,显然不能接受。
下面介绍一下微信数据库修复的具体方案和发展历程。
1. 我们的需求
具体来说,微信需要一套满足以下条件的DB恢复方案:
- 恢复成功率高。 由于牵涉到用户核心数据,“姑且一试”的方案是不够的,虽说 100% 成功率不太现实,但 90% 甚至 99% 以上的成功率才是我们想要的。
- 支持加密DB。 Android 端微信客户端使用的是加密 SQLCipher DB,加密会改变信息 的排布,往往对密文一个字节的改动就能使解密后一大片数据变得面目全非。这对于数据恢复 不是什么好消息,我们的方案必须应对这种情况。
- 能处理超大的数据量。 经过统计分析,个别重度用户DB大小已经超过2GB,恢复方案 必须在如此大的数据量下面保证不掉链子。
- 不影响体验。 统计发现只有万分之一不到的用户会发生DB损坏,如果恢复方案 需要事先准备(比如备份),它必须对用户不可见,不能为了极个别牺牲全体用户的体验。
经过多年的不断改进,微信先后采用出三套不同的DB恢复方案,离上面的目标已经越来越近了。
2. sql_master表介绍
首先我们来看 SQLite 的架构。SQLite 使用 B+树 存储一个表,整个 SQLite 数据库就是这些 B+树 组成的森林。
- 每个表的元数据,都记录在一个叫 sql_master 的表中。
- 这个 sql_master 表(下面有些场景简称 master 表) 本身也是一个 B+树 存储的普通表。DB 第0页就是他的根节点。
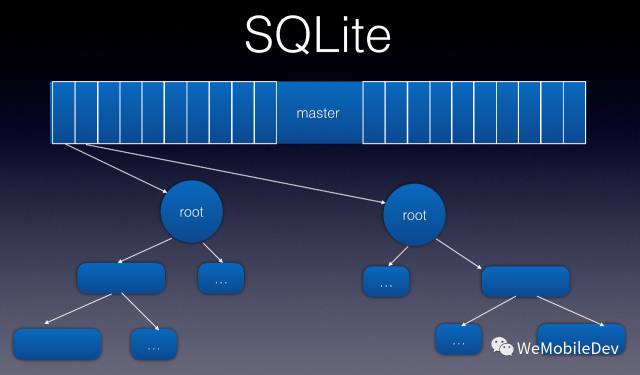
sqlite_master是一个每个SQLite DB都有的特殊的表, 无论是查看官方文档Database File Format,还是执行SQL语句 SELECT * FROM sqlite_master;,都可得知这个SQLite的系统表中保存着数据库中所有的其他表、索引(indexes)、触发器(triggers)、视图(views)的元数据:表名、类型(table/index)、创建此表/索引的SQL语句,以及表的RootPage。(只包括table本身的信息即元数据,不包括里面的数据哦)
sqlite_master 每一行记录一个项目。在创建一个SQLIte数据库的时候,该表会自动创建。sqlite_master的表名、表结构都是固定的:
- type:是以下文本字符串之一:“table”、“index”、“view”或“trigger”,具体取决于定义的对象类型。 ‘table’ 字符串用于普通表和虚拟表。
- name:保存对象的名称。
- tbl_name:包含与对象关联的表或视图的名称。
- 对于表或视图,tbl_name 列是 name 列的副本。
- 对于索引,tbl_name 是被索引的表的名称。
- 对于触发器,tbl_name 列存储导致触发器触发的表或视图的名称。
- rootpage:存储表和索引的 b-tree 根节点的 page 号。对于描述视图、触发器和虚拟表(virtual tables)的行,rootpage 列是 0 或 NULL。
- sql:存储描述对象的 SQL 文本。此 SQL 文本是 CREATE TABLE、CREATE VIRTUAL TABLE、CREATE INDEX、CREATE VIEW 或 CREATE TRIGGER 语句。
- 更详细的说明,可以见上面的官方文档链接

