
原文,摘自 Advanced Graphics and Animations for iOS Apps (WWDC14 419,关于UIKit和Core Animation基础的session在早年的WWDC中比较多),字幕在 transcripts ,当然也可以下载 WWDC 在桌面上看带有字幕的视频。这篇挺实用的,讲解了渲染的基本流程,以及怎么发现并解决渲染性能的问题。
一、iOS渲染架构总览
1.1 简易架构图
iOS APP 图形图像渲染的基本流程:
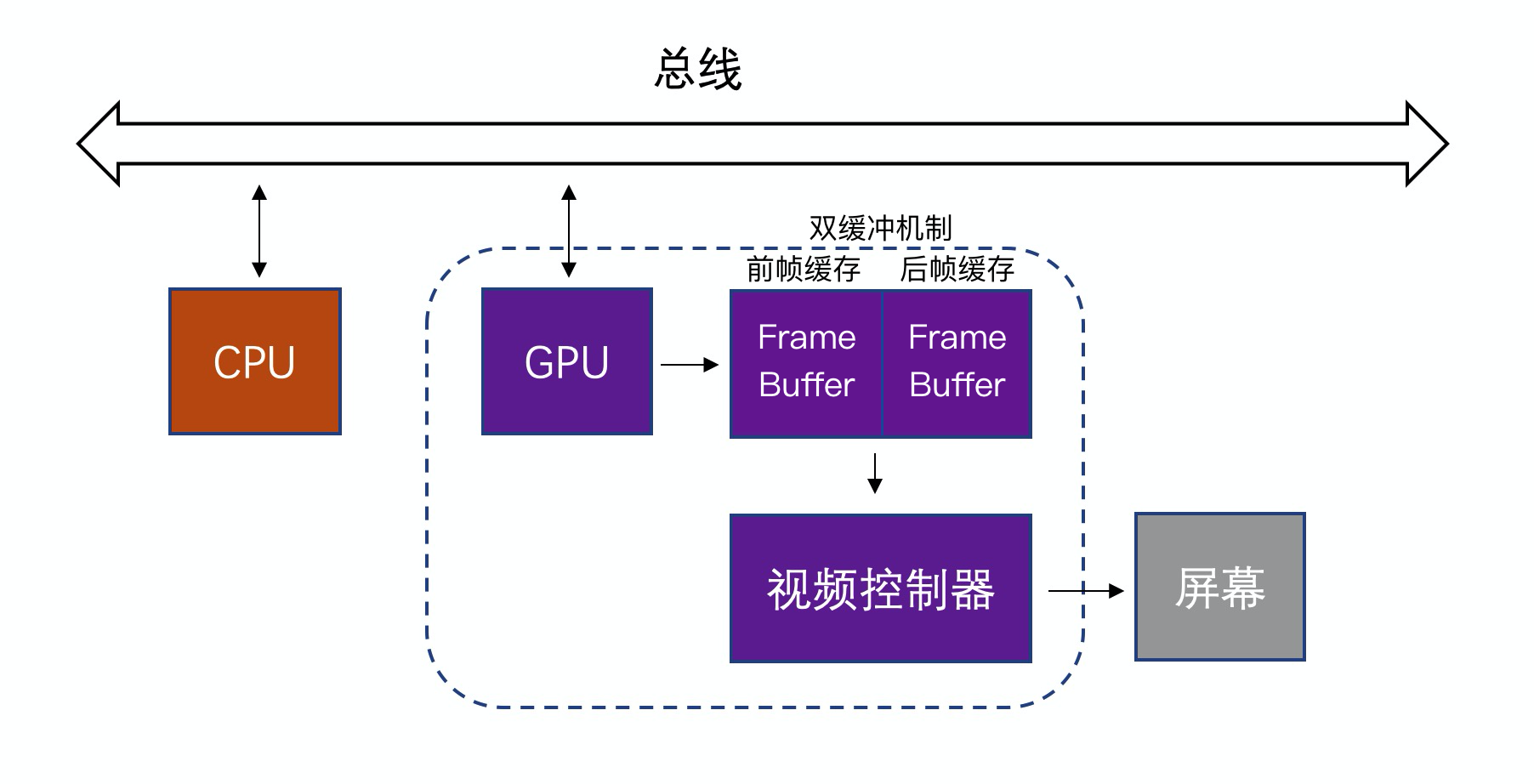
CPU(Central Processing Unit,中央处理器):完成对象的创建和销毁、对象属性的调整、布局计算、文本的计算和排版、图片的格式转换和解码、图像的绘制(Core Graphics)。
GPU(Graphics Processing Unit,图形处理器):GPU拿到CPU计算好的显示内容,完成纹理的渲染, 渲染完成后将渲染结果放入帧缓冲区。
帧缓冲区(Frame Buffer)(双缓冲机制,不再赘述)
正常情况下,在当前屏幕显示的内容,由 GPU 渲染完成后放到当前屏幕的帧缓存区,不需要额外的渲染空间。我们知道 iPhone 的屏幕刷新率是 60Hz,也就是刷新一帧的时间是 16.67 ms, 每隔这段时间视频控制器就会去读一次缓存区的内容来显示。
假如 GPU 遇到性能瓶颈,导致无法在一帧内更新渲染结果到帧缓存区,那么从缓存区读到的会是上一帧的内容,导致帧率降低界面卡顿。
视频控制器读取 Frame Buffer 中的数据 (视频控制器一般由显卡驱动程序或DirectX(微软公司创建的一系列专为多媒体以及游戏开发的应用程序接口)中自带,是芯片与显示平台的数据接口)
视频控制器会按照 VSync信号(开始新的帧缓冲的读取)、HSync信号(开始帧缓冲新的一行的读取)读取前帧缓冲区的数据,经过可能的数模转换传递给显示器显示。
GPU开始会绘制后缓存里的画面,然后视频控制器读取完前缓存的画面, 就会去读取后缓存里的画面。
然后GPU再去绘制前缓存里的画面,即两者交替进行。
将上图更细化一点:
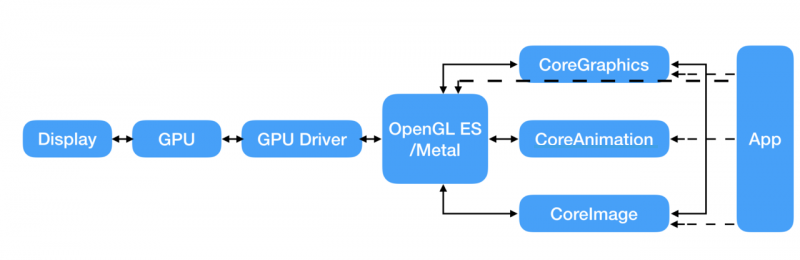
(原文)关于绘图和动画有两种处理的方式:CPU(中央处理器)和GPU(图形处理器)。在现代iOS设备中,都有可以运行不同软件的可编程芯片,但是由于历史原因,我们可以说CPU所做的工作都在软件层面,而GPU在硬件层面。
总的来说,我们可以用软件(使用CPU)做任何事情,但是对于图像处理,通常用硬件会更快,因为GPU使用图像对高度并行浮点运算做了优化。由于某些原因,我们想尽可能把屏幕渲染的工作交给硬件去处理。问题在于GPU并没有无限制处理性能,而且一旦资源用完的话,性能就会开始下降了(即使CPU并没有完全占用)
大多数动画性能优化都是关于智能利用GPU和CPU,使得它们都不会超出负荷。于是我们首先需要知道Core Animation是如何在这两个处理器之间分配工作的。
1.2 CoreAnimation渲染架构图
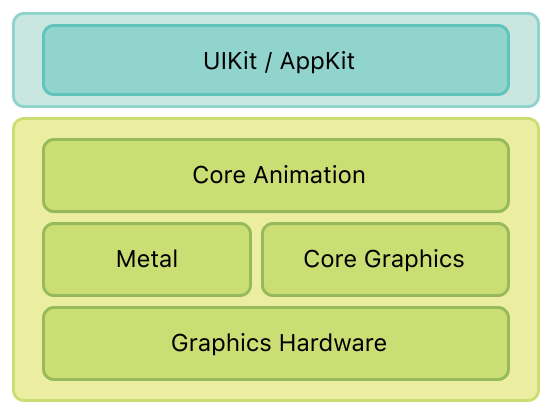
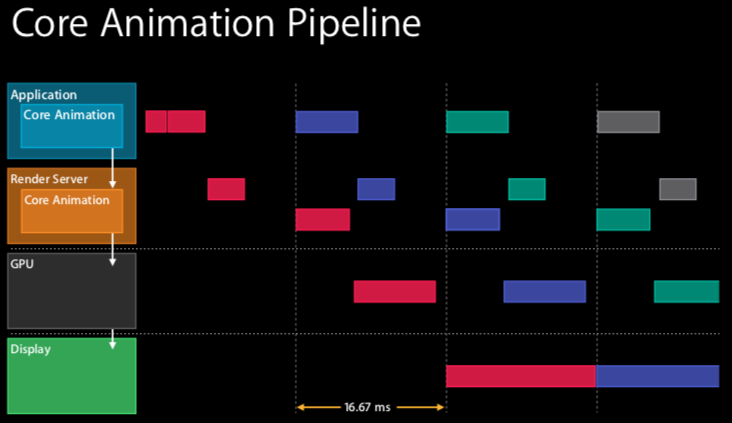
我们知道 Core Animation 是 iOS 上可用的图形渲染和动画基础结构,它将大部分实际绘图工作交给图形硬件以加速渲染(摘自官方文档Core Animation Programming Guide)。 我们先来看看 Core Animation 渲染的管道图:
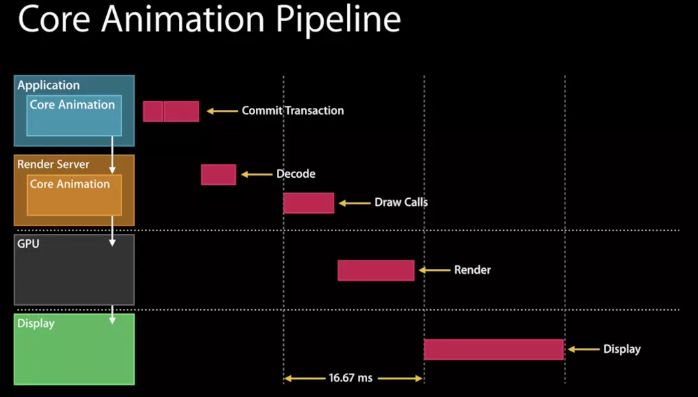
我们看到:
- 在应用程序(Application)和渲染服务器(Render Server)中都有 Core Animation 。我们也可以把iOS下的Core Animation可以理解为一个复合引擎,主要职责包含:渲染、构建和实现动画。
- 可以看到,渲染工作并不是在应用程序里(尽管它有 Core Animation)完成的,这一层主要是CPU在操作。它只是将视图层级(view hierarchy)打包(encode)提交给渲染服务器(一个单独的进程,也有 Core Animation), 视图层级才会被渲染。(“The view hierarchy is then rendered with Core Animation with OpenGL or metal, that’s the GPU.”)