正常情况下,SQLite 引擎打开DB后首次使用,需要先遍历 sqlite_master,并将里面保存的SQL语句再解析一遍, 保存在内存中供后续编译SQL语句时使用。
由于sqlite_master表存储所有的数据库项目,所以可以通过该表判断特定的表、视图或者索引是否存在。例如,以下语句可以判断user表是否存在。
1 | select count(*) from sqlite_master where name='user' and type='table' |
3. 方案一:官方的Dump恢复方案
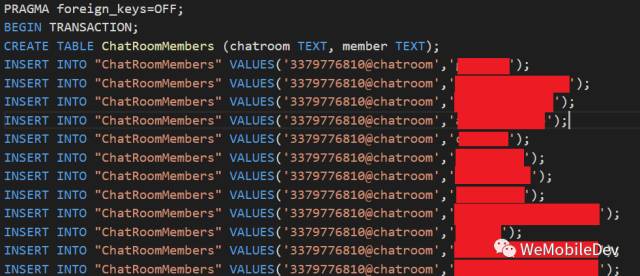
Google 一下SQLite DB恢复,不难搜到使用.dump命令恢复DB的方法。.dump命令的作用是将 整个数据库的内容输出为很多 SQL 语句,只要对空 DB 执行这些语句就能得到一个一样的 DB。
.dump命令原理很简单:
- 每个SQLite DB都有一个
sqlite_master表。遍历它得到所有表的名称和CREATE TABLE ...的SQL语句,输出CREATE TABLE语句。 - 根据根节点地址和创表语句接着使用
SELECT * FROM ...通过表名遍历整个表,每读出一行就输出一个INSERT语句,遍历完后就把整个DB dump出来了(能 select 多少是多少)。
这样的操作,和普通查表是一样的,遇到损坏一样会返回SQLITE_CORRUPT,我们忽略掉损坏错误,继续遍历下个表,最终可以把所有没损坏的表以及损坏了的表的前半部分读取出来。将dump 出来的SQL语句逐行执行,最终可以得到一个等效的新DB。由于直接跑在SQLite上层,所以天然 就支持加密SQLCipher,不需要额外处理。
下图是dump输出样例:
优点:
- 这个方案不需要任何准备,只有坏DB的用户要花好几分钟跑恢复,大部分用户是不感知的。
缺点:
- 数据量大小,主要影响恢复需要的临时空间:先要保存 dump 出来的SQL的空间,这个大概一倍DB大小,还要另外一倍 DB大小来新建 DB恢复。
- 至于我们最关心的成功率呢?上线后,成功率约为30%。这个成功率的定义是至少恢复了一条记录,也就是说一大半用户 一条都恢复不成功!研究一下就发现,恢复失败的用户,原因都是
sqlite_master表读不出来。
官方修复算法率低下原因 — 太依赖 master 表:
前面说过,master 表他本身也是一个 B+树 形式的普通表,DB 第0页就是他的根节点。那么只要 master 表某个节点损坏,这个节点下面记录的表就都恢复不了。更坏的情况是 DB 第0页损坏,那么整个 master 表都读不出来,就导致整个DB都恢复失败。这就是官方修复算法成功率这么低的原因,太依赖 master 表了。
恢复率这么低的尴尬状况维持了好久, 其他方案才渐渐露出水面。
4. 方案二:备份恢复方案
损坏的数据无法修复,最直观的解决方案就是备份,于是备份恢复方案被提上日程了。备份恢复这个方案思路简单,SQLite 也有不少备份机制可以使用,具体是:
- 拷贝: 不能再直白的方式。由于SQLite DB本身是文件(主DB + journal 或 WAL), 直接把文件复制就能达到备份的目的。
- Dump: 上一个恢复方案用到的命令的本来目的。在DB完好的时候执行
.dump, 把 DB所有内容输出为 SQL语句,达到备份目的,恢复的时候执行SQL即可。 - Backup API: SQLite自身提供的一套备份机制,按 Page 为单位复制到新 DB, 支持热备份。