- CPU和GPU双方同处于一个流水线中,协作完成整个渲染工作。
大致流程如下:
- Handle Events:它代表 touch, 即一切要更新视图层级的事情;
- Commit Transaction:编码打包视图层级,发送给渲染服务器;
- Decode:渲染服务器第一件事就是解码这些视图层级;
- Draw Calls:渲染服务器必须等待下一次重新同步,以便等待缓冲区从 它们实现渲染的显示器 返回,然后最终开始为 GPU 绘制,这里就是 OpenGL or metal 。(以前是call OpenGL ES,现在慢慢转到了Metal)。
- Render:一旦视图资源可用, GPU 就开始它的渲染工作,希望在下个重新同步完成,因为要交换缓冲区给用户。
- Display:显示给用户看。
在上述情况下,这些不同的步骤总共跨越三帧。在最后一个步骤 display 后,是可以平行操作的,在 Draw call 的时候可以处理下一个 handler event 和 Commit Transaction 。如下图所示
二、渲染步骤详解
2.1 APP — Commit Transaction
2.1.1 事务提交的4个阶段
先聚焦 Commit transaction(事务是什么就不再赘述了)这个阶段,因为这是开发者接触最多的,主要有四个阶段,如下图所示:

1. 布局(Layout)
Set up the views. 这是准备你的视图/图层的层级关系,以及设置图层属性(位置,背景色,边框等等)的阶段
- 重载的
layoutSubviews方法会在这个阶段被调用; - 视图的创建,被添加到视图层级上;
- 计算内容,比如:字符串,用来布局 label ;
- 这个阶段通常是 CPU 或者 I/O 限制,所以做的事情要轻量
2. 显示(Display)
Draw the views. 这是图层的寄宿图片被绘制的阶段。绘制有可能涉及你的-drawRect:和-drawLayer:inContext:方法的调用路径。
- 主要是 core graphics 用来绘制,调用重载的
drawRect:方法来绘制,绘制字符串;这个阶段通常是 CPU 或者内存限制,所以减少 core graphics 的工作
3. 准备(Prepare)
Additional Core Animation work. 这是Core Animation准备发送动画数据到渲染服务的阶段。这同时也是Core Animation将要执行一些别的事务例如解码动画过程中将要显示的图片的时间点。
- 主要是图片解码和图片转换。所以,图片大小和格式都是被 GPU 支持的,不然转换是发生在 CPU 上的,最好是 index bitmap ,可以免去转换
4. 提交(Commit)
Package up the layers and send them to the render server. 这是最后的阶段,Core Animation打包所有图层和动画属性,然后通过IPC(内部处理通信)发送到渲染服务进行显示。
- 视图层级不要太复杂,尽量扁平,因为这里的打包是循环处理的
以上这些仅仅阶段仅仅发生在你的应用程序之内,在动画在屏幕上显示之前仍然有更多的工作。
2.1.2 Animation的渲染
动画分为三个阶段,前面两个阶段在应用程序,最后一个在渲染服务器,如下图所示

跟视图的不同的是,这里提交的不是视图层级,而是动画。这是出于效率的原因,方便我们可以继续更新动画,因为如果提交视图层级的话,动画一更新,又得返回到应用程序提交新的视图层级,很耗时。
2.2 Render Server
2.2.1 渲染服务
Core Animation处在iOS的核心地位:应用内和应用间都会用到它。一个简单的动画可能同步显示多个app的内容,例如当在iPad上多个程序之间使用手势切换,会使得多个程序同时显示在屏幕上。在一个特定的应用中用代码实现它是没有意义的,因为在iOS中不可能实现这种效果(App都是被沙箱管理,不能访问别的视图)。
动画和屏幕上组合的图层实际上被一个单独的进程管理,而不是你的应用程序。这个进程就是所谓的渲染服务(Render Server)。在iOS5和之前的版本是 SpringBoard 进程(同时管理着iOS的主屏)。在iOS6之后的版本中叫做BackBoard。
一旦 commit Transition 打包的图层和动画到达渲染服务进程,他们会被反序列化来形成另一个叫做渲染树的图层树(在第一章“图层树”中提到过)。使用这个树状结构,渲染服务对动画的每一帧做出如下工作:
- 对所有的图层属性计算中间值,设置OpenGL几何形状(纹理化的三角形)来执行渲染
- 在屏幕上渲染可见的三角形
加上前面事务提交时的布局、显示、准备、提交,一共有六个阶段(在动画过程中,最后两个阶段不停地重复)。前五个阶段都在软件层面处理(通过CPU),只有最后一个被GPU执行。而且,你真正只能控制前两个阶段:布局和显示。Core Animation框架在内部处理剩下的事务,你也控制不了它。
这并不是个问题,因为在布局和显示阶段,你可以决定哪些由CPU执行,哪些交给GPU去做。那么该如何判断呢?
2.2.2 GPU相关的操作
GPU为一个具体的任务做了优化:它用来采集图片和形状(三角形),运行变换,应用纹理和混合然后把它们输送到屏幕上。现代iOS设备上可编程的GPU在这些操作的执行上又很大的灵活性,但是Core Animation并没有暴露出直接的接口。除非你想绕开Core Animation并编写你自己的OpenGL着色器,从根本上解决硬件加速的问题,那么剩下的所有都还是需要在CPU的软件层面上完成。
宽泛的说,大多数CALayer的属性都是用GPU来绘制。比如如果你设置图层背景或者边框的颜色,那么这些可以通过着色的三角板实时绘制出来。如果对一个contents属性设置一张图片,然后裁剪它 - 它就会被纹理的三角形绘制出来,而不需要软件层面做任何绘制。
但是有一些事情会降低(基于GPU)图层绘制效率,比如:
- 太多的几何结构:这发生在需要太多的三角板来做变换,以应对处理器的栅格化的时候。
- 现代iOS设备的图形芯片可以处理几百万个三角板,所以在Core Animation中几何结构并不是GPU的瓶颈所在。
- 但由于图层在显示之前通过IPC发送到渲染服务器的时候(图层实际上是由很多小物体组成的特别重量级的对象),太多的图层就会引起CPU的瓶颈。这就限制了一次展示的图层个数(见后续“CPU相关操作”)。
- 重绘:主要由重叠的半透明图层引起。
- GPU的填充比率(用颜色填充像素的比率)是有限的,所以需要避免重绘(每一帧用相同的像素填充多次)的发生。
- 在现代iOS设备上,GPU都会应对重绘;即使是iPhone 3GS都可以处理高达2.5的重绘比率,并仍然保持60帧率的渲染(这意味着你可以绘制一个半的整屏的冗余信息,而不影响性能),并且新设备可以处理更多。
- 离屏绘制:这发生在当不能直接在屏幕上绘制,并且必须绘制到离屏图片的上下文中的时候。
- 离屏绘制发生在基于CPU或者是GPU的渲染,或者是为离屏图片分配额外内存,以及切换绘制上下文,这些都会降低GPU性能。
- 对于特定图层效果的使用,比如圆角,图层遮罩,阴影或者是图层光栅化都会强制Core Animation提前渲染图层的离屏绘制。但这不意味着你需要避免使用这些效果,只是要明白这会带来性能的负面影响。
- 过大的图片:如果视图绘制超出GPU支持的2048x2048或者4096x4096尺寸的纹理,就必须要用CPU在图层每次显示之前对图片预处理,同样也会降低性能。
2.2.3 CPU相关的操作
大多数工作在Core Animation的CPU都发生在动画开始之前。这意味着它不会影响到帧率,所以很好,但是他会延迟动画开始的时间,让你的界面看起来会比较迟钝。
以下CPU的操作都会延迟动画的开始时间:
- 布局计算:如果你的视图层级过于复杂,当视图呈现或者修改的时候,计算图层帧率就会消耗一部分时间。特别是使用iOS6的自动布局机制尤为明显,它应该是比老版的自动调整逻辑加强了CPU的工作。
- 视图惰性加载:iOS只会当视图控制器的视图显示到屏幕上时才会加载它。这对内存使用和程序启动时间很有好处,但是当呈现到屏幕上之前,按下按钮导致的许多工作都会不能被及时响应。比如控制器从数据库中获取数据,或者视图从一个nib文件中加载,或者涉及IO的图片显示(见后续“IO相关操作”),都会比CPU正常操作慢得多。
- Core Graphics绘制:如果对视图实现了
-drawRect:方法,或者CALayerDelegate的-drawLayer:inContext:方法,那么在绘制任何东西之前都会产生一个巨大的性能开销。为了支持对图层内容的任意绘制,Core Animation必须创建一个内存中等大小的寄宿图片。然后一旦绘制结束之后,必须把图片数据通过IPC传到渲染服务器。在此基础上,Core Graphics绘制就会变得十分缓慢,所以在一个对性能十分挑剔的场景下这样做十分不好。 - 解压图片PNG或者JPEG压缩之后的图片文件会比同质量的位图小得多。但是在图片绘制到屏幕上之前,必须把它扩展成完整的未解压的尺寸(通常等同于图片宽 x 长 x 4个字节)。为了节省内存,iOS通常直到真正绘制的时候才去解码图片。根据你加载图片的方式,第一次对图层内容赋值的时候(直接或者间接使用
UIImageView)或者把它绘制到Core Graphics中,都需要对它解压,这样的话,对于一个较大的图片,都会占用一定的时间。
当图层被成功打包,发送到渲染服务器之后,CPU仍然要做如下工作:为了显示屏幕上的图层,Core Animation必须对渲染树中的每个可见图层通过OpenGL循环转换成纹理三角板。由于GPU并不知晓Core Animation图层的任何结构,所以必须要由CPU做这些事情。这里CPU涉及的工作和图层个数成正比,所以如果在你的层级关系中有太多的图层,就会导致CPU每一帧的渲染,即使这些事情不是你的应用程序可控的。
2.2.4 IO相关操作
还有一项没涉及的就是IO相关工作。上下文中的IO(输入/输出)指的是例如闪存或者网络接口的硬件访问。一些动画可能需要从闪存(甚至是远程URL)来加载。一个典型的例子就是两个视图控制器之间的过渡效果,这就需要从一个nib文件或者是它的内容中懒加载,或者一个旋转的图片,可能在内存中尺寸太大,需要动态滚动来加载。
IO比内存访问更慢,所以如果动画涉及到IO,就是一个大问题。总的来说,这就需要使用聪敏但尴尬的技术,也就是多线程,缓存和投机加载(提前加载当前不需要的资源,但是之后可能需要用到)。
2.3 OpenGL ES
2.3.1 OpenGL是什么?
从上面的渲染架构图可以看到,OpenGL位于硬件驱动层和软件层之间,
OpenGL(Open Graphics Library,译名:开放图形库或者“开放式图形库”)是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API)。这个接口由近350个不同的函数调用组成,用来从简单的图形比特绘制复杂的三维景象。而另一种程序接口系统是仅用于Microsoft Windows上的Direct3D。OpenGL常用于CAD、虚拟现实、科学可视化程序和电子游戏开发。
OpenGL 是一套图形图像开发规范,OpenGL架构评审委员会(ARB)维护。其实现一般由显示设备(GPU/显卡)厂商提供,而且非常依赖于该厂商提供的硬件。OpenGL的高效实现(利用图形加速硬件)存在于Windows,部分UNIX平台和Mac OS。