这么多的方案孰优孰劣?作为一个移动APP,我们关心的无非就是 备份大小、备份性能、 恢复性能 几个指标。微信作为一个重度DB使用者,备份大小和备份性能是主要关注点: 原本用户就可能有2GB 大的 DB,如果备份数据本身也有2GB 大小,用户想必不会接受; 性能则主要影响体验和备份成功率,作为用户不感知的功能,占用太多系统资源造成卡顿是不行的,备份耗时越久,被系统杀死等意外事件发生的概率也越高。
对以上方案做简单测试后,备份方案也就基本定下了。下图是备选方案性能对比(测试用的DB大小约 50MB, 数据条目数大约为 10万条):
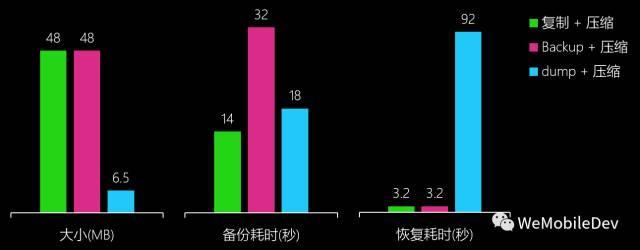
可以看出,比较折中的选择是 Dump + 压缩,备份大小具有明显优势,备份性能尚可, 恢复性能较差但由于需要恢复的场景较少,算是可以接受的短板。
微信在Dump + gzip方案上再加以优化:
- 由于格式化SQL语句输出耗时较长,因此使用了自定义的二进制格式承载Dump输出。
- 由于数据保密需要,二进制Dump数据也做了加密处理。
- 采用自定义二进制格式还有一个好处是,恢复的时候不需要重复的编译SQL语句,编译一次就可以插入整个表的数据了,恢复性能也有一定提升。
- 第二耗时的压缩操作则放到别的线程同时进行,在双核以上的环境基本可以做到无额外时间消耗。
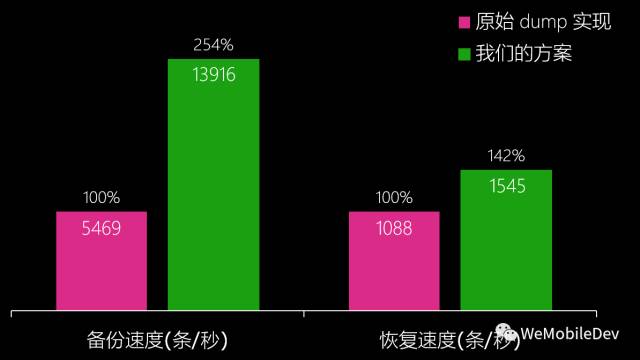
相比原始的Dump + 压缩,优化后的方案每秒备份行数提升了 150%,每秒恢复行数也提升了 40% (性能优化效果如下图)。
即使优化后的方案,对于特大DB备份也是耗时耗电。对于移动APP来说,可能未必有这样的机会做这样重度的操作,或者频繁备份会导致卡顿,这也是需要开发者衡量的。比如Android微信会选择在 充电并灭屏 时进行DB备份,若备份过程中退出以上状态,备份会中止,等待下次机会。
备份方案上线后,恢复成功率达到72%,但有部分重度用户DB损坏时,由于备份耗时太久, 始终没有成功,而对DB数据丢失更为敏感的也恰恰是这些用户,于是新方案应运而生。
5. 方案三:解析B-tree恢复方案(RepairKit)
备份方案的高消耗迫使我们从另外的方案考虑,于是我们再次把注意力放在之前的Dump方案。 Dump 方案本质上是尝试从坏DB里读出信息,这个尝试一般来说会出现两种结果:
- DB的基本格式仍然健在,但个别数据损坏,读到损坏的地方SQLite返回
SQLITE_CORRUPT错误, 但已读到的数据得以恢复。 - 基本格式丢失(文件头或
sqlite_master损坏),获取有哪些表的时候就返回SQLITE_CORRUPT,根本没法恢复。
第一种可以算是预期行为,毕竟没有损坏的数据能 部分恢复。从之前的数据看, 不少用户遇到的是第二种情况,这种有没挽救的余地呢? —— sqlite_master 损坏时的修复方案。
1) 方案:自实现数据读取系统
假如sqlite_master损坏了无法解析,“Dump恢复”这种走正常SQLite 流程的方法,自然会卡在第一步了。
为了让sqlite_master受损的DB也能打开,需要想办法绕过SQLite引擎的逻辑。 由于SQLite引擎初始化逻辑比较复杂,为了避免副作用,没有采用hack的方式复用其逻辑,而是决定仿造一个只可以读取数据的最小化系统。
虽然仿造最小化系统可以跳过很多正确性校验,但也需要一些必须的数据:
2) 关键点1 — sqlite_master备份
sqlite_master里保存的信息对恢复来说也是十分重要的, 特别是RootPage,因为它是表对应的B-tree结构的根节点所在地,没有了它我们甚至不知道从哪里开始解析对应的表。
sqlite_master信息量比较小,因此对它进行备份成本是非常低的,一般手机典型只需要几毫秒到数十毫秒即可完成,一致性也容易保证, 只需要执行了上述语句的时候重新备份一次即可。
备份时机:
我们只需要每隔一段时间轮询 master 表,看看最近有没有增删 table,有的话就全量备份。
这里有个担忧,就是普通数据表的插入会不会导致表的根节点发生变化,也就是说 master 表会不会频繁变化,如果变化很频繁的话,我们就不能简单地进行轮询方案了。通过分析源码,我们发现 SQLite 里面 B+树 算法的实现是 向下分裂 的,也就是说当一个叶子页满了需要分裂时,原来的叶子页会成为内部节点,然后新申请两个页作为他的叶子页。这就保证了根节点一旦定下来,是再也不会变动的。实际的代码调试也证实了我们这个推论。所以说 master 表只会在新创建表、删除表、修改表结构时(例如执行了CREATE TABLE、ALTER TABLE 等语句)才会发生变化,我们完全可以采用定时轮询方案。
备份文件有效性
接下来的难题是既然 DB 可以损坏,那么这个备份文件也会损坏,怎么办呢?我们采用了 双备份 的机制。具体来说就是:
- 会有新旧两个备份文件,每个文件头都加上 CRC 校验;
- 每次备份时,从两个备份文件中选出一个进行覆盖。具体怎么选呢?
- 优先选损坏那个备份文件,如果两个都有效,那么就选相对较旧的。这就保证了即使本次写入导致文件损坏,还有另外一份备份可以用。
- 这个做法跟 Realm 标榜的 MVCC(多版本并发控制)的做法有异曲同工之妙,相当于确认新写入的文件有效之后,才使用新写入的文件,否则还是继续用旧的有效的文件。
前面提到 DB 损坏的一个常见场景是空间不足,这种情况下还要分配文件空间给备份文件也是会失败的。为了解决这个问题,我们采取 预先分配空间 的做法,初始值是 32K,大约可存 750 个表的元信息,后续则按照32K的倍数进行增长。
有了备份,我们的逻辑可以在读取DB自带的sqlite_master失败的时候使用备份的信息来代替。
3) 关键点2 — 加解密
DB初始化的问题除了文件头和sqlite_master完整性外,还有加密。
SQLCipher加密数据库,对应的恢复逻辑还需要加上解密逻辑。按照SQLCipher的实现,加密DB 是按page 进行包括头部的完整加密,所用的密钥是根据用户输入的原始密码和创建DB 时随机生成的 salt 运算后得出的。可以猜想得到,如果保存salt错了,将没有办法得出之前加密用的密钥,导致所有page都无法读出了。由于salt 是创建DB时随机生成,后续不再修改,将它纳入到备份的范围内即可。
4) 实现
到此,初始化必须的数据就保证了,可以仿造读取逻辑了。
- 我们常规使用的读取DB的方法(包括dump方式恢复),都是通过执行SQL语句实现的,这牵涉到SQLite系统最复杂的子系统——SQL执行引擎。我们的恢复任务只需要遍历B-tree所有节点, 读出数据即可完成,不需要复杂的查询逻辑,因此最复杂的SQL引擎可以省略。
- 同时,因为我们的系统是只读的, 写入恢复数据到新 DB 只要直接调用 SQLite 接口即可,因而可以省略同样比较复杂的B-tree平衡、Journal和同步等逻辑。