- OpenGL规范描述了绘制2D和3D图形的抽象API。尽管这些API可以完全通过软件实现,但它是为大部分或者全部使用硬件加速而设计的。
- OpenGL不仅语言无关,而且平台无关。
- OpenGL是一个不断进化的API。每个版本的细节由开发组织(Khronos Group)的成员一致决定,包括显卡厂商、操作系统设计人员以及类似Mozilla和谷歌的一般性科技公司。
- 除了核心API要求的功能之外,GPU供应商可以通过扩展的形式提供额外功能。扩展可能会引入新功能和新常量,并且可能放松或取消现有的OpenGL函数的限制。然后一个扩展就分成两部分发布:包含扩展函数原型的头文件和作为厂商的设备驱动。
OpenGL ES(OpenGL for Embedded Systems)是三维图形应用程序接口OpenGL的子集,针对手机、PDA和游戏主机等嵌入式设备而设计。
2.3.2 OpenGL用来干嘛?
从操作粒度来理解它,它是基于GPU硬件驱动层的API,它直接操作的对象是显示屏幕上的每个像素点(Pixel)。我们可以利用这套API来操作屏幕上的每一个像素点的排列组合,颜色,深度等等来实现各种各样的图形图像。
总而言之,它是用来操作GPU显示图形图像的API。
2.3.3 OpenGL — 状态机
OpenGL自身是一个巨大的状态机(State Machine):一系列的变量描述OpenGL此刻应当如何运行。OpenGL的状态通常被称为OpenGL上下文(Context)。我们通常使用如下途径去更改OpenGL状态:设置选项,操作缓冲。最后,我们使用当前OpenGL上下文(Contex)来渲染。
OpenGL会保持状态,除非我们调用OpenGL函数来改变它。就像一个时间点的快照一样,除非对这个OpenGL的上下文进行修改,否则它呈现的内容是不会改变的。
每个OpenGL的上下文都是独立,我们在不同上下文做的工作是互不影响的,在实际操作过程中要注意是否在同一个上下文中。
2.4 GPU — 基于图块的渲染
先来了解渲染的一些概念(Rendering Concepts)。
tile 图块,瓦片; tiling 铺瓦于,铺以瓷砖
“first tile based rendering is how all GPUs work.” 基于图块的渲染(Tile Based Rendering)是所有 GPU 的工作方式。

- 屏幕被分割成 N*N 个像素块,就像之前讲 Points vs Pixels 中的例子一样;
- 每块都适应 Soc 缓存。(Soc: 苹果 A9 是一款由苹果公司设计的系统芯片(Soc)。可以理解为系统芯片。 维基百科上面写的,这个芯片是 2015.9.9 才首次发布)。
- 几何体被分割成图块桶(tile buckets),这一步发生在 tiler stage (后面有提到)。这里举了 iPhone icon 的例子,从上图中可以看到,这个 icon 被分割成多个很小的三角形,使得这些三角形块可以单独的渲染,分割这样做的思路可以决定哪一块显示,哪一块渲染。 因为每个像素只有一个像素着色器,所以混合的话还是有问题的,涉及到覆盖绘制。
- 几何体提交后,光栅化才开始。(所以光栅化能提升性能,因为几何体都提交了,下次渲染的时候就可以省略这一步。)
2.4.1 Rendering pass
Pass: v. 通过; 传递; 变化; 放弃 n. 经过; 通行证; 通道; 流程; 阶段。此处应是译作阶段
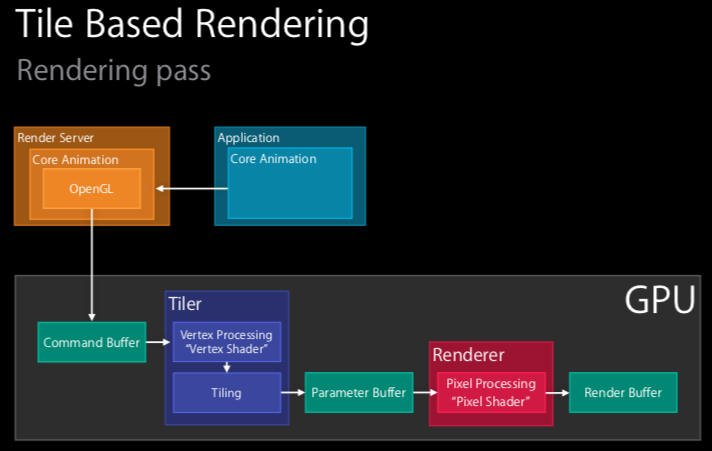
如上图所示,我们假设视图层级已经被提交到渲染服务器,并且 Core Animation 已经解码它,现在需要用 OpenGL 或者 metal 去渲染了,文章讲师举例是用的 OpenGL (所以这里的 Slide 比前面讲 Core Animation Pipeline 的 Slide 在 Render Server 这一栏,多了 OpenGL 在里面)。具体流程如下:
- GPU 收到 Command Buffer ;
- 顶点着色器(Vertex Shader)开始运行,思路就是先将所有的顶点转换到屏幕空间,然后平铺处理,平铺成瓷砖桶(tile bucket)的几何图形。
- 这里分两步走,先顶点处理然后平铺,统称为 Tiler stage,在 Instrument 的 OpenGL ES tiler utilization 能看到这一步。
- 这一步的产出被写入 Parameter Buffer,下一阶段不会马上启动。相反,会等待,直到
- a. 处理完所有的几何体,并且都位于 Parameter Buffer 中;或者
- b. Parameter buffer 已满(满了的话,必须刷新它)。
- 像素着色器(Pixel Shader)处理,这一步被称为 Renderer stage,产出被写入 Render Buffer 。(在 Instrument 的 OpenGL ES renderer utilization 能看到这一步。)
2.4.2 示例:渲染遮罩
举了一个渲染遮罩的例子,步骤如下图:
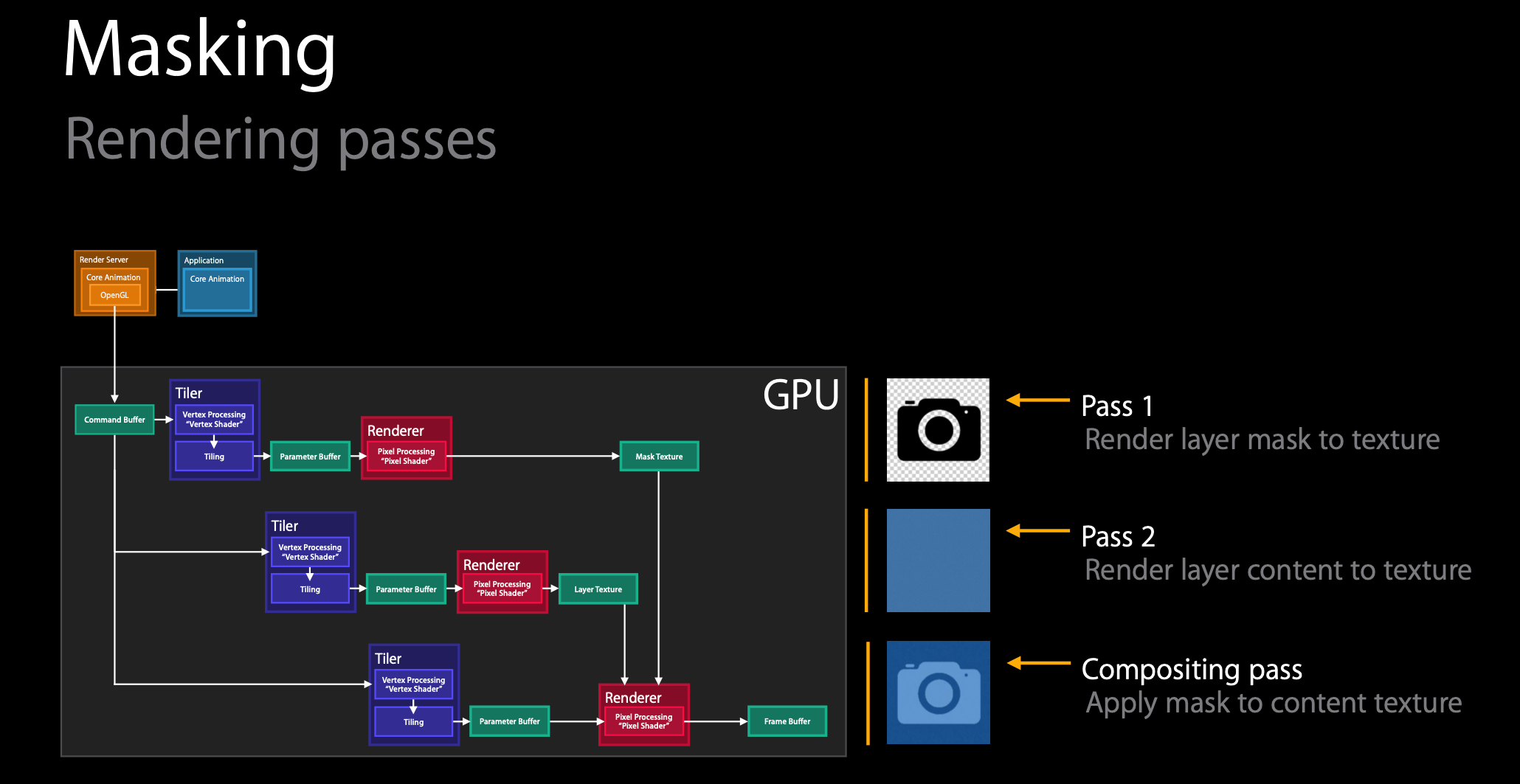
分三步走,两步渲染,一步合成。
- 将遮罩层(相机 icon)渲染到纹理(texture)上;
- 将内容层渲染到纹理上;
- 将遮罩添加到内容纹理上。
三、图形相关概念补充
3.1 显卡与GPU
显卡是个人电脑最基本组成部分之一,用途是将计算机系统所需要的显示信息进行转换驱动电脑,并提供逐行或隔行扫描信号,控制电脑的正确显示,是连接显示器和个人电脑主板的重要 组件 ,是“人机对话”的重要设备之一。
- 显卡是插在主板上的扩展槽里的(现在一般是PCI-E插槽,此前还有AGP、PCI、ISA等插槽)。它主要负责把主机向显示器发出的显示信号转化为一般电器信号,使得显示器能明白个人电脑 在让它做什么。
- 显卡的主要芯片叫“显示芯片”(Video chipset,也叫GPU或VPU,图形处理器或视觉处理器),是显卡的主要处理单元。
- 显卡上也有和电脑存储器相似的存储器,称为 “显示存储器”,简称显存。
- 早期的显卡只是单纯意义的显卡,只起到信号转换的作用;目前的显卡一般都带有3D画面运算和图形加速功能 ,所以也叫做“图形加速卡”或“3D加速卡”。
显卡通常由总线接口、PCB板、显示芯片、显示存储器、RAMDAC、VGA BIOS、VGA端子及其他外围组件构成,现在的显卡大多使用VGA、DVI、HDMI接口或DisplayPort接口。
3.2 驱动
设备驱动程序(device driver,简称驱动程序driver),是一个允许高端电脑软件与硬件交互的程序,这种程序创建了一个硬件与硬件,或硬件与软件沟通的接口,经由主板上的总线(bus)或其它沟通子系统(subsystem)与硬件形成连接的机制,这样的机制使得硬件设备上的资料交换成为可能。
3.3 硬件加速
硬件加速是指在计算机中通过把计算量非常大的工作分配给专门的硬件来处理以减轻中央处理器的工作量之技术。尤其是在图像处理中这个技术经常被使用。
例如,雷神之锤3是第一个必须要求硬件加速的3D游戏。Google Chrome浏览器也设置了“硬件加速”功能,用户可根据需求开启或关闭此功能。
3.4 图元
任何一个图形表达都是由若干不同的点、线、面图案或相同的图案循环组合而成的。这些点、线、面图案即为基本图形元素。
不同的图形系统有不同的图形元素:
- GKS标准规定了6种基本图形元素,即折线、多点记号、填充区、正文、像素阵列和GDP(广义绘图元素)。
- CGM标准除6种基本图形元素外,附加了圆弧、椭圆弧、样条曲线等等图形元素
基本图形元素所具有的特征有:颜色、亮度、线型、线宽、字符大小、字符间距、字体、图元检索名以及用户定义的其他特征等
3.5 纹理
3.5.1 纹理
计算机图形学中的纹理既包括通常意义上物体表面的纹理即使物体表面呈现凹凸不平的沟纹,同时也包括在物体的光滑表面上的彩色图案,通常我们更多地称之为花纹。
- 对于花纹而言,就是在物体表面绘出彩色花纹或图案,产生了纹理后的物体表面依然光滑如故。
- 对于沟纹而言,实际上也是要在表面绘出彩色花纹或图案,同时要求视觉上给人以凹凸不平感即可。凹凸不平的图案一般是不规则的。
在计算机图形学中,这两种类型的纹理的生成方法完全一致,这也是计算机图形学中把他们统称为纹理的原因所在。
3.5.2 纹理映射
纹理映射就是在物体的表面上绘制图案。
- Direct3D中的纹理:表示物体表面细节的一幅或几幅二维图形,也称纹理贴图(texture mapping)当把纹理按照特定的方式映射到物体表面上的时候能使物体看上去更加真实。
- Photoshop中的纹理:Photoshop使用“纹理”滤镜赋予图像一种深度或物质的外观,或添加一种有机外观。如龟裂缝、颗粒、马赛克拼贴、拼缀图、染色玻璃、纹理化等。
- Word中也有设置纹理填充。
3.5.3 材质、贴图、纹理
整个 CG 领域中这三个概念都是差不多的,在一般的实践中,大致上的层级关系是:
材质 Material 包含 贴图 Map,Map 包含 纹理 Texture。
日常口语勘误:有人习惯用贴图(Map)指代纹理(Texture)。导致有些场景下贴图就是贴图,有些场景下贴图是在指纹理。这个需要个人区分清楚
- 纹理是最基本的数据输入单位,游戏领域基本上都用的是位图。此外还有程序化生成的纹理 Procedural Texture。
- 贴图的英语 Map 其实包含了另一层含义就是“映射”。其功能就是把纹理通过 UV 坐标映射到3D 物体表面。贴图包含了除了纹理以外其他很多信息,比方说 UV 坐标、贴图输入输出控制等等。
- 材质是一个数据集,主要功能就是给渲染器提供数据和光照算法。
- 贴图就是其中数据的一部分,根据用途不同,贴图也会被分成不同的类型,比方说 Diffuse Map,Specular Map,Normal Map 和 Gloss Map 等等。
- 另外一个重要部分就是光照模型 Shader ,用以实现不同的渲染效果。
- 光照与物体表面的相互作用可以通过将一些数学公式应用于基于per pixel(区别于基于顶点)的着色,从而模拟出真实生活中的各种材质效果。比如浮雕效果,波浪效果,油漆效果等。
3.6 着色器
3.6.1 概述
计算机图形学领域中,着色器(shader)是一种计算机程序,原本用于进行图像的浓淡处理(计算图像中的光照、亮度、颜色等),但近来,它也被用于完成很多不同领域的工作,比如处理CG特效、进行与浓淡处理无关的视频后期处理、甚至用于一些与计算机图形学无关的其它领域。更多介绍见WIKI。
功能:构成最终图像的像素、顶点、纹理,它们的位置、色相、饱和度、亮度、对比度也都可以利用着色器中定义的算法进行动态调整。调用着色器的外部程序,也可以利用它向着色器提供的外部变量、纹理来修改这些着色器中的参数。
常用的着色器有以下三种:
- 二维着色器
- 像素着色器
- 三维着色器
3.6.2 二维着色器
二维着色器处理的是数字图像,也叫纹理,着色器可以修改它们的像素。二维着色器也可以参与三维图形的渲染。目前只有“像素着色器”一种二维着色器。
像素着色器
像素着色器(pixel shader,也叫片段着色器fragment shader),用于计算“片段”的颜色和其它属性,此处的“片段”通常是指单独的像素。
- 最简单的像素着色器只有输出颜色值;复杂的像素着色器可以有多个输入输出。
- 像素着色器既可以永远输出同一个颜色,也可以考虑光照、做凹凸贴图、生成阴影和高光,还可以实现半透明等效果。
- 像素着色器还可以修改片段的深度,也可以为多个渲染目标输出多个颜色。
三维图形学中,单独一个像素着色器并不能实现非常复杂的效果,因为它只能处理单独的像素,没有场景中其它几何体的信息。不过,像素着色器有屏幕坐标信息,如果将屏幕上的内容作为纹理传入,它就可以对当前像素附近的像素进行采样。利用这种方法,可以实现大量二维后期特效,例如模糊和边缘检测。
像素着色器还可以处理管线中间过程中的任何二维图像,包括精灵和纹理。因此,如果需要在栅格化后进行后期处理,像素着色器是唯一选择。
3.6.3 三维着色器
三维着色器处理的是三维模型或者其它几何体,可以访问用来绘制模型的颜色和纹理。
- 顶点着色器是最早的三维着色器;
- 几何着色器可以在着色器中生成新的顶点;
- 细分曲面着色器(tessellation shader)则可以向一组顶点中添加细节。