- 最后恢复用的最小系统只需要:
- VFS读取部分的接口(Open/Read/Close),或者直接用stdio的fopen/fread、Posix的open/read也可以
- SQLCipher的解密逻辑:加密 SQLCipher 情况较为复杂,幸好SQLCipher 加密部分可以单独抽出,直接套用其解密逻辑。
- B-tree解析逻辑:Database File Format 详细描述了SQLite文件格式, 参照之实现B-tree解析可读取 SQLite DB。
即可实现。最小化系统如图所示:
5) 注意点 — 列的补全
实现了上面的逻辑,就能读出DB的数据进行恢复了,但还有一个小插曲。
- 我们知道,使用SQLite查询一个表, 每一行的列数都是一致的,这是Schema层面保证的。但是在Schema的下面一层——B-tree层,没有这个保证。 B-tree的每一行(或者说每个entry、每个record)可以有不同的列数,一般来说,SQLite插入一行时, B-tree里面的列数和实际表的列数是一致的。
- 但是当对一个表进行了
ALTER TABLE ADD COLUMN操作, 整个表都增加了一列,但已经存在的B-tree行实际上没有做改动,还是维持原来的列数。 当SQLite查询到ALTER TABLE前的行,缺少的列会自动用默认值补全。 - 恢复的时候,也需要做同样的判断和支持, 否则会出现缺列而无法插入到新的DB。
6) 优化效果
解析B-tree方案上线后,成功率约为78%。这个成功率计算方法为恢复成功的 Page 数除以总 Page 数。 由于是我们自己的系统,可以得知总 Page 数,使用恢复 Page 数比例的计算方法比人数更能反映真实情况。
B-tree解析好处是准备成本较低,不需要经常更新备份,对大部分表比较少的应用备份开销也小到几乎可以忽略, 成功恢复后能还原损坏时最新的数据,不受备份时限影响。 坏处是,和Dump一样,如果损坏到表的中间部分,比如非叶子节点,将导致后续数据无法读出。
6. 不同方案的组合
由于解析B-tree恢复原理和备份恢复不同,失败场景也有差别,可以两种手段混合使用覆盖更多损坏场景。 微信的数据库中,有部分数据是临时或者可从服务端拉取的,这部分数据可以选择不修复,有些数据是不可恢复或者 恢复成本高的,就需要修复了。
- 如果修复过程一路都是成功的,那无疑使用B-tree解析修复效果要好于备份恢复。备份恢复由于存在时效性,总有部分最新的记录会丢掉,解析修复由于直接基于损坏DB来操作,不存在时效性问题。 假如损坏部分位于不需要修复的部分,解析修复有可能不发生任何错误而完成。
- 如果修复过程遇到错误,则很可能是需要修复的B-tree损坏了,这会导致需要修复的表发生部分或全部缺失。 这个时候再使用备份修复,能挽救一些缺失的部分。
- 最早的Dump修复,场景已经基本被B-tree解析修复覆盖了,若B-tree修复不成功,Dump恢复也很有可能不会成功。 即便如此,假如上面的所有尝试都失败,最后还是会尝试Dump恢复。
恢复方案组合如图所示:

上面说的三种修复方法,原理上只涉及到SQLite文件格式以及基本的文件系统,是跨平台的。 实际操作上,各个平台可以利用各自的特性做策略上的调整,比如 Android 系统使用 JobScheduler 在充电灭屏状态下备份。
6.4.4 小结