顶点着色器处理每个顶点,将顶点的空间位置投影在屏幕上,即计算顶点的二维坐标。同时,它也负责顶点的深度缓冲(Z-Buffer)的计算。顶点着色器可以掌控顶点的位置、颜色和纹理坐标等属性,但无法生成新的顶点。
顶点着色器的输出传递到流水线的下一步。如果有之后定义了几何着色器,则几何着色器会处理顶点着色器的输出数据,否则,光栅化器继续流水线任务。
几何着色器可以从多边形网格中增删顶点。它能够执行对CPU来说过于繁重的生成几何结构和增加模型细节的工作。几何着色器的输出连接光栅化器的输入。
3.6.4 简化图形流水线
这些类型的着色器终究会用在GPU的流水线中,简述它们是如何被安排在流水线中的,简化图形管线/流水线(pipeline):
- 中央处理器(CPU)发送指令(编译的着色器程序)和几何数据到位于显卡内的图形处理器(GPU)。
- 顶点着色器执行几何变换和光照计算。
- 若几何着色器位于图形处理器内,它便会修改一些几何信息。
- 计算后的几何模型被三角化(分割为三角形)。
- 三角形被映射为2×2的像素块。
四、OpenGL Pipeline
图形渲染管线图
Contex为我们提供OpenGL的运行环境,而具体的操作则是在OpenGL的渲染管线中进行的。
在OpenGL中,任何事物都在3D空间中,而屏幕和窗口却是2D像素数组,这导致OpenGL的大部分工作都是关于把3D坐标转变为适应你屏幕的2D像素。3D坐标转为2D坐标的处理过程是由OpenGL的图形渲染管线(Graphics Pipeline)管理的。图形渲染管线可以被划分为两个主要部分:
- 第一部分把你的3D坐标转换为2D坐标,
- 第二部分是把2D坐标转变为实际的有颜色的像素。
Pipeline,大多译为管线,实际上指的是一堆原始图形数据途经一个输送管道,期间经过各种变化处理最终出现在屏幕的过程。
图形渲染管线接受一组3D坐标,然后把它们转变为你屏幕上的有色2D像素输出。图形渲染管线可以被划分为几个阶段:
- 每个阶段将会把前一个阶段的输出作为输入。
- 所有这些阶段都是高度专门化的(它们都有一个特定的函数),并且很容易并行执行。正是由于它们具有并行执行的特性,当今大多数显卡都有成千上万的小处理核心,它们在GPU上为每一个(渲染管线)阶段运行各自的小程序,从而在图形渲染管线中快速处理你的数据。这些小程序叫做着色器(Shader)。
- 着色器是一种非常独立的程序,因为它们之间不能相互通信;它们之间唯一的沟通只有通过输入和输出。
着色器(Shader)是运行在GPU上的小程序。这些小程序为完成图形渲染管线的某个特定部分的功能而运行。
有些着色器允许开发者自己配置,这就允许我们用自己写的着色器来替换默认的。这样我们就可以更细致地控制图形渲染管线中的特定部分了,而且因为它们运行在GPU上,所以它们可以给我们节约宝贵的CPU时间。OpenGL着色器是用OpenGL着色器语言(OpenGL Shading Language, GLSL)写成的。
下图一个图形渲染管线的每个阶段的抽象展示。要注意蓝色部分代表的是我们可以注入自定义的着色器的部分。
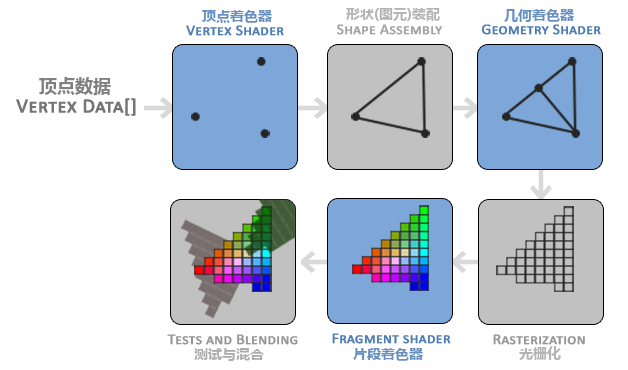
(几何着色器是可选的,通常使用它默认的着色器就行了)。
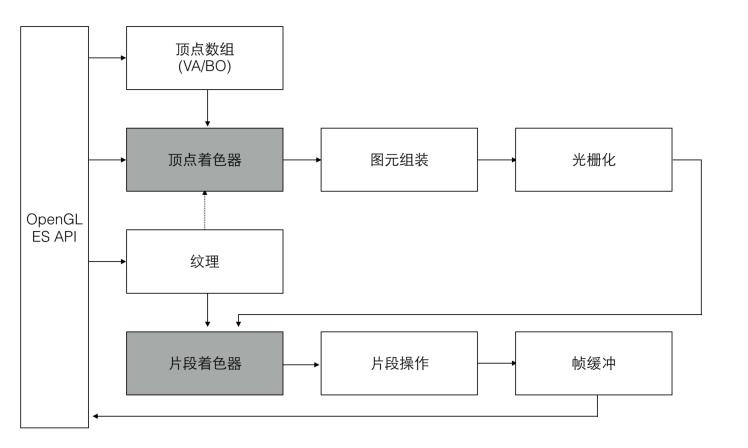
如图所见,图形渲染管线包含很多部分,每个部分都将在转换顶点数据到最终像素这一过程中处理各自特定的阶段。概括性地解释一下渲染管线的每个部分:
4.1 顶点数组
传递一个顶点数组作为图形渲染管线的输入。这个数组叫做顶点数据(Vertex Data)。一个顶点(Vertex)是一个3D坐标的数据的集合。(简单起见,可以假定每个顶点只由一个3D位置和一些颜色值组成)
4.2 顶点着色器(Vertex Shader)
它把一个单独的顶点作为输入。顶点着色器主要的目的是把3D坐标转为OpenGL的内部坐标信息,同时顶点着色器允许我们对顶点属性进行一些基本处理。
顶点着色器负责坐标和图形的描述。在OpenGL中有三种基本的图形点、线、三角形,只能通过这三种基本图形去描述一个图形。其中在OpenGL中我们的显示区域位于x,y均为[-1,1]之内的空间。
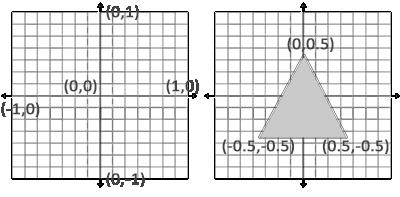
- 点:点存在于三维空间,坐标用(x,y,z)表示。
- 线:由两个三维空间中的点组成。
- 三角形:由三个三维空间的点组成。
输出:顶点。
4.3 图元装配阶段(Primitive Assembly)
将上阶段输出的 — 所有顶点作为输入,进行组装和裁剪,将所有的点装配成指定图元的形状,更准确的说是将所有3D的图元转化为屏幕上2D的图元。
输出:图元。(图元由顶点组成)
4.4 几何着色器(Geometry Shader)
将上阶段输出的 — 图元形式的一系列顶点的集合作为输入,它可以通过产生新顶点构造出新的(或是其它的)图元来生成其他形状。
(几何着色器是可选的,通常使用它默认的着色器就行了)
输出:新的图元。
到这一步我们已经为OpenGL描述了一个图形的样子,但是要转换为图像还需要颜色信息。↓
4.5 光栅化阶段(Rasterization Stage)
将上阶段输出的 — 图元映射为最终屏幕上相应的像素,生成供片段着色器使用的片段(Fragment),即实现通过插值运算将连续的值用一个个像素片段表示出来。
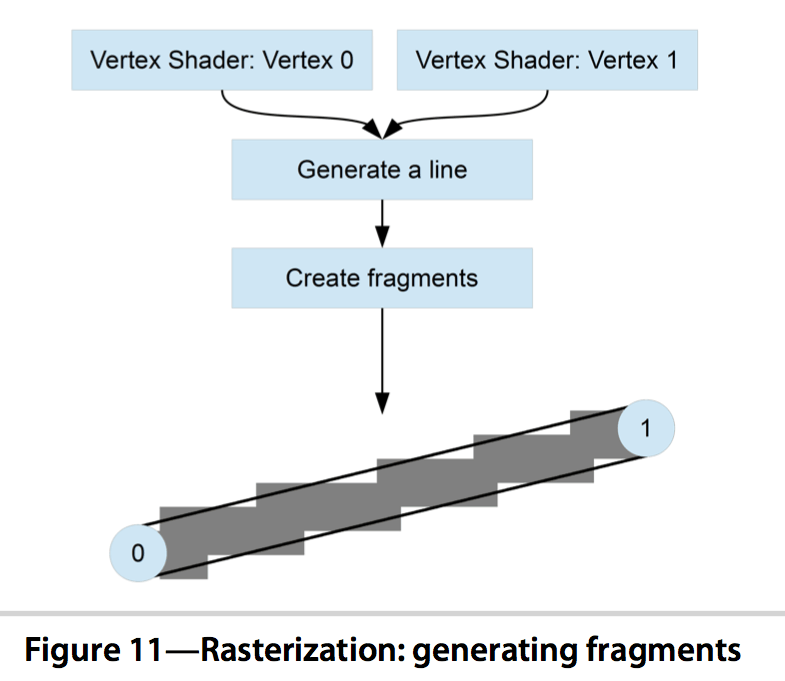
在片段着色器运行之前会执行裁切(Clipping)。裁切会丢弃超出你的视图以外的所有像素,用来提升执行效率。
输出:片元/片段(Fragment)
- 光栅化:将图转化为一个个栅格组成的图像,每个栅格此处又称为片元/片段(Fragment),OpenGL中的一个片段是OpenGL渲染一个像素所需的所有数据。
- 片元其实已经很接近像素了,但是它还不是像素。片元包含了比RGBA更多的信息,比如可能有深度值,法线,纹理坐标等等信息。
- 片元需要在通过一些测试(如深度测试)后才会最终成为像素。可能会有多个片元竞争同一个像素,而这些测试会最终筛选出一个合适的片元,丢弃法线和纹理坐标等不需要的信息后,成为像素。
4.6 片段着色器(Fragment Shader)
到了这一步我们已经有了一个个的像素片段(Fragament),我们在这个阶段给它涂上颜色值就可以变成一个完整的像素点。包括位置,颜色,纹理坐标等信息。
片段着色器的主要目的就是计算一个像素的最终颜色,这也是所有OpenGL高级效果产生的地方。
通常,片段着色器包含3D场景的数据(比如光照、阴影、光的颜色等等),这些数据可以被用来计算最终像素的颜色。
同时我们可以编写Fragament Shader的脚本来实现对每个像素颜色的变换来达到一些效果,如纹理贴图,光照,环境光,阴影。
输出:一个像素的最终颜色。像素 — 影像的最小的完整取样。最终呈现在屏幕上的包含RGBA值的图像最小单元就是像素了。
在所有对应颜色值确定以后,最终的对象将会被传到最后一个阶段。
4.7 Alpha测试和混合(Blending)阶段
主要是检测片段的对应的深度(和模板(Stencil))值,用它们来判断这个像素是其它物体的前面还是后面,决定是否应该丢弃。
这个阶段也会检查alpha值(alpha值定义了一个物体的透明度)并对物体进行混合(Blend)。所以,即使在片段着色器中计算出来了一个像素输出的颜色,在渲染多个三角形的时候最后的像素颜色也可能完全不同。
有的书中,称这个阶段也称片段测试阶段,对每个像素点进行测试保证这些像素点是正确可用的,最后在输入到帧缓冲(Frambuffer)中。
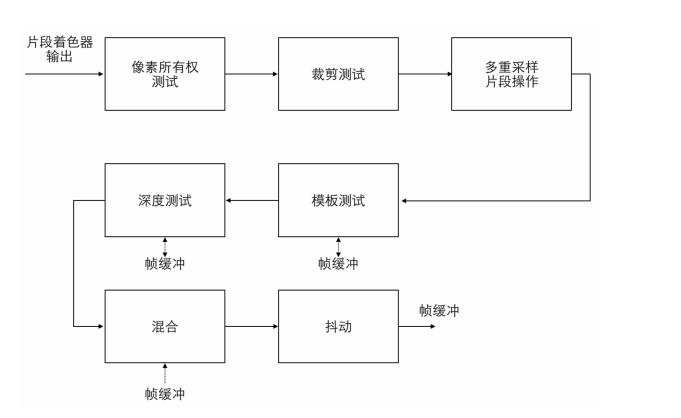
混合:当图像叠加时,上方图层和下方图层的像素进行混合,从而得到另外一种图像效果。
抖动(Dither)是在数字信号处理领域的中一项用于降低量化误差的技术。透过在较低比特中加入噪声,借此破坏谐波的排序,使谐波的影响受到压制,并减少量化误差在低频的影响。抖动常用于音视频处理,且是CD压制过程的最后一步。经过抖动处理过的音乐,将听起来更柔顺、背景更黑;而经过抖动处理过的影像,也会更加地柔顺耐看。
抖动最重要的用途之一是将灰阶图像转为黑白。透过使用抖动算法,可以令黑白图案的黑点密度接近原图案的大致灰度。
在数字图像处理中,经常使用抖动混合几种颜色,在颜色数量受限时产生出新的“颜色深度”。
4.8 渲染帧缓存(Renderbuffer)
4.8.1 帧缓存 (Framebuffer)
经过上述处理流程,我们想要看到的图形图像数据最后都会存储到帧缓存区(Framebuffer)中。我们可以同时存在很多帧缓存(Framebuffer),并且可以通过OpenGL让GPU把渲染结果存储到任意数量的帧缓存中(这里引申出一个离屏渲染的工作概念)。
但是,只有将内容绘制到视窗体提供的帧缓存(Renderbuffer)中,才能将内容输出到显示设备。在实现上渲染缓存(Renderbuffer)是直接跟屏幕映射的,可以绕开CPU进行工作。
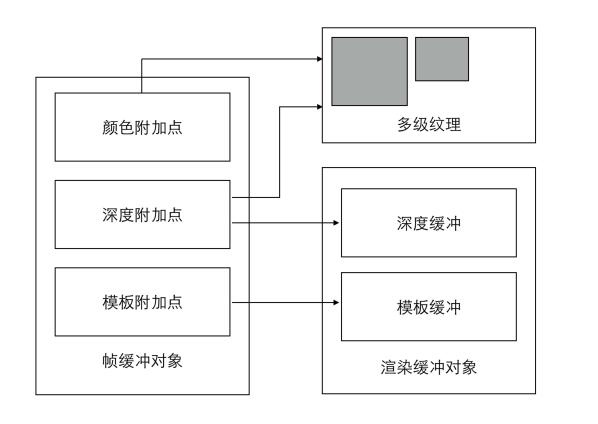
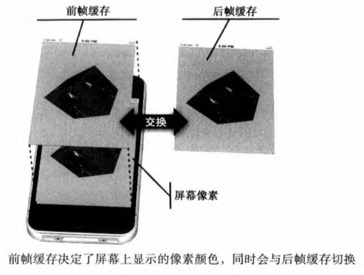
4.8.2 帧缓存的渲染
基本工作原理是存在两个缓存(前缓存和后缓存),当屏幕的刷新同步信号到达时让系统将后缓存交换到前缓存区上。
这个刷新的时间是由系统决定的,比如在iOS中屏幕刷新率是60fps即每16.75ms会发生一次前后缓存的交换。我们只需要准备好后缓存的数据提供给系统就能进行屏幕刷新渲染了。
4.9 小结
可以看到,图形渲染管线非常复杂,它包含很多可配置的部分。然而,对于大多数场合,我们只需要配置顶点和片段着色器就行了。几何着色器是可选的,通常使用它默认的着色器就行了。
在现代OpenGL中,我们必须定义至少一个顶点着色器和一个片段着色器(因为GPU中没有默认的顶点/片段着色器)。
以上就是OpenGL整体工作流程。首先OpenGL是用来操作GPU进行图形图像渲染工作的,它的操作粒度可以到每个像素点,同时它是直接操作GPU硬件工作的。而之后的工作核心(2D图形图像渲染)基本是集中在对顶点着色器和片段着色器的脚本实现上(酷炫的滤镜效果和动画效果)。
五、案例1 — UIBlurEffect的渲染过程
UIBlurEffect 是 iOS8 新出的用来实现模糊效果的类。
5.1 渲染步骤
它的渲染过程如下:
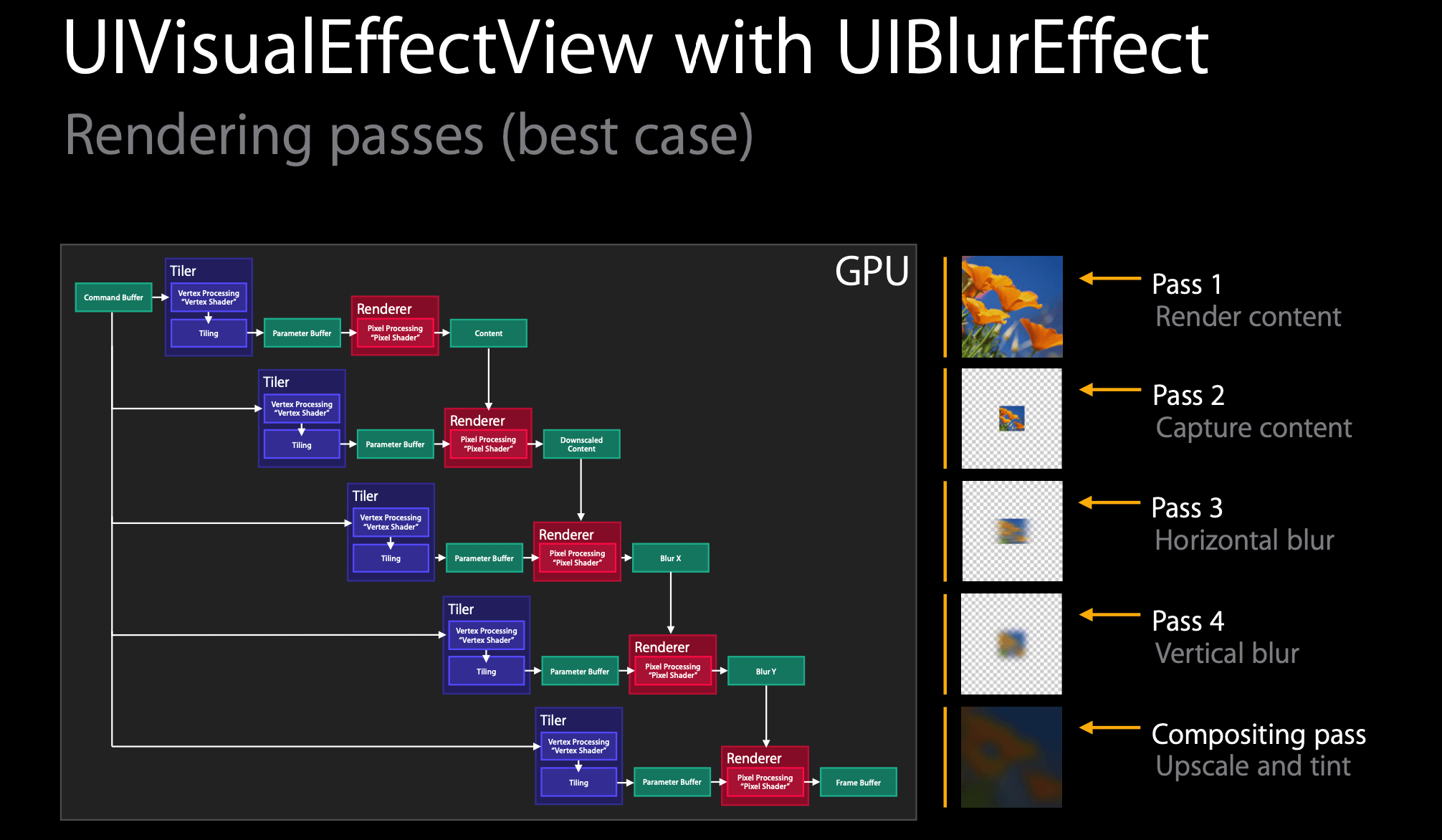
- 渲染 layer 的 content,在这种情况下,它只是一个简单的图像,因此如果我们涉及 UI ,可能需要更长的时间;
- 截获 layer 的 content,进行缩放,它实际上相当快。这几乎是不变的成本;
- 对缩放内容进行横向模糊,也非常快,因为是小区域。
- 对缩放内容进行纵向模糊,同上
- 合成操作,合并所有模糊结果。
5.2 每一步中的三事件
再看下图,聚焦在一帧。我们可以看到每个渲染步骤所需的时间,每个渲染步骤都牵扯到了下面要提到的三个事件(tile/render/VBlank interrupt)。
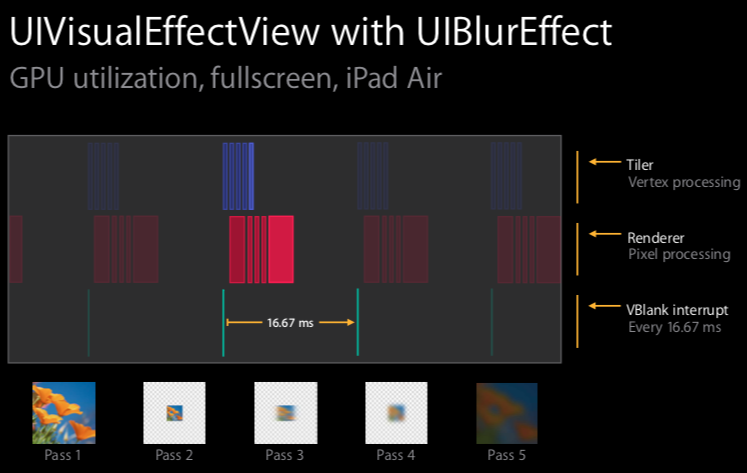
我们可以看到有三行,每一行代表一个事件
- tile activity
- render activity
- VBlank interrupt, “and the last row I put in the VBlank interrupt and we can actually see what our frame boundaries are.” (我们实际上可以看到我们的帧边界是什么)
5.3 步骤间隙
我们注意到下图,每个步骤之间的间隙,用橘色标记了

5 个步骤中间有 4 个间隙,之所以存在,是因为这是发生在 GPU 上切换所花的时间。在空闲时间,每个步骤所花费的时间大概在 0.1~~0.2ms, 所以总共 0.4~~0.8ms, 所以这个是 16.67ms 的一个重要组成部分。
还列举了不同设备间的耗时,有一种设备某个 Dark style 下的时间是 18.15ms, 超过 16.67ms, 所以不可能在 60 hert 渲染完成。所以 Apple 在这些设备上不支持 blur 。
UIBlurEffect 有三种 style: Extra light, Light, Dark ,它们消耗的资源各不相同, Dark 最少, Extra light 最多。
六、案例2 — UIVibrancyEffect的渲染过程