通过这些优化,我们提高了微信聊天记录存储的可靠性。这些优化实践,会同上面在并发、IO性能方面的优化实践(微信iOS SQLite源码优化实践),将会合并到微信即将开源的 WCDB(WeChat Database)组件中。
6.5 小结
移动客户端数据库虽然不如后台数据库那么复杂,但也存在着不少可挖掘的技术点。本次尝试了仅对SQLite原有的方案进行优化,而市面上还有许多优秀的数据库,如LevelDB、RocksDB、Realm等,它们采用了和SQLite不同的实现原理。后续我们将借鉴它们的优化经验,尝试更深入的优化。
七、SQLite多线程解决方案
7.1 FMDB中的多线程 — 转串行
FMDB 是基于 SQLite 的数据库框架,使用 Objective-C 语言对 SQLite 的 C 语言接口做了一层面向对象的封装,并通过一个 Serial 队列保证在多线程环境下的数据安全。
FMDB 提供了 FMDatabase 类,该类与数据库文件一一对应,在新建一个 FMDatabase 对象时,可以关联一个已有的数据库文件;该对象以面向对象思想封装了增、删、改、查、事务等常用的数据库操作。但是FMDatabase 不是线程安全 的,在多个线程之间使用同一个FMDatabase可能会出现数据错误。
对于线程安全 FMDB 提供了FMDatabaseQueue 和 FMDatabasePool 。
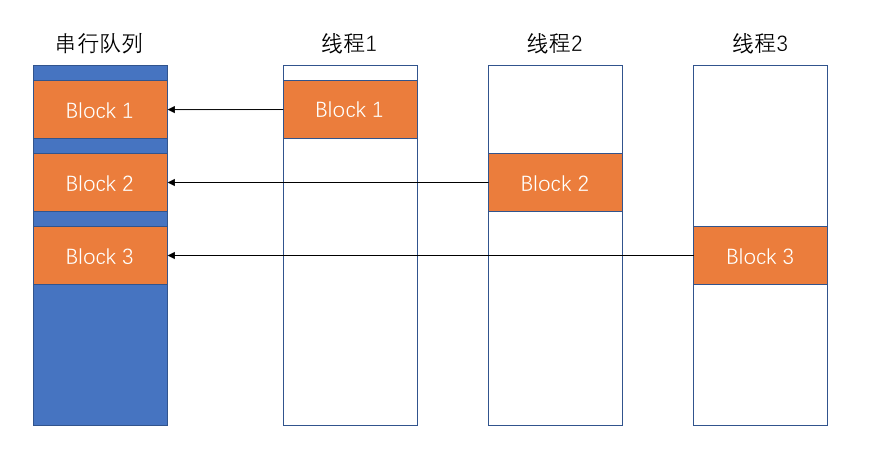
FMDatabaseQueue持有 SQLite 句柄,多个线程使用同一个句柄,同时在初始化时创建了一个串行队列,当在多线程之间执行数据库操作时,FMDatabaseQueue将数据库操作以 block 的形式添加到该串行队列,然后按接收顺序同步执行,以此来保证数据库在多线程下的数据安全。FMDatabasePool实现原理和FMDatabaseQueue一样,它的使用更加灵活,但是容易造成死锁,不推荐使用。
FMDatabaseQueue原理:让各个线程的数据库操作按顺序同步执行。
示例:
创建FMDatabaseQueue:
1 | NSString *documentPath = [NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES) lastObject]; |
多线程操作数据库:
1 | dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0); |
运行结果:

数据库结果:
7.2 WCDB
WCDB 是微信团队推出的一个高效、完整、易用的移动数据库框架,基于 SQLCipher(SQLite的加密扩展),支持 iOS,mac OS 和 Android。
WCDB 通过 SQLite 多句柄 和 WAL 日志模式 来支持线程间读与读、读与写操作并发执行,并通过优化 Busy Retry 方案 来提升线程间写与写操作串行执行的效率。(实现细节见6.1节)
WCDB 内置一个句柄池HandlePool,由它管理和分发 SQLite 句柄。WCDB 提供的WCTDatabase、WCTTable和WCTTransaction的所有 SQL 操作接口都是线程安全,它们不直接持有数据库句柄,而是由HandlePool根据数据库访问所在的线程、是否处于事务、并发状态等,自动分发合适的 SQLite 连接进行操作,以此来保证同一个句柄在同一时间只有一个线程在操作,从而达到读与读、读与写并发的效果。
7.3 性能对比
以下测试数据来自 WCDB性能数据与Benchmark
这里主要对比 FMDB 和 WCDB。
如无特殊说明,SQLite配置均为WAL模式、缓存大小2000字节、页大小4 kb:
PRAGMA cache_size=-2000PRAGMA page_size=4096PRAGMA journal_mode=WAL
测试数据均为含有一个整型和一个二进制数据的表:CREATE TABLE benchmark(key INTEGER, value BLOB),二进制数据长度为100字节。
7.3.1 Baseline
- 读操作性能测试:该测试为从数据库中取出所有数据,并拼装为object。

- 写操作性能测试:该测试为将object的数据不断插入到数据库中(不使用事务)。

- 批量写操作性能测试:该测试为将object的数据批量插入数据库(使用事务)。

WCDB写操作和批量写操作的性能分别优于FMDB 28% 和 180% ,而读操作则劣于FMDB 5% 。
对于读操作,SQLite速度很快,因此封装层的消耗会占比较多。FMDB只做了最简单的封装, 而WCDB还包括ORM、WINQ等操作,因此执行的指令会比FMDB多,从而导致性能稍差于FMDB。但WCDB也通过一些优化手段减少这种差距。例如,通过IMP指针调用函数、部分操作No-ARC等等。
而写操作,WCDB也做了许多针对性的优化。例如,WAL模式下写入操作触发checkpoint时,不立即执行checkpoint,而是由一个checkpoint线程来完成,从而减少单次操作的耗时等等。
7.3.2 Multithread
- 多线程读操作性能测试:该测试同时启动两个线程,分别从数据库中取出所有数据,并拼装为object。

- 多线程读写操作性能测试:该测试同时启动两个线程,一个线程从数据库中取出所有数据,并拼装为object;另一个将object的数据批量插入到数据库中。

- 多线程写操作性能测试:该测试同时启动两个线程,分别将object的数据批量插入数据库。

WCDB 的多线程读写操作性能优于 FMDB 62% ,而多线程读操作基本与 FMDB 持平(FMDB 只对 SQLite 做了最简单的封装, 而 WCDB 还包括ORM、WINQ等操作,执行的指令会比 FMDB 多,因此在多线程读测试中没有表现出明显的优势)。
FMDB在多线程写测试中,直接触发了 Busy Retry ,返回错误SQLITE_BUSY,因此无法比较。而WCDB通过优化Busy Retry,多线程写操作实质也是串行执行,但不会出错导致操作中断。
7.4 小结
FMDB 采用串行队列来保证线程安全,并且采用单句柄方案,即所有线程共用一个SQLite Handle。在多线程并发时,虽然能够使各个线程的数据库操作按顺序同步进行,保证了数据安全,但正是因为各线程同步进行,导致后来的线程会被阻塞较长时间,无论是读操作还是写操作,都必须等待前面的线程执行完毕,使得性能无法得到更好的保障。
WCDB 内置了一个句柄池,根据各个线程的情况派发数据库句柄,通过多句柄方案来实现线程间读与读、读与写并发执行,并开启SQLite的WAL日志模式进一步提高多线程的并发性。同时 WCDB 修改了SQLite的内部实现,优化了 Busy Retry 方案,禁用了文件锁并添加队列来支持主动唤醒等待的线程,以此来提高线程间写与写串行执行的效率。
WCDB 在多线程方面明显优于 FMDB。