UIVibrancyEffect 是在模糊之上使用的效果,它可以确保内容突出,而不会被模糊。它的渲染过程如下:
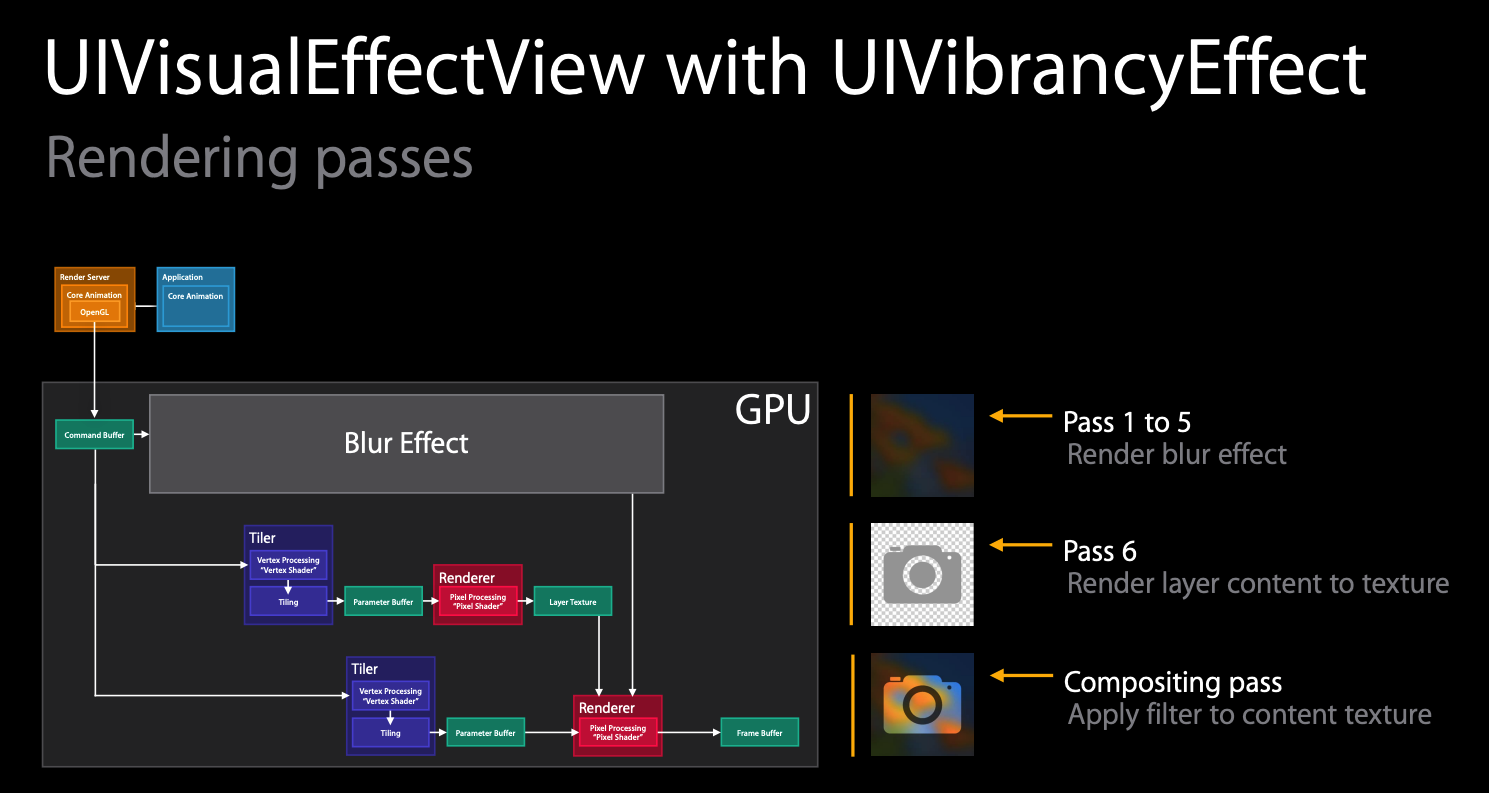
比 UIBlurEffect 多了两个步骤,最后一个步骤 filter 是最昂贵的,所以作用区域越小越好,千万别作用到全屏上。
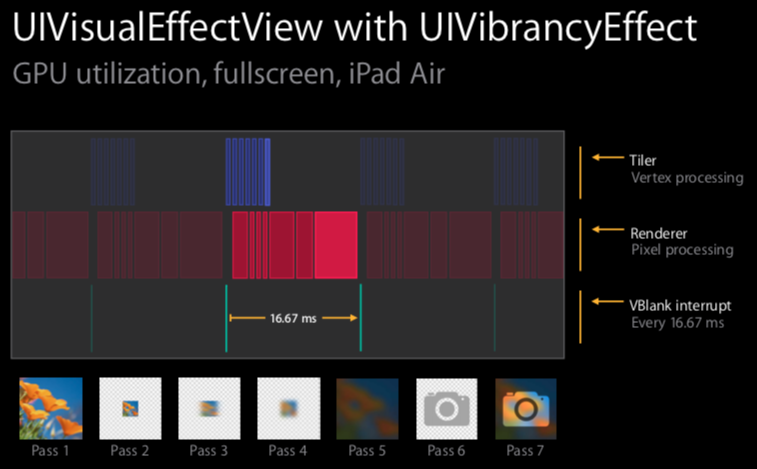
所以也会比 UIBlurEffect 多两个间隙,所以总共 0.6~1.2ms.

七、分析工具(Profiling tools)
7.1 性能关注点
性能调查要考虑以下点

- What is the frame rate? Goal is always 60 fps.
- 检查工具: Instrument — Core Animation template / OpenGL ES driver template
- CPU or GPU bound? Lower utilization is desired and saves battery.
- 更少的 CPU 或者 GPU 利用率,让电池更持久。
- 检查工具: Instrument — OpenGL ES driver template
- Any unnecessary CPU rendering? GPU is desirable but know when CPU makes sense.
- 得知道渲染什么和怎么渲染,
drawRect方法尽量少用,减少让 CPU 的工作,让 GPU 做更多的渲染。 - 检查工具: Instrument — Core Animation template / OpenGL ES driver template
- 得知道渲染什么和怎么渲染,
- Too many offscreen passes? Fewer is better.
- 前面说 UIBlurEffect 的时候有说到,橘色的间隙就是用在 GPU 切换时间,每个间隙大概 0.1~0.2ms 。 离屏渲染也会出现这样的情况,因为它必须进行切换,所以得减少。因为前面有提到,我们减少 CPU 或者 GPU 的使用时间。
- 检查工具: Instrument — Core Animation template
- Too much blending? less is better.
- GPU 处理 blending 合成的时候,操作昂贵,消耗性能
- 检查工具: Instrument — Core Animation template
- Any strange image formats or sizes? Avoida on-the-fly conversions or resizing.
- 会转给 CPU 去处理,增加 CPU 的负担
- 检查工具: Instrument — Core Animation template
- Any expensive views or effects? Understand the cost of what is in use.
- 避免昂贵的效果,例如 Blur 和 Vibrancy ,得去考量。
- 检查工具: Xcode view debugging
- Anything unexpected in the view hierarchy? Know the actual view hierarchy.
- 添加和移除要匹配。
- 检查工具: Xcode view debugging
7.2 检查工具
上面每个例子后面都有提到一个检测工具,这里来讲讲相应检测工具的作用。请注意一点,在开始挖掘代码以试图找出正在发生的事情之前,这总是一个很好的起点(先看大概发生什么问题,再深入研究代码)。
7.2.1 Core Animation template
- 看 fps
- color blended layers, green 表示不透明, red 代表需要去 blend 混合。 增加 GPU 的工作。 绿多红少,是理想中的状态。
- color hit screens and misses red, 展示如何使用或滥用 CALayer’rasterize 属性,没命中缓存就是红色。第一次启动会有很多红色,因为必须在它被缓存之前渲染一次,后面就没有了,因为缓存了。
- color copied images, 如果是 GPU 不支持的图片就会让 CPU 去转换(在 commit phase),增加了 CPU 的工作。 显示为蓝绿色(cyan)就表示让 CPU 去转换,影响滚动体验。 所以 size and color/image format 最好提前在后台处理好,不要阻塞主线程。
- color misaligned images, 黄色表示需要缩放,紫色表示像素没对齐。
- color offscreen-rendered yellow, 黄色代表离屏渲染。 nav bar 和 tool bar 是黄色,因为这些图层的模糊实际上模糊了它背后的内容(前面 blur 有讲过)。
- color OpenGL fast path blue, 蓝色是好事,由显示硬件去 blend ,这样就会减少 GPU 的工作。
- flash updated regions, 正在更新的部分为黄色。 理想状况下,黄色区域越少越好。它意味着 CPU 和 GPU 的工作都减少了。
7.2.2 OpenGL ES driver template
- device utilization, which will show you how much the GPU is in use during the trace. (使用率越少越好,这里举例的是 30% vs 70%(心中的理想值))
- render and tiler utilization, correspond to the renderer and tiler phases.
- CoreAnimationFramesPerSecond, what the actual frame rate is that we’re seeing.
7.2.3 Time Profiler template
- 看调用栈耗时,看 CPU 在干什么;
参考链接:
- Learn OpenGL (已fork,备丢